





1. 서론
이 연구는 한국어의 의문 대명사가 통사적으로 복잡한 문장 속에서 어떤 운율 구조로 발화되는지 경북 방언을 중심으로 살펴보고, 설명 의문문(wh question)과 판정 의문문(yes-no question)의 운율 특징을 효과적으로 나타내 줄 수 있는 운율 단서(prosodic cue)가 무엇인지 알아보는 것을 목적으로 한다. 특히 의문사가 내포문(embedded sentence)에 위치할 때 작용역(wh- scope)에 따른 억양 차이를 보여주는 이전 연구에서 제시된 단서를 적용하여 검증하고, 그보다 효과적으로 작용역의 차이가 반영되어 나타나는 새로운 단서를 제시하고자 한다.
한국어의 의문 대명사는 부정 대명사와 어휘적으로 동일한 형태를 지니고 있어 중의적 문장이 나타날 수 있으며, 중의성의 해제는 일반적으로 문맥에 의하여 판단되어, 발화 시 서로 다른 운율 구조로 나타난다. 이미 Jun & Oh(1996)는 서울말에서 부정대명사를 사용한 판정 의문문과 의문사를 사용한 설명 의문문, 그리고 표면적인 의문사의 이동이 나타나지 않아 구별할 수 없는 반향 의문문(echo question)의 운율 차이를 발화와 인지 실험을 통해 보고하였다. 해당 논문은 판정 의문문의 경우 부정 대명사가 하나의 강세구(accentual phrase)를 이루는 반면, 설명 의문문과 반향 의문문은 의문사와 그 다음에 나오는 서술어 사이에 강세구 경계가 사라져 하나의 강세구를 이루는 차이점을 가장 큰 요인으로 보았다. 이에 주목해 본 연구는 단문(simple sentence)에서 나타나는 의문문의 운율 특징에서 벗어나, 복문(complex sentence)의 의문문일 경우 이전 연구에서 주장한 운율 특징이 경북 방언에도 동일하게 작동하는지 살펴보고, 이전 연구의 문제점을 찾아 새로운 방식으로 복문 의문문의 운율 특징을 설명하고자 한다.
2. 선행 연구
복문의 의문문의 운율을 살펴보기 전에 우선 통사적 관점에서 문장의 구조를 이해할 필요가 있다. 내포문에 의문사가 있을 경우 간접 의문문(indirect question)으로 해석될 수도 있고 또는 직접 의문문(direct question)으로 해석될 수도 있다. 이러한 해석상의 차이는 의문사의 작용역의 차이에 근거하는데, 의문사의 작용역이 내포문에 머물면 간접 의문문으로, 모문(matrix sentence)으로 확장되면 직접 의문문 형식의 설명 의문문으로 이해된다. 이러한 작용역의 확장은 모문의 서술어 종류와 관련이 되어 있는 것으로 알려져 있다. 한국어에서 소위 교량동사(bridge verb)라 일컫는 동사(예를 들어 ‘생각하다’)는 내포절에 포함된 의문사의 작용역이 내포문에 머무르지 않고 모문으로 확대되는 반면, ‘궁금하다’와 같은 동사는 섬 제약(wh-island constraint)현상을 일으켜 모문으로의 작용역이 통사적으로 허락되지 않는다(Hong, 2004).
이러한 중부 방언에서의 현상과는 달리 동남 방언에서는 다른 양상이 나타난다. 먼저 의문사와 연관되어 나타나는 의문형 종결 어미가 의문문의 종류에 따라 다르게 나타난다. 판정 의문문의 경우 ‘-나’를, 설명 의문문의 경우 ‘-노’가 나타나며 내포문의 의문사가 모문의 작용역을 가질 때에는 동사의 종류와 관계없이 ‘-노’를 사용한다(Suh, 1987). 표 1은 동남방언을 기준으로 작용역과 동사에 따른 예문을 제시하였다.
| 작용역 | 생각하다 | 궁금하다 |
|---|---|---|
| 모문 | 너는 영미가 누구를 좋아한다고 생각하노? | 너는 영미가 누구를 좋아하는지 궁금하노? |
| 내포문 | *너는 영미가 누구를 좋아한다고 생각하나? | 너는 영미가 누구를 좋아하는지 궁금하나? |
‘생각하다’의 경우 작용역은 모문이므로 내포문으로 작용역이 한정되는 간접 의문문이면서 판정 의문문으로의 해석은 중부, 동남방언 모두에서 불가하다. 전술했듯이, 중부 방언의 경우 모문의 작용역을 갖는 ‘궁금하다’의 예문은 통사적으로 불가한 반면 동남 방언에서는 통사적으로 가능한 것으로 알려져 있다. ‘-노’가 모문으로의 작용역 해석이 어떤 통사적 특징 또는 과정에 의해 이루어지는지에 대해서는 통사론 논문이 아닌 본고에서는 논외로 하고, 그러한 문장의 운율적 특징에 대한 선행 연구를 살펴보기로 한다.
Ishihara(2002, 2004)와 Deguchi & Kitagawa(2002)는 모문의 작용역을 가질 수 없는 통사적으로 불가능한 문장도 적절한 운율 형태로 발화될 경우 정문으로 이해될 수 있다고 주장하였다. 이에 대해 Hwang(2007)은 서울말과 경남 방언에서, Hwang(2006, 2011)도 경남 방언, Kubo(2005)와 Jung(2010)은 부산 출신 화자에서 ‘의문사 억양(wh-intonation)’을 통해 작용역이 표시된다고 보았다. 의문사 억양이란, 의문사의 어휘 강세(lexical pitch accent)를 시작으로 작용역이 표시되는 지점까지 나타나는 단어들의 기본 주파수(fundamental frequency, F0) 곡선에서 의문사 다음에 나타나는 단어들의 어휘 강세가 표시되지 않는 억양 형태를 말한다. 이는 두 가지로 나타날 수 있다. 즉, Tokyo Japanese에서와 같이 ‘저 평탄조(F0 compression or reduction)’로 나타나거나, Fukuoka Japanese와 경남 방언에서와 같이 ‘고 평탄조(high plateau or flat high tone)’를 이루는 방식으로 나타난다.
Hwang(2011)은 경남 방언에서 의문사의 어휘 강세(lexical pitch accent)가 상승조(rising)일 경우 고 평탄조, 하강조(falling)일 경우 저 평탄조로 나타난다고 주장하였다. 또 Hwang(2015)은 의문사의 작용역은 문맥이 주어지지 않을 경우 내포절로의 해석을 선호하지만 적절한 문맥이 주어질 경우 모문의 작용역으로 이해될 수 있다고 주장하였다. 특히 경남 방언에서 모문의 작용역으로 해석될 때 나타나는 의문사 억양의 두 가지 패턴, 즉 고 평탄조와 저 평탄조일 경우 각각에 대한 운율 특징을 기술하였다. 먼저 첫 번째로 고 평탄조일 경우 의문사 어구의 F0 정점(peak)에서 시작하여 모문 동사가 갖는 F0 정점까지 F0 곡선은 눈에 띄는 굴곡 없이 이어지는 반면, 내포절 작용역일 경우에는 내포문 동사의 F0 정점은 비슷하나 내포절 동사와 함께 나타나는 보문소(complementizer)인 ‘-지’의 F0가 모문 작용역일 때보다 낮게 형성되었다. 두 번째로 저 평탄조의 의문사 억양일 경우, 모문 작용역 의문사 어구의 F0 정점이 내포문 작용역 의문사 어구 F0 정점보다 높은 반면, 모문 동사의 F0 정점은 모문 작용역이 내포문 작용역일 경우 보다 더 낮게 나타났다. 그는 그 이유로 저 평탄조란 모문 동사의 F0 정점이 ‘압축(compression)’되어 나타나기 때문으로 보았다.
실험 음성학적 접근법으로 작용역에 따른 억양 패턴을 자세히 다루고 있는 Hwang(2015)의 연구가 경남 방언을 대상으로 이루어진 것과 대조적으로, 전통적인 방식으로 방언 사용자의 직관에 의존한 경북 방언 의문문 성조의 패턴 연구가 이미 보고되었다(Lee, 2001). 이 연구는 기존의 규칙 기반 음운론에 바탕을 두고, 설명 의문문에서 실현되는 성조 패턴을 두 가지로 나누어 설명하고 있다. 먼저 경북 영주로 대표되는 경북 북부 지역에서 ‘의문사 + 뒷성분’이 하나의 성조 어절로 결합하고 ‘뒷성분’의 길이는 무시되어 의문사의 성조 표시 이후의 모든 요소는 저조(L: low tone)로 나타난다. 둘째 대구를 중심으로 하는 경북 남부 지역은 의문사 ‘어데’, ‘머어’, ‘무슨’ 등 성조 기저형이 /HL/일 경우 ‘뒤 높은형’, 즉 [LnHL]형으로 나타난다. 추가적으로 동일 지역에서, ‘누구’, ‘몇’, ‘얼마’ 등 기저형이 /L/ 또는 /LL/일 경우 첫 번째 패턴이 일반적이나, 30대 이하의 젊은 세대에서는 ‘뒤 높은형’도 조사되었다고 보고하였다(Lee, 2001:31). 이러한 관찰은 Hwang(2015)의 것과 일치한다고 할 수 있다. 즉, 첫 번째 억양 패턴은 저 평탄조를 의미하며 ‘뒤 높은형’은 고 평탄조를 의미한다. 덧붙여 ‘뒤 높은형’이 경남 방언의 특징 확대이며 경북 북부로 확산중임을 주장하였다(Lee, 2001:35). 이와는 별개로, 경남과 경북 방언의 설명 의문문이 유형적 측면에서 차이를 보이지 않는다고 Kim(2005:118)은 주장하였다.
의문사 억양의 운율 특징을 조사한 이러한 연구들은 대부분 소수의 발화자를 대상으로 운율 구조의 특징 및 운율 단서를 알아보거나 전통적 방식의 연구라는 점에서 발화자를 확대하여 통계적으로 신뢰할 만한 크기의 실제 음성 자료로 연구할 경우 어떤 결과를 나타낼 지 예단하기 어렵다. 만약 Lee(2001)와 Kim(2005)의 주장처럼 경북 방언의 의문문 억양 패턴이 경남 방언과 유사하다면, Hwang(2015)에서 주장한 작용역에 따른 의문문 구분을 위한 네 가지 운율 단서, 즉 의문사 어구의 F0 정점, 내포 동사의 F0 정점, 보문소 ‘-지’의 F0, 그리고 모문 동사의 F0 정점도 경북 방언에 적용될 수 있을 것이다. 본 연구는 이러한 단서들의 경북 방언에 적용되는지를 확인하는 차원의 연구에서 더 나아가, 모문 작용역 의문문의 억양 유형과 상관없이 내포문 작용역 의문문과 구분할 수 있는 효과적인 운율 단서를 찾아보고자 한다. 비록 모문 작용역의 의문문에서 두 가지 형태의 의문사 억양을 보인다 하더라도 결과적으로 동일한 작용역을 나타내는 것이므로, 이와 내포문 작용역 의문문을 구분하는 운율 단서, 즉 두 가지 다른 형태의 의문사 억양에는 공통적 특징을 갖지만 내포문 작용역 의문문에서는 확연히 다르게 표현되는 운율 단서를 포착할 수 있다면, 이는 기존의 연구에서 주장한 독립적인 네 개의 단서보다 효과적인 작용역 구분 단서로 제시될 수 있을 것이다.
이와 함께, Hwang(2007)의 주장처럼 서울말에서도 작용역에 따른 의문문의 구분이 운율 구조의 차이로 가능한지 살펴보고자 한다. 이를 위해 본 연구의 경북 방언 자료에서 찾은 운율 단서를 적용하여 모문 작용역과 내포문 작용역 의문문이 구분되는지 살펴보고 이에 대한 추가적 논의를 덧붙이고자 한다. 그러나 본 연구의 주안점은 경북 방언을 대상으로 한 작용역 구분 운율 단서 추적임을 밝히며 이러한 점에 맞추어 실험을 진행하였다.
3. 실험 방법
서울, 안동, 대구에서 각각 남자 10명, 여자 10명, 총 60명의 인원이 참가하였다. 대부분 각 지역의 대학 또는 대학원에 다니는 20대에서 30대 연령의 참가자로 평균 연령은 23.9세, 표준편차 2.8세로 나타났다. 서울의 경우 피실험자 부모님의 고향이 경기권이며 현 거주지가 수도권인 경우에 실험에 참여하였다. 대구나 안동의 경우 화자를 해당 도시 출생으로만 국한하지는 않았다. 그러나 소수의 인원을 제외하고 대부분 해당 지역에서 크게 벗어나지 않는 곳에 생활 기반이 있는 화자들이 실험에 참여하였다. 대구 지역 화자 중 행정 구역 상 경남에 해당하는 울산, 진주 지역에서 각각 1, 2명의 인원이 포함되었다. 안동 지역에서 녹음한 화자 중에도 포항, 울산, 구미 등의 지역이 포함되었으나 경북 북부 지역의 화자들이 주를 이루고 있다. 이들에게 청각 및 말장애 이력은 모두 없는 것으로 보고되었다.
표 1이 제시한 세 개의 문장을 포함하여 추가적으로 4개의 문장이 실험에 사용되었다. 추가적인 4개의 문장은 먼저 의문사와 동일한 어휘 형태를 지니고 있는 부정 대명사의 ‘누구’가 들어간 문장으로 문맥 속에서 부정 대명사임을 인지할 수 있도록 하였다. 또한 부정 대명사에 나타나는 운율 특징을 비교하기 위해 명사를 추가하였다. 모문의 서술어로 표 1과 같이 ‘생각하다’와 ‘궁금하다’를 이용하였다. 표 2에 추가적 문장을 표시하면 다음과 같다.
| 종류 | 생각하다 | 궁금하다 |
|---|---|---|
| 부정 대명사 | 너는 영미가 누구를 좋아한다고 생각하나 | 너는 영미가 누구를 좋아하는지 궁금하나 |
| 명사 | 너는 영미가 민호를 좋아한다고 생각하나 | 너는 영미가 민호를 좋아하는지 궁금하나 |
‘너는 영미가 누구를 좋아하는지 궁금하노?’의 경우 문맥상 ‘궁금하노’보다 ‘궁금한 기고’가 더 잘 어울린다는 경북 방언 화자의 조언을 받아들여 교체하였고, 부정대명사와 ‘궁금하나’로 이루어진 문장은 내포문의 작용역을 갖는 문장과 동일한 형태를 갖기 때문에 추후 비교를 위해 부정대명사로 읽히는 문맥을 추가적으로 삽입하여 녹음하였다. 따라서 총 8개의 문장이 문맥과 함께 준비되었다. 중부 방언은 의문 종결어미를 ‘-니’와, ‘궁금한 기고’와 상응하는 ‘궁금한 거니’로 사용하였고, 모문의 주어인 ‘너는’을 대신하여 ‘니는’, ‘닌’, 내포문의 목적어인 ‘누구를’을 ‘누구’, ‘누굴’이라고 발화한 것도 동일하게 타당한 것으로 간주하였다.
문장은 총 960개(60명×2회×8개 문장)이나 이중 잘못된 수작업으로 목표 문장이 정확히 추출되지 않았거나, 녹음 시 소음 등의 문제로 인해 사용할 수 없는 7개의 문장을 제거해서 최종적으로는 953개의 문장이 사용되었다. 실험 문장의 종류는 총 8개이나 본고가 중점적으로 논의하고자 하는 문장은 ‘궁금하다’ 동사를 이용한 직접 의문문과 간접 의문문이다. 이 두 목표 문장의 문맥은 별도로 부록에 수록하였다. 참고로 이 연구에서 주로 사용되는 경북 화자들이 발화한 직접 의문문, 즉 모문 작용역 문장은 79개이며, 간접 의문문, 즉 내포문 작용역 문장은 80개이다.
8개의 문장을 순서 없이 섞은 두 종류의 대본을 준비하여 동수의 피실험자들에게 사용하였다. 피실험자는 녹음실에 도착하여 약 20분 동안 미리 한 종류의 대본을 보고 읽는 연습을 단독으로 시행하였다. 실험 주관자는 피실험자가 문맥에 대하여 질문을 할 때 내용에 대하여만 설명하고, 목표 문장(target sentence)을 대신 소리 내어 읽거나 하지 않았다. 20분의 시간 동안 묵독이 아닌 낮은 목소리로 연극 대본을 읽듯이 연습할 수 있도록 지도하였다.
연습 시간이 지난 후 충분한 연습을 했는지, 문맥을 숙지했는지에 대해 확인하고 1차 녹음을 실시하였다. 녹음은 목표 문장을 포함한 모든 문맥을 대화체에 맞게 자연스럽게 소리 내어 읽도록 하였다. 1차 녹음 후 약 5분간 휴식 후 다시 한 번 동일한 대본으로 2차 녹음을 실시하였다. 1, 2차 녹음 도중 피실험자가 잘못된 운율로 읽었다고 스스로 판단할 경우, 단어의 발음이 잘못되거나 더듬거려 자연스럽지 않은 경우 해당 부분의 문장부터 다시 읽도록 하여 최대한 자연스럽게 발화한 것을 녹음하였다.
녹음은 서울, 안동, 대구에서 각각 진행되었으며 서울은 방음부스, 안동과 대구는 방송 녹음실에서 녹음하였다. 서울과 대구는 오디오 인터페이스(audio interface)에 연결된 데스크톱 컴퓨터(서울) 또는 노트북 컴퓨터(대구)를 사용하였고 안동에서는 휴대용 디지털 녹음기(TASCAM DR 100MKⅢ)를 사용하였다. 녹음 장소와 관계없이 마이크는 모두 AKG사의 C 520 콘덴서 마이크를 사용하였으며, 표본화 주파수(sampling rate) 44,100 Hz, 양자화(quantization) 16 bit로 AD(analog to digital) 변환하여 저장하였다.
문맥과 함께 녹음된 목표 문장은 먼저 프랏(Praat)을 이용하여 목표 문장에 해당하는 부분을 찾고, 그 문장의 시작과 종료 부분 앞, 뒤로 적당한 묵음(silence) 부분을 확보하여 수작업으로 레이블링 하였다(Boersma & Weenink, 2020). 해당 부분의 레이블은 목표 문장의 번호이며, 프랏 스크립트(script)를 이용하여 목표 문장 번호가 있는 부분의 음파만을 잘라내어 별도의 이름으로 저장하였다. 저장 시, 화자의 식별 번호와 지역, 성별 그리고 목표 문장의 번호 등, 추후 통계 처리에 필요한 정보를 추출할 수 있도록 파일명에 나타내었다.
각각의 목표 문장은 다시 프랏을 사용하여 어절별로 수동 레이블링(manual labelling)이 실시되었고, 남성의 발화는 75-300 Hz, 여성 발화의 경우 100–500 Hz로 피치 범위(pitch range)를 정하여 전체 문장에 대한 피치 값을 구한 파일을 별도로 저장하였다. 이와 함께 음의 강도(intensity) 또한 전체 문장에 대하여 값을 구하고 별도의 파일에 저장하여 강도 값이 일정 수준 아래(표준화 된 강도 값 0.3 미만)로 내려가는 곳의 피치 값을 제거하는 데 사용하였다.
Jun et al.(2006)은 경북 방언의 운율 특징을 하나의 운율 단어(prosodic word)가 H*+L 패턴을 가지고 있으며 운율 단어의 시작 경계에는 %L로 시작하는 경계 억양(boundary tone)으로 나타난다고 보았다. 의문사의 H*를 의문사가 나타나는 어절의 F0 정점으로 상정하고, 목표 문장을 이루는 각 어절에서 F0 정점이 나타나는 시간 정보와 F0 값을 별도 저장한 피치 값 파일로부터 자동으로 구하고, 그 어절 오른쪽 끝 지점에서 가장 가깝게 계산된 F0 값과 시간 정보도 함께 동일한 방식으로 구하였다. 이와 더불어, 이미 구해 놓은 각 어절의 F0 정점과 해당 어절 오른쪽 끝 지점의 F0 값의 차이를 내어 한 어절 내에서 F0의 변동 폭을 계산하였다. 만약 이 값이 크다면 해당 어절의 F0 변동 폭이 크다고 할 수 있고, 다른 어절에 비해 돋들림(prominence) 현상이 있을 것으로 예상할 수 있다.
다수의 피실험자가 참여하고 남, 녀 간의 F0 차이를 보정하기 위하여 문장마다 모든 피치 정보를 표준화하여 원 F0 값(raw F0 value) 이외, 표준화 된 값을 함께 계산하여 저장하였다. F0와 관련된 정보는 프랏과 파이썬(Python) 스크립트를 통해 자동으로 구하고 F0 값의 차이나 표준화 처리는 통계 프로그램인 R을 사용하였다(R Core Team, 2020). 통계 검증이나 그래프에서 별도의 언급이 없는 한 모두 표준화된 F0 값을 사용하였다.
실험 결과에서 사용될 통계 방법에 대한 전반적인 내용에 대하여 설명하자면, 먼저 종속 변수로는 발화된 각 문장의 억양 곡선을 이루는 F0를 표준화한 값을 일반적으로 사용하였다. 그 외 추가적인 종속 변수는 새로운 운율 단서로 제시하게 될 어절의 F0 변동 폭이다. 독립 변수로는 모문, 내포문 이렇게 두 개로 구분되는 작용역 변수와, 운율 단서들이 측정되는 위치가 사용되었다. 다시 말해서 운율 단서가 측정되는 위치에 따라 작용역의 구분이 통계적으로 유효한지에 대한 검증이라 할 수 있다.
독립 변수들의 교호 작용 등을 살펴보기 위해 반복측정분산분석(Repeated measures ANOVA)을 사용하였다. 분산분석을 시도하는 이유에 대하여는 4.1에서 다시 설명할 예정이며, 분산분석을 위한 가정 중 등분산 조건 충족여부를 판단하기 위하여 Levene’s test를 먼저 실시하였다. 일반적으로 p>0.05이면 등분산 조건이 충족되었다고 볼 수 있으나, 이러한 기준을 조금 느슨하게 하여 p>0.01일 경우에도 모수통계인 분산분석을 실시하였다. 등분산 조건을 완화하였으므로 이상값(outliers)을 제거할 경우 등분산 조건의 일반적 기준에 근접하는지 살펴보고자 하였고 이에 대한 내용을 4.4에 기술하였다.
4. 실험 결과 및 논의
이미 선행 연구에서 살펴본 바와 같이, 경북 방언도 경남 방언과 매우 유사한 형태의 억양 패턴을 가지고 있을 것으로 가정하고, 먼저 상자 그림을 통하여 전반적으로 우세하게 나타나는 것으로 여겨지는 억양 패턴을 중심으로 자료 분석을 시도하였다. Hwang(2015)에서 보고된 단서들을 이용한 통계 분석 결과를 제시하고, 이를 바탕으로 의문사 억양의 종류와 관계없이 작용역을 구분할 수 있는 새로운 운율 단서를 제시해 보고자 한다.
경남 방언을 대상으로 한 Hwang(2015)에서는 위의 선행연구에서 이미 언급한 바와 같이, 모문의 작용역을 가진 문장의 의문사 억양이 고 평탄조 또는 저 평탄조의 두 가지 형태로 나타나므로, 이를 분리하여 내포문 작용역을 가진 의문문의 운율 특징과 비교하였다. 해당 연구는 단지 4명의 화자만을 대상으로 한 것으로, 고 평탄조와 저 평탄조로 나타나는 문장을 직접 판별하여 나누어서 각각 분석이 진행된 것으로 보인다.
그러나 Hwang(2015) 본인도 지적했듯이 화자는 내포문 작용역의 해석을 선호하며, 비록 문맥이 주어졌다 하더라도, 또 ‘-노’라는 설명 의문문 종결 어미가 사용되었다 하더라도, 화자들은 알려진 의문사 억양으로만 발화하지는 않는다. 그렇다고 이런 발화들이 모문의 작용역 의문문으로 절대로 이해될 수 없다고 말할 수는 없다. 보고된 경북 방언의 전형적인 어투에서 어느 정도 벗어났다 하더라도 이를 함께 분석하는 게 필요하다고 할 것이다. 이러한 발화들은 고 평탄조와 저 평탄조로 정확하게 나타난 자료에 비하면 일종의 불량 자료(noisy data)라고 할 수 있으나, 이를 포함하여 작용역에 따른 운율 특징 구분을 정확히 해낼 수 있는 단서가 있다면 그것은 매우 결정이고도 효과적일 것이다.
따라서 모문의 작용역으로 읽히는 문맥에서 발화된 모든 분석 대상 문장을 의문사 억양의 종류나 정도와 상관없이 함께 분석하기 위해 우선 각 어절의 F0 정점을 상자그림(box plot)으로 그림 1에, 그리고 내포문 작용역을 갖는 문장을 동일한 방식으로 그림 2에 나타내었다.
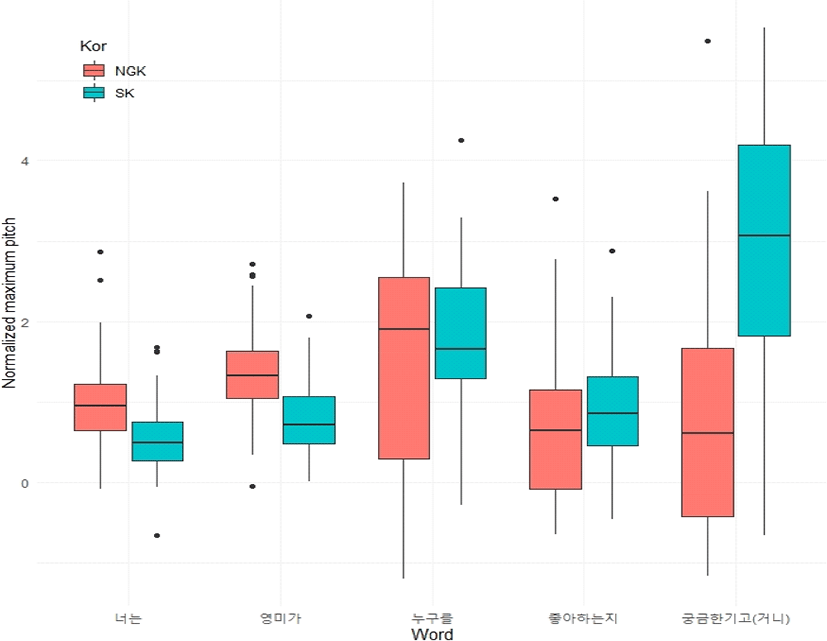
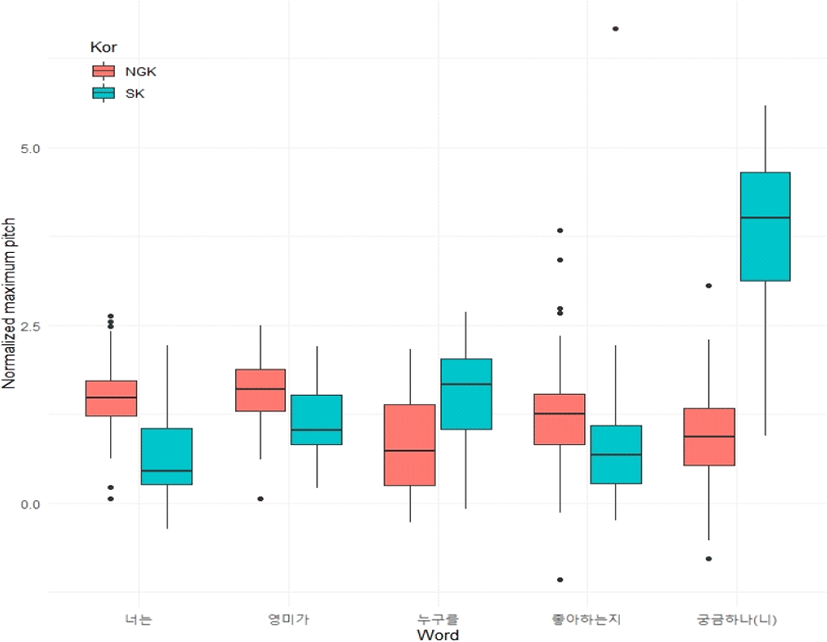
그림 1은 Hwang(2015)에서 저 평탄조 실현의 특징과 유사성을 보여주고 있다. 즉, 중앙값을 기준으로 볼 때, 모문 작용역 의문사 어구의 F0 정점이 내포문 작용역 의문사 어구에 나타난 F0 정점보다 더 높은 값을 갖는 것으로 보이며, 또한 모문 동사가 갖는 F0 정점을 비교해 볼 때, 모문 작용역에서 더 낮은 F0 정점이 관찰된다. 그러나 그 정도가 매우 크다고 보기에는 무리가 있다.
Hwang(2015)에서와 같이 좀 더 명확한 평균값과의 비교를 위해 의문사 어구의 F0 정점과 모문 동사의 F0 정점의 평균값과, 표준 편차(standard deviation)를 범위로 하는 F0 평균 분포를 그림 3에 나타내었으며, 이는 Hwang(2015:49)에서 보여준 그림과 매우 유사하다. 다만 Hwang(2015)에서는 평균 F0 만을 표시할 뿐, 어느 정도의 편차를 보이는지에 대해 나타내지 않았다. 동일 논문에서 경남 방언과 동일한 실험 설계에 바탕을 둔 Tokyo Japanese 대상 의문사 어구 F0 정점 비교에서 모문 작용역의 경우 의문사 어구 F0 정점이 더 높게, 내포문 작용역의 경우 더 낮게 나타난다는 것이 대응표본 t-검정(paired t-test)으로 유의미하게 나타났다. 그러나 모문 동사의 F0 정점 비교에서는 4명 대상자 중 2명에서 작용역의 차이에 따른 F0 정점 간 차이가 나타나지 않았다고 보고하였다. 경남 방언의 경우, Tokyo Japanese에서 분명하지 않았던 모문 동사의 F0 정점이 확연한 차이를 작용역 차이에 의해 보여주고 있다고 하였으나 토큰의 수가 제한적이라 통계적 검증은 시행하지 않았다고 기술하고 있다(Hwang, 2015:48).
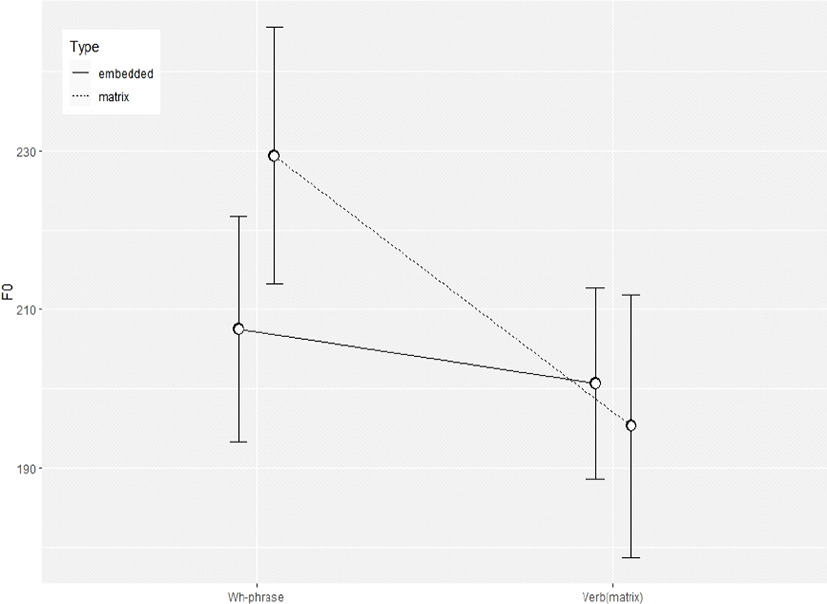
Hwang(2015)은 비록 경남 방언 자료로 통계 검증을 하지 않았으나, Tokyo Japanese의 통계 분석을 통해서 검증의 타당성을 판단해 볼 때, 통계 방법에 문제점이 있어 보인다. 통계적으로 타당한 분석 방법은 F0 정점 값이라는 종속 변수가 두 개의 독립 변수인 측정 지점과 작용역 범위에 따라 일관되게 설명 가능한가를 살펴보는 것이어야 한다. 아울러 두 변수 사이의 교호 작용(interaction)을 통해 두 독립 변수 간의 관계를 관찰할 수 있어야 한다. 그림 3에서도 알 수 있듯이 모문 작용역의 의문사 어구 F0 정점은 높지만 모문 동사 F0 정점 값은 항상 일관되게 낮게 나타나야 할 당위성이 존재한다. 왜냐하면 저 평탄조로 발화되었다는 전제가 있기 때문이다. 따라서 이러한 두 변수 사이의 관계를 검증하는 방식으로 통계 분석 방법을 사용해야 한다.
위의 그림 3이 실제 통계적으로 차이가 있는지 알아보기 위하여 교호 작용을 포함한 반복측정분산분석을 실시하였다. 먼저 등분산 조건의 충족 요건을 알아보기 위하여 Levene’s Test 시행 결과 F(3, 314)=12.509, p<0.0001로 등분산 요건을 충족하지 못하였다. 여기 사용된 F0 값은 모두 문장 단위로 표준화 된 값이므로 다시 원 자료를 사용하여 등분산 조건의 충족 여부를 점검한 결과 F(3, 314)=1.9422, p=0.1227로 조건을 충족하였다. 참고로 그림 3도 원 자료를 이용하여 나타내었다. 원 자료를 사용하였으므로 남, 녀 간의 확연한 F0의 차이가 나타날 것이므로, 성을 분리하여 각각 반복측정분산분석을 실시하였다. 남성의 자료에서 작용역에 따른 효과는 나타나지 않았다[F(1, 40)= 0.034, p=0.854]. 위치에 따른 효과는 유효하였으며[F(1, 40)= 22.6, p<0.0001], 교호 작용도 나타났다[F(1, 40)=22.3, p<0.0001]. 이와는 대조적으로 여성의 자료에서는 작용역 간 차이가 나타나는 결과를 보여주었다[F(1, 37)=11.3, p=0.002], 그러나 측정 위치에서의 효과나 교호 작용은 나타나지 않았다[F(1, 37)= 0.567, p=0.456, F(1, 37)=1.76, p=0.193]. 비록 여성의 자료에서 작용역 간 차이가 나타난다고 하더라도 전체 자료에서 유효하지 않기 때문에 저 평탄조의 특징을 나타내는 자료라고 할 수 없다.
이러한 결과는 아마도 분석 자료에 고 평탄조의 발화가 다량 혼재되어 가져온 결과라 예상할 수 있다. 다시 말해서, 고 평탄조의 발화가 다수 포함된 자료라면 저 평탄조의 특성이 확연하게 나타나지 않을 수 있을 것이다. 만약 고 평탄조 특성이 통계적으로 유의미한 결과를 가져온다면 경북 방언의 의문사 억양은 주로 고 평탄조로 발화된다고 말할 수 있을 것이다. 이러한 가설을 고려하여 고 평탄조 의문사 억양이 실제 자료에서 확연히 나타나는지 분석을 통하여 확인해 볼 필요가 있다.
고 평탄조란 의문사 어구에서 F0가 상승하여 의문사 어구의 끝 부근에서 F0 정점이 나타나고, 뒤이어 이렇게 상승한 F0는 유지되어 내포문 동사와 보문소를 지나다가 모문 동사의 마지막 의문문 종결 어미에서 하락하게 되는 모양을 말한다. 경남 방언에서 나타난 고 평탄조의 특징은 내포문 동사 어절의 F0 정점 값에서 모문 작용역과 내포문 작용역 간의 차이가 잘 나타나지 않으나, 내포문 동사의 보문소에 해당하는 ‘-지’의 F0에서 작용역 간 차이가 나타난다고 Hwang(2015)은 주장하였다. 즉 모문 작용역일 경우, 내포문의 보문소인 ‘-지’의 F0가 낮아지지 않는 반면, 내포문 작용역일 경우 ‘-지’에서 낮아져 운율 경계가 형성된다는 것이다. 운율 경계가 형성되기 때문에 뒤따라 나오는 모문 동사는 다시 어휘 강세에 의해 F0 정점이 형성되고 마지막 종결 어미에 경계 운율(L%)이 나타난다고 보았다.
본 연구에서도 동일한 방식으로 작용역이 구분될 수 있는지 살펴보기 위하여 내포문 동사의 F0 정점과 Hwang(2015)에서 ‘Valley’라 불렀던 내포문의 보문소 ‘-지’의 F0 값을 비교하여 그림 4에 나타내었다. 엄밀히 말하자면, 이 연구에서 ‘-지’의 F0는 ‘좋아하는지’ 어절의 오른쪽 경계에서 가장 가깝게 계산되어 나타난 F0 값을 의미한다.
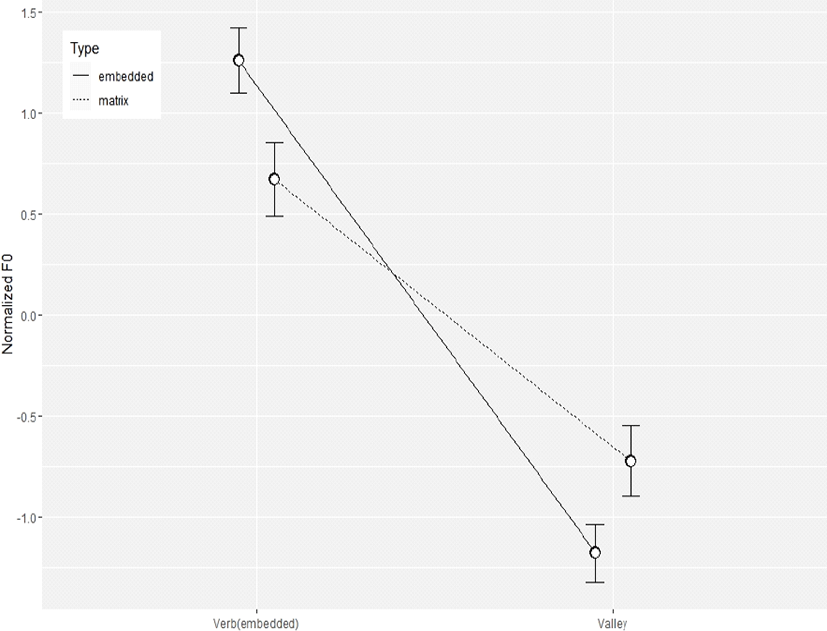
그림 4는 Hwang(2015:47)의 분석과 달리 비록 통계적으로는 유의미하지 않으나 내포문 동사의 F0 정점이 작용역에 따라 차이를 보이고 있다. 그러나 차이가 있다고 보고된 보문소 F0 값은 여전히 내포문 작용역 문장에서 더 낮게 형성되어 있음을 알 수 있다. Hwang(2015:47)에 나타난 고 평탄조 문장 대상 t-검정 결과에 따르면, 내포문 동사 F0 정점에서 작용역에 따른 통계적 유의성은 발견되지 않았고, 보문소의 F0 값만이 통계적으로 유의미한 차이를 보인다고 보고하였다.
저 평탄조에서와 마찬가지로 반복측정분산분석을 실시하였으나 저 평탄조에서와는 달리 내포문 동사에서 작용역에 따른 차이가 보고되지 않았기 때문에 이것과 연계되어 보문소에서의 작용역별 F0 차이가 일어난다고 볼 수 없다. 따라서 교호 작용이 일어나야할 당위성이 없으므로 주 효과만을 분석하였다. 등분산 가정을 점검하는 Levene’s Test에서 F(1, 314)=2.6334, p=0.05를 나타내었다.
F0의 측정 위치(내포문 동사, 보문소 ‘-지’)에 따른 주 효과는 F(1, 78)=469.617, p<0.0001로 나타났으나, 작용역에 따른 차이는 보이지 않았다[F(1, 78)=0.638, p=0.427]. 측정 위치에 대한 주 효과가 나타난 것은 당연한 결과이다. 왜냐하면 내포문 동사라는 하나의 어절에서 F0 정점은 같은 어절에 있는 보문소 ‘-지’의 F0보다 당연히 클 수밖에 없기 때문이다. Hwang(2015)의 주장처럼 보문소 위치의 F0가 작용역에 따라 크게 차이가 나타난다면, 분산분석에서 작용역에 따른 주 효과가 나타나야 한다. 비록 측정 위치에 따라 차이가 나타나지 않거나(내포문 동사) 나타날지라도(보문소), 작용역에 대한 주 효과의 검증 결과는 유의미해야 한다. 그러나 본 연구의 분석 자료에서는 이러한 특징이 나타나지 않았다.
그림 3과 그림 4는 Hwang(2015)이 제시한 그래프와 매우 큰 유사성을 보이고 있으나 통계적으로는 작용역 간 차이를 구분하지 못하고 있다. 그 이유에 대하여 다음과 같은 몇 가지 추론이 가능할 것이다. 첫째, 본 연구의 분석 자료가 모문 작용역에 나타나는 고 평탄조와 저 평탄조가 함께 포함되어 있으므로, 어느 한 쪽의 패턴이 우세하게 점유하지 않은 결과라고 할 수 있다. 비록 그림 1을 통하여 저 평탄조의 우세를 가정하였으나, 통계 검증 결과는 어느 패턴의 우세를 말하기 어렵다고 볼 수 있다. 둘째, 본 연구의 분석 자료가 경남 방언에서 나타나는 저 평탄조도 고 평탄조도 아닌 다수의 제 3의 의문사 억양 패턴이 존재할지 모른다는 의심을 할 수 있다. 셋째, 완전히 무작위 억양 패턴의 존재도 의심해 볼 수 있다.
그러나 전술했듯이, 김문규(2001)에 따라 일반적인 경북 방언에서의 의문문 억양 패턴은 고 평탄조와 저 평탄조의 형태이므로, 두 번째와 세 번째의 가정은 가능성이 낮아 보인다. 그렇다면 실제 억양의 다양한 패턴을 관찰해보고, 고 평탄조와 저 평탄조의 혼재 속에서도 작용역을 구분해 줄 수 있는 새로운 운율 단서를 찾아 본 연구의 분석 자료를 정확하게 설명할 필요성이 제기된다고 할 수 있다.
지금까지의 분석으로 판단한다면 현재 논의 중인 발화 자료에 확연한 의문사 억양 특징이 나타나지 않는다고 할 수 있다. 좀 더 정확한 분석을 위하여 실제 발화된 각 문장의 F0 변화를 그림 5와 그림 6에 나타내었다.

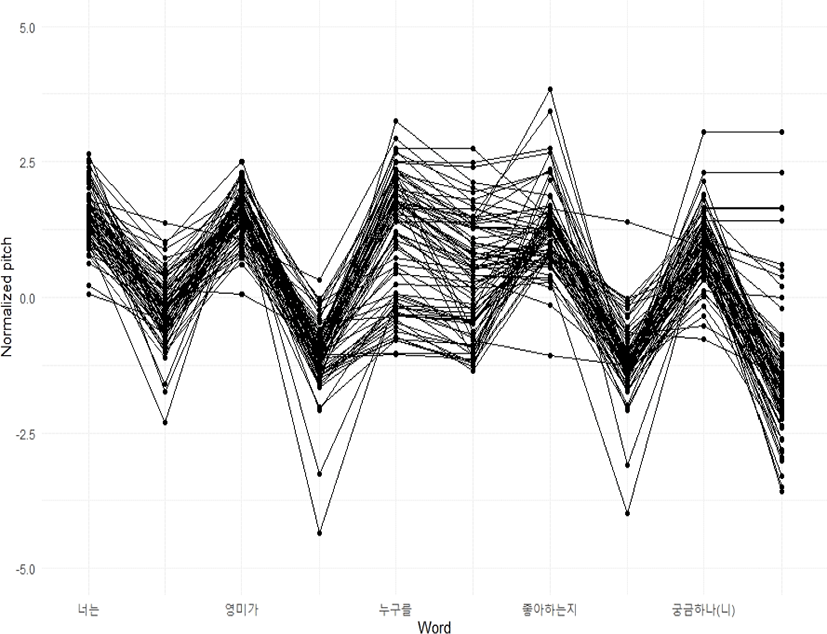
그림 5와 그림 6은 각 어절의 F0 정점과 어절 말의 F0를 연결하여 가장 중요하게 보이는 F0의 변화를 단순화하여 표현한 것이다. 한 어절의 F0 정점에서 그 어절 오른쪽 끝에서 측정된 F0 값의 연결선이 수평으로 나타난다면, 그것은 해당 어절의 가장 높은 F0와 어절 끝 F0가 동일 값이라는 것을 의미한다. 다시 말해서, 어절 말에서 가장 높은 F0 정점을 이루었다는 의미이다.
그림 5는 모문 작용역을 읽은 자료이므로 정상적인 발화라면 의문사 억양이 기대되는 자료이다. 저 평탄조라면 ‘누구를’에서 높아지고 ‘-를’과 ‘좋아하는’은 의문사 어구보다 상당하게 낮아져야 하고 다시 보문소 ‘-지’는 ‘좋아하는’과 큰 차이를 보이지 않아야 한다. 이와 함께 마지막 ‘궁금한 기고’는 이전 어절의 F0정점과 유사한 정도의 높이를 가져야 한다. 고 평탄조라면 의문사 어구의 F0 정점이 저 평탄조에서보다 비교적 낮게 형성되고 ‘-를’과 뒤이은 ‘좋아하는지’의 F0는 의문사 어구의 F0 정점보다 다소 높게 또는 비슷한 높이로 나타나다가 마지막 ‘-고’ 부분에서 하강하는 모습을 보여야 한다. 그러나 그림 5에는 이러한 두 가지 패턴만을 가지고 있지 않고 정형화 할 수 없는 다양한 패턴이 존재한다. 전술했듯이, 모문의 작용역 해석보다는 내포문 작용역 해석이 선호되기 때문에 그림 6에서 보이는 패턴의 F0 변화도 찾아볼 수 있다. 반면, 내포문 작용역인 그림 6은 ‘좋아하는지’에서 상승과 하강이 뚜렷이 나타나는 패턴을 보여준다.
그렇다면 의문사 억양과 내포문 작용역 문장의 억양을 구분하는 가장 큰 특징, 즉 어떤 형태의 의문사 억양이라 할지라도 동일하게 나타나고, 내포문 작용역일 경우 다르게 나타나는 단서가 무엇이 있을 수 있는지 살펴볼 필요가 있다. 이전 연구에서와 같이 의문사 억양을 고 평탄조, 저 평탄조로 나누어 설명하고 또 다른 단서가 내포문 작용역 억양에서 작동한다고 보기보다는 공통적으로 접근할 수 있는 하나의 단서로 특징을 설명하는 것이 효과적이라 할 수 있을 것이다.
좀 더 깊이 있는 분석에 앞서, 먼저 모문의 작용역 발화는 여러 가지 패턴이 존재한다는 것을 주지해야 할 필요가 있다. 이런 점을 고려하여 관찰하면, 그림 5와 그림 6의 가장 크게 눈에 띄는 특징은 내포문 동사와 보문소로 이루어진 부분의 F0 변화라고 할 수 있다. 다시 말해서, 그림 6에서는 내포문 동사의 F0 정점에서 ‘-지’로의 급격한 F0 변화가 있는 반면, 그림 5에서는 내포문 동사의 F0 정점 자체가 아주 높게 형성되지 않아 ‘-지’의 F0와 아주 큰 차이를 보이지는 않는다는 것이다. 물론 큰 차이를 보이는 경우도 있으나 이미 다양한 패턴이 존재함을 고려할 때 어느 정도 타당한 관찰로 이해될 수 있다.
내포문 동사의 F0 정점에서 보문소 끝의 F0의 차이가 중요한 하나의 단서를 제공할 수 있다는 전제 하에, 그 앞에 나오는 의문사 어구와 모문 동사 어구도 함께, 각 어절의 F0 정점에서 그 어절의 오른쪽 끝 F0 값을 뺀 변동 폭을 구하고 한 문장에서 나타나는 변동 폭의 움직임을 모문 작용역일 경우 그림 7에, 내포문 작용역일 경우 그림 8에 나타내었다. 그림 5와 그림 6과 마찬가지로 연결선은 동일 문장의 발화에 나타나는 F0 변동 폭의 추이를 보여주는 것이다. 그림 7에 비하여 그림 8에는 비교적 선명한 다수의 이동 선을 관찰할 수 있다.
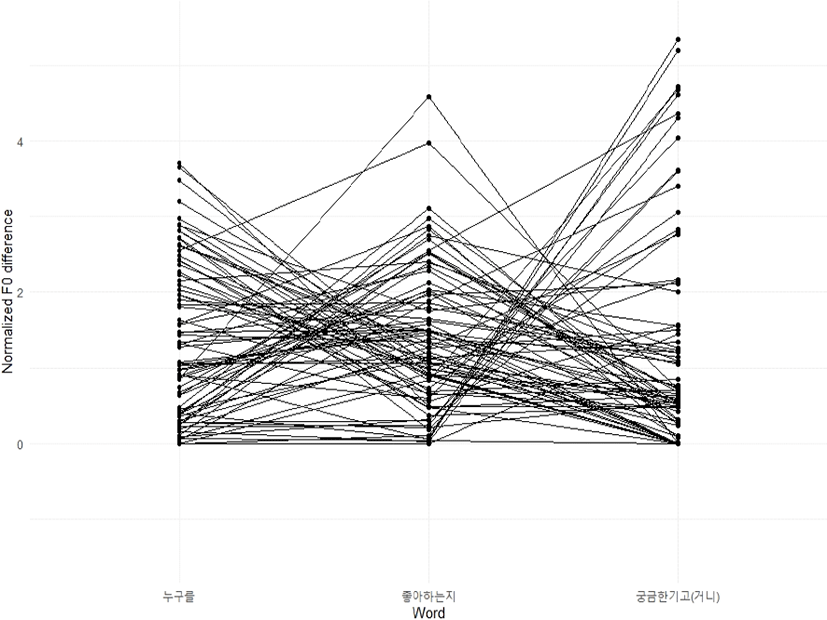
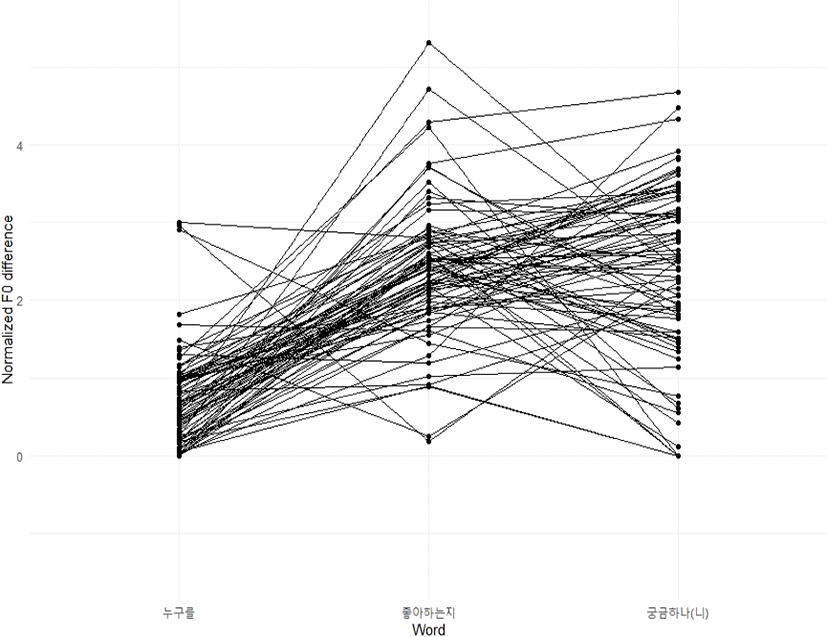
내포문 작용역의 경우 ‘누구를’의 F0 정점과 어절 끝 부분의 F0의 차이보다도 ‘좋아하는지’에서 ‘-지’로의 하강이 매우 크다는 것을 나타내고 그런 패턴을 갖는 발화가 다수라는 것을 알 수 있다. 또한 ‘-지’에서 F0가 하강했기 때문에 모문 동사에서의 변동 폭도 크게 나타난다는 것을 알 수 있다. 왜냐하면 보문소에서 F0가 낮아져 운율 경계가 발생하고, 다시 모문 동사의 어휘 강세가 나타난 후 동남 방언의 의문문 어말 억양 특징인 L%가 억양구(intonational phrase)로 나타나기 때문이다.
그에 반하여 모문 작용역인 그림 7은 몇 가지 패턴으로 요약할 수 있을 것이다. 먼저 의문사 어구 ‘누구를’에서 큰 변동 폭이 나타나고 ‘좋아하는지’에서는 그것보다 조금 적은 변동 폭이, 마지막 ‘궁금한 기고’에서는 더 적은 변동 폭으로 연결되는 선들을 관찰할 수 있다. 이는 전형적인 저 평탄조의 발화로 해석 가능할 것이다. 또한 다수는 아니지만 ‘누구를’에서 비교적 낮은 변동 폭을 보이고, ‘좋아하는지’에서도 거의 비슷한 수준의 변동 폭을 보였다가, ‘궁금한 기고’에서 큰 변동 폭을 보이는 연결선들의 패턴을 발견할 수 있다. 이것은 전형적인 고 평탄조로 읽힌다. 고 평탄조에서는 마지막 모문 동사의 종결 어미에서 F0 하락이 있으므로 모문 동사 어구의 F0 변동 폭은 다소 크게 나타날 수밖에 없다.
위에 주된 패턴으로 관찰된 것 이외에도 다양한 패턴들이 있다. 가령 의문사 어구의 변동 폭은 매우 작았다가 ‘좋아하는지’에서는 큰 차이를 보이고 다시 ‘궁금한 기고’에서 매우 적은 변동 폭을 나타내는 패턴도 보인다. 이런 패턴은 내포문 동사가 크게 강조되는 발화로 읽히나 다수의 패턴이라고 하기는 어렵다. 다수로 나타나는 패턴을 제외한 다른 형식들이 어떤 경우에 많이 나타나는지는 후속 연구에서 밝히기로 하고, 이 연구에서는 이 세 구역에서의 F0 정점과 어절 끝의 F0 차이를 중심으로 통계 분석을 시도하였다.
의문사 억양이 나타나는 그림 7의 고, 저 평탄조로 읽히는 특징과 내포문 작용역의 그림 8에서 나타나는 특징을 통계적으로 시각화하기 위하여 평균과 ±1 표준 편차를 범위로 하는 분포를 세 지점에 연결하여 그림 9에 나타내었다. Hwang(2015)에 따라 분석한 그림 3에 비하여 각 지점에서의 차이는 물론 작용역에 따른 구분도 쉽게 이루어지는 것으로 확인된다. 무엇보다도 고 평탄조와 저 평탄조를 서로 다른 단서로 비교하지 않고 하나의 단서 즉, 각 어절의 F0 변동 폭으로 구분을 할 수 있다는 점에서 좀 더 효과적인 단서라고 할 수 있을 것이다.
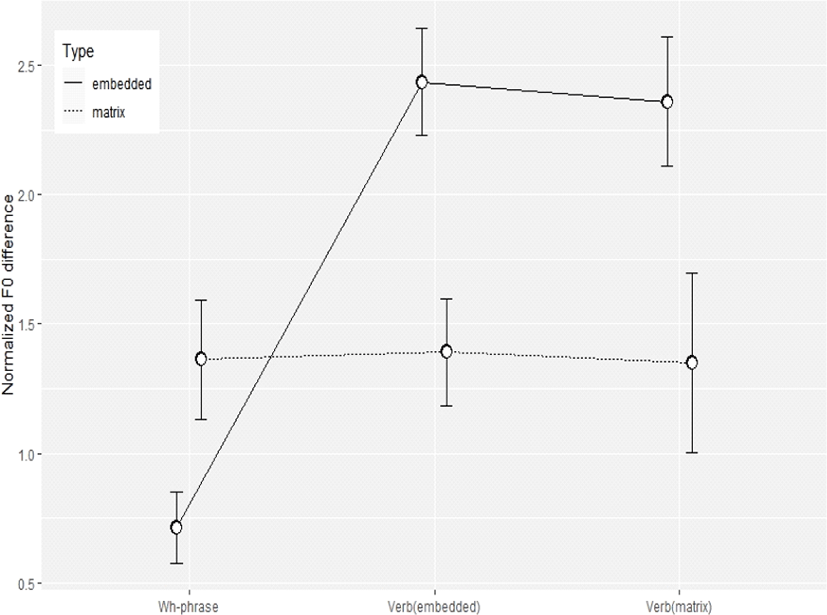
좀 더 자세히 보면, 내포문 동사와 모문 동사에서의 작용역별 F0 변동 폭은 대체로 확연히 나타나는 반면, 의문사 어구의 F0 변동 폭은 작용역별 차이도 다른 위치에서보다 적고 무엇보다도 다른 위치에서와는 정반대로, 모문 작용역에서 더 큰 변동 폭을, 내포문 작용역에서 더 작은 변동 폭을 보여주고 있다. 그림 8의 의문사 어구 F0 변동 폭이 대체로 낮게 시작하는 패턴을 보여주는 것과는 달리, 그림 7의 것은 패턴을 특정할 수 없게 변동 폭이 나타나고 있다. 이런 점에서 의문사 어구 F0 변동 폭은 작용역에 따라 변화한다고 보기 어렵다. 따라서 의문사 어구를 제외하고 다시 그래프를 그려 그림 10을 얻고 이에 대한 통계 분석을 시도하였다.
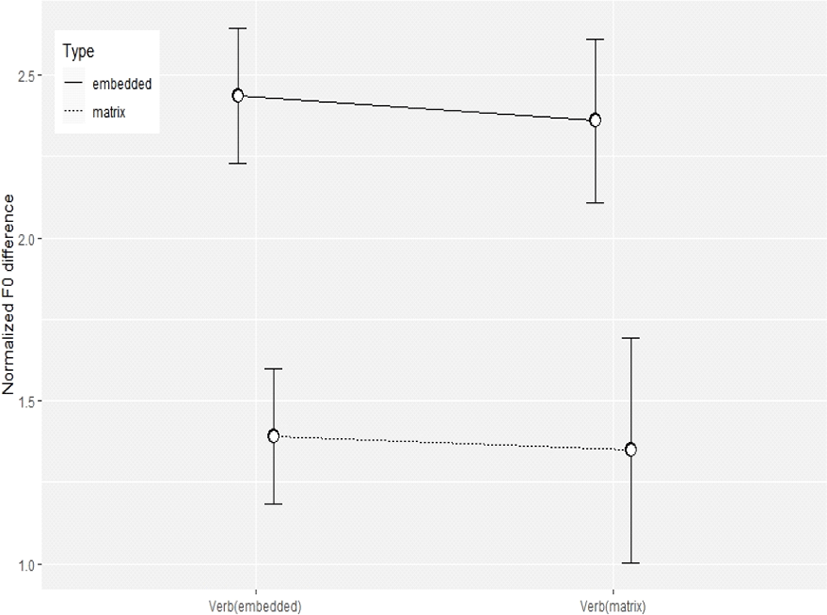
Levene’s test 결과는 F(3, 314)=3.627, p=0.01338이며 반복측정분산분석의 결과는 작용역에 따른 주 효과만 통계적으로 유의미하게 나타났다[F(1, 78)=83.13, p<0.0001]. 동사 위치나 두 독립 변수의 교호 작용은 각각 F(1, 78)=0.2869, p=0.717, F(1, 78)=0.003, p=0.958로 위의 그림 10에서 유추할만한 수준의 결과를 보여주었다.
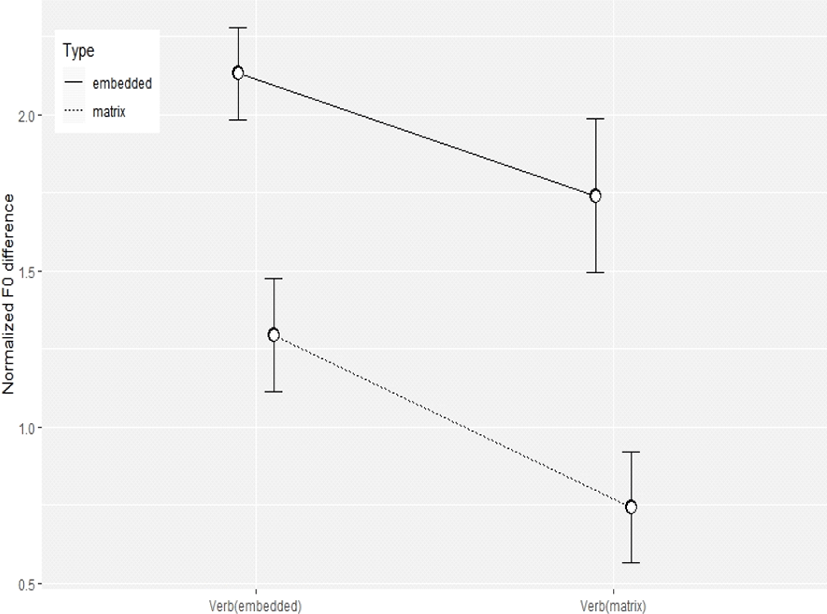
완화된 등분산 조건을 좀 더 강화하여 모수 통계의 신뢰성을 확보하기 위한 목적으로 이상값(outliers)을 제거하고 Levene’s test를 실시하였다. Levene’s test 결과 F(3, 257)=3.4609, p=0.01696으로 57개의 이상값 토큰을 잃고 0.003의 p값 상승을 가져왔다. 여전히 일반적인 수준에서의 등분산 조건을 만족한다고 할 수 없으나, 이전 통계 결과와의 비교 목적, 다시 말해서 만약 어떤 이유에서건 자료에 존재하는 설명하기 어려운 이상값을 제거한 경우 이전 통계 결과와 어떻게 달라지는지 확인하고자 다시 반복측정분산분석을 실시하였다. 결과적으로 두 가지 주 효과는 통계적으로 유의미했으며[동사 위치 F(1, 67)=20.678, p<0.0001, 작용역 (F(1, 70)=132.808, p<0.0001)], 교호 효과는 나타나지 않았다[F(1, 38)=2.846, p=0.0998)]. 257개의 자료로 다시 그림 10과 같은 그래프를 나타내면 그림 11과 같다. 이상값을 제거할 경우 위치나 작용역에서 모두 확연한 특징을 발견하게 된다는 점에서 이 단서가 매우 적절하게 작용역에 따른 운율 특징을 설명해 주는 것이라 말할 수 있다. 그럼에도 불구하고 여전히 완화된 등분산 조건을 사용하였다는 점을 결과에 나타난 유의 확률에 감안할 필요가 있음을 밝힌다.
경북 방언에서의 작용역별 특징을 잘 설명해 주는 내포 동사와 모문 동사의 F0 변동 폭이 서울말에도 적용되는지 살펴보았다. 경북 방언과는 억양 패턴의 차이가 있기 때문에 의문사 어구를 포함하여 그림 9와 같은 방식으로 변동 폭을 나타내었다. 그림 12는 경북 방언에서와는 달리 작용역별 차이가 잘 나타나지 않고 다만 모문 동사에서 F0 변동 폭이 약간의 차이를 보인다. 통계 검증을 위한 Levene’s Test 시행 결과 F(5, 231)=2.6448, p=0.0239를 보여주었으며 이원분산분석에서는 예상대로 위치별 차이는 유의미하나[F(2, 77)=26.673, p<0.0001], 작용역별 차이는 나타나지 않았다[F(1, 38)=3.332, p=0.0758].
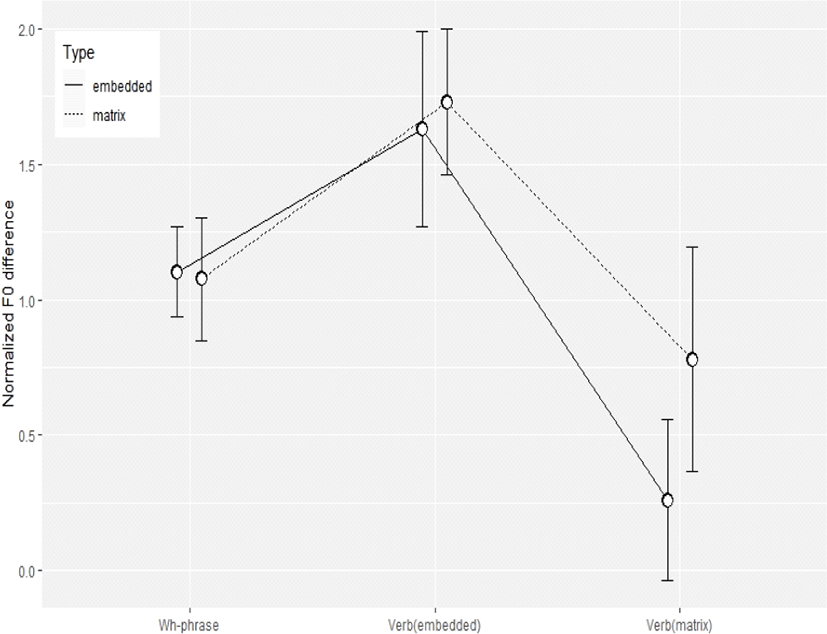
서울말의 경우 의문문 종결 어미의 전형적인 억양구 패턴이 부가 의문문일 경우 H%로 나타나고, 설명 의문문일 경우 H%, HL% 보다 LH% 형태로 실현되는 경우가 많다고 Jun & Oh(1996)은 주장하였다. 그러나 위의 그래프로 판단해볼 때, 모문 작용역일 경우가 더 큰 F0 변화를 보여주고 있다. 이는 모문 동사 내부에 F0 정점이 종결 어미에 나타나는 억양구의 LH%보다 더 높기 때문인 것으로 보인다. 그렇다면 설명 의문문의 경우 HL%가 더 전형적인 형식으로 볼 수 있을 것이다. 그럼에도 불구하고 서울말 화자들은 통계적으로 작용역에 따른 의문문 구분이 억양을 통해 실현된다고 할 수 없다. 다만 몇몇의 화자들에서 모문 동사의 종결 어미 발화시 설명 의문문의 전형적인 억양구 패턴을 이용하여 전체 문장이 설명 의문문인 것을 나타내려 했다고 짐작해 볼 수 있다.
경북 방언과 서울말의 가장 큰 차이는 내포문 동사에서의 F0 변동 폭이라 할 수 있다. 서울말에서 경북 방언과 유사한 패턴의 의문사 억양이 나타나지 않는 한, 의문사 어구에서 보문소까지의 F0 곡선은 내포문 작용역이나 모문 작용역이 차이가 나지 않는 것으로 보인다. 다만 통계적으로 유의미하지 않으나, 몇몇 화자들은 모문 동사와 종결 어미 발화를 통해 작용역을 구분하려는 시도를 하는 것으로 해석할 여지가 있다.
5. 결론
이 연구는 경북 방언에서 내포문에 존재하는 의문 대명사가 두 가지 작용역으로 의미를 나타낼 때 작용역에 따른 운율 특징이 서로 어떻게 다른지 효과적으로 설명할 수 있는 단서에 대하여 살펴보았다. Hwang(2015)은 의문사 어구, 모문 동사, 내포 동사 각각의 F0 정점과 보문소의 F0 값이 경남 방언에서 유효한 작용역 구분 단서로 제시하였으나 이 연구에서는 이러한 단서들이 통계적인 유의미성을 확보하지 못함을 밝히고 새로운 단서를 제시하여 두 작용역에 따른 특징이 확연히 구분될 수 있음을 보여주었다.
이전 연구는 모문 작용역에 나타나는 의문사 억양 패턴, 즉 고 평탄조와 저 평탄조를 나누어 각각 내포문 작용역 의문문과 비교하는 이중적 비교 방법이었다면, 이 연구는 하나의 단서만 사용하여 모문과 내포문 작용역을 특징지어 구분할 수 있는 방법을 제시하였다. 내포문 동사 내의 F0 정점과 보문소의 F0 값의 차이, 즉 해당 어절 내 F0 변동 폭은, 내포문 작용역일 경우 모문 작용역일 때보다도 큰 차이를 보여주었다. 이는 고 평탄조나 저 평탄조의 경우에도 동일하게 나타나는 단서로 작용역에 따른 비교를 단순하고 효과적으로 할 수 있게 해 주었다.
경북 방언에서의 작용역 간 차이를 나타내는 운율 단서를 서울말에 적용해 보았으나 만족스러운 결과를 얻지 못했다. 다만 모문 작용역의 문장에서 의문 종결 어미에 나타나는 억양구 패턴을 HL%로 발현함으로써 모문 작용역을 갖는 설명 의문문임을 나타내려 한 시도를 읽을 수 있었다. 그러나 이러한 가정을 통계적으로 뒷받침할 수 없었다. 아마도 경북 방언과 달리 문미 경계 억양만을 가지고 작용역을 구분하는 것으로 추측되나 이를 증명하기 위해서는 추후 별도의 연구가 필요할 것으로 보인다.