





1. Introduction
Existing research recognizes the critical role played by prosodic structure in understanding sound patterns in languages (Cho & McQueen 2005; de Jong 1995, 2004; de Jong & Zawaydeh, 2002; Fougeron & Keating, 1997; Turk & Shattuck-Hufnagel, 2007). The prosodic structure has been concerned with those elements of speech that mark boundaries of prosodic constituents (e.g., Intonational Phrase, Accentual Phrase) and prominence in the utterances (e.g., driven by new information as compared to given information). Depending on where in the prosodic structure phonemes occur, the same phonemes would be phonetically differently produced, such that those segments that occur in phrase-initial positions (vs. phrase-medial positions) or those occurring with prominence (vs. without prominence) would be realized with spatial and/or temporal expansions.
It has been further documented that the prominence-induced strengthening is not uniform across languages but conditioned by language-specific sound system (e.g., Cho & McQueen, 2005; de Jong, 1995, 2004; de Jong & Zawaydeh, 2002; Kim et al., 2018). For instance, it has been shown that voice onset times (VOTs) are not uniformly lengthened in prosodically strong positions but rather they are modulated in language-specific ways, such that voiceless stops in Dutch are produced with shortened VOTs when the stops were under prominence while English voiceless stops showed lengthened VOTs under prominence (Cho & McQueen, 2005; Kim et al., 2018).
In the present study, we explore how Korean lenis and aspirated stops in word-medial positions would be realized as a function of prominence, to increase our understanding of prominence-induced strengthening by including the new target stops. To date, research on the prominence effects on Korean stops has tended to focus on stops in word- and phrase-initial positions. Kang & Guion (2008), for instance, showed that young speakers increased F0 for the word- and phrase-initial lenis and aspirated stops in clear speech (i.e., foreigner-directed speech) as compared to those in conversational speech. Choi et al. (2020) also showed higher F0, as well as longer VOT, for the word- and phrase-initial lenis and aspirated stops when the stops were focused than when they were not. Note that in both studies, the aspirated and lenis stops differed in the degree to which their F0 and VOT values were manipulated by clear or focused speech, and as a result, for instance, the F0 distance between the stops became larger in clear and focused speech than in convertsational and unfocused speech, respectively.
There has been, however, very little research directly investigating prominence effects on intervocalic word-medial lenis and aspirated stops, although acoustic realizations of stop consonants substantially differ between in the intervocalic word-medial positions and in the word- and phrase-initial positions. In terms of VOT, for instance, the word-medial intervocalic lenis stops are likely to be produced as voiced, a phenomenon known as Intervocalic Lenis Stop Voicing (Jun, 1993), while the lenis stops in the word- and phrase-initial positions are voiceless. Regarding F0, high tones vs. low tones are categorically assigned to the word- and phrase-initial aspirated vs. lenis stops respectively by the intonational phonology (Jun, 1993, 1998, 2000), while in the word- medial (and thus not phrase-initial) positions there are no such tonal specifications that the intonational phonology categorically assigns as a function of whether it is an aspirated or lenis stop.
Given the substantial differences in F0 and VOT realizations of stops depending on the positions, in the present study, we explore how acoustic realizations of the word-medial intervocalic lenis and aspirated stops would be modulated by prominence. Along with the manipulations of the prominence, we compare male and female speakers to see whether and how the phonetic realizations for the stops may differ as a function of speakers’ gender. A number of studies have demonstrated gender differences in VOT and F0 for lenis versus aspirated stops in word- and phrase-initial positions, with larger VOT and smaller F0 distances between the stops for males than females (Bang et al., 2018; Choi et al., 2020; Kang, 2014). Thus, to see whether there would be any gender differences for the word-medial intervocalic stops as well, we collect data from both female and male speakers.
2. Methods
A total of 16 native speakers of Seoul Korean participated in the recording (age 19–24 years, mean=22 years at the time of testing, 8 females). All had been born and raised in Seoul or Gyeonggi province (the area surrounding Seoul). The participants were not aware of the purpose of the study and were paid for the participation. The acoustic data were recorded at a sampling rate of 44 kHz, using a Tascam Hd-P2 digital recorder and a SHURE KSN44 microphone, in a sound attenuated booth at Hanyang Institute for Phonetics and Cognitive Science of Language, Seoul.
The tested contrast was a Korean aspirated vs. lenis stop contrast in alveolar place of articulations (/th/vs./t/). The following vowel was always low vowel /a/. A total of eight minimal pairs of disyllabic words were prepared, with the contrastive syllables occurring in word-internal positions (see Table 1 for all minimal pairs).
The test words were then included in sentences such that the focus types (focus vs. no focus) could be manipulated. Example sets of sentences bearing a test word /pithan/(grief) are given in Table 2. Each set consisted of question and answer sentences.
To induce the intended prosodic structure as naturally as possible, we created a board game situation in which a participant conversed about where to put word cards. In this game, participants were first shown a correct answer picture on a computer screen. After that, they were presented with a pre-recorded question of where to put the word card, and then answered the question according to the answer picture (Figure 1). The questions were recorded by four speakers. The participants heard one of the four versions of each question, with an equal number of each version.
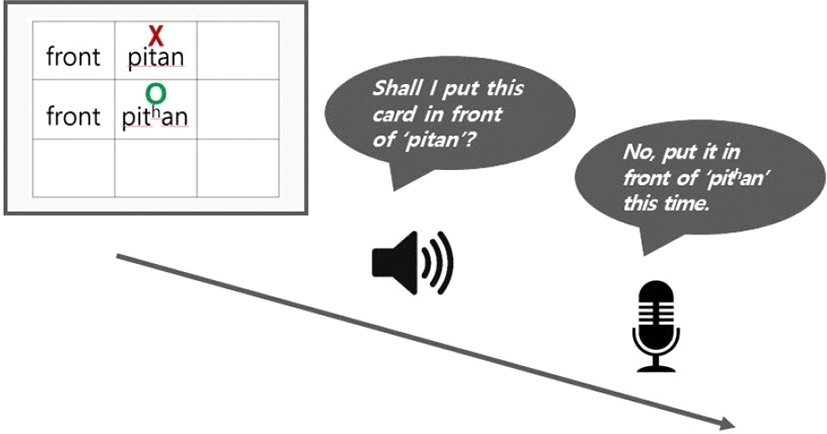
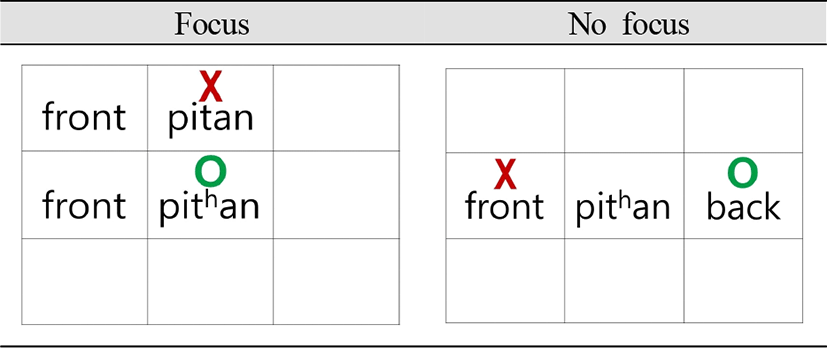
For the focus condition, for instance, the participants were given the answer picture as in Figure 2. The picture showed that the spot where the word card should be placed is not in front of /pitan/ (silk) as indicated by a red cross but in front of /pithan/(grief) as indicated by a green circle. Then the participants were presented with the pre-recorded question, “Shall I place this card in front of /pitan/ (silk)?” in which the wrong place was uttered with focus. The participant was then asked to answer the question by correcting the wrong information as in “No, put it in front of /pithan/(grief) this time.” As the correct answer (/pithan/(grief)) differed from the word to be corrected (/pitan/ (silk)) only in terms of the phonation types of the target stops (/t/ vs. /th/), a contrast focus on the phonation-type contrast was induced. For the no-focus condition, the locus of information to be corrected was not the test word but direction (front vs. back) (see Figure 2), so that the test word was not focused. With respect to the phrase boundary, an IP-initial boundary was induced by having the adverb /ipʌnen/ (this time) just before the test word. The participants in facts placed the IP boundary between the adverb and the test word without difficulty.
Prior to actual recording, the practice session was carried out. Only during the practice, the question and answer sentences were presented along with the answer pictures; during the actual recording, the sentences were not provided to help induce more spontaneous speech by preventing reading the written sentences. The entire test set was repeated two times in a randomized order. A total of 1,024 tokens (16 speakers×16 target words×2 focus types×2 repetitions) were obtained.
F0 was measured at the midpoint (50%) of vowels following the target stops. We first used a Praat script (range of 65–500 Hz; time step of 10 ms) and then manually checked based on visual inspection of the pitch contour for each token. The F0 measurements in Hz were converted into semitones (St) using the formula 12[log2(Hz/100)] with a reference F0 of 100 Hz.
VOTs of target stops were measured from the stop release to the voice onset of the following vowel defined as the onset of first formant (F1) seen in spectrograms. To examine whether and to what extent focus may affect degree of voicing during the stop closure (especially for lenis stops given the aforementioned lenis voicing rule), we calculated the percentage of the voiced interval (i.e., negative VOT) during the closure duration (%-Voicing, henceforth).
3. Results
A total of 29 tokens (2.8% of data) that were realized with inadequate prosodic patterns or that were difficult to measure acoustic parameters were discarded for analysis. Analysis was carried out in R (R Development Core Team, 2008) using linear mixed-effects models for each acoustic measure (F0, %-Voicing, VOT). Using sum contrast, Stop (0.5: aspirated, –0.5: lenis), Focus (0.5: focus, –0.5: no focus) and Gender (0.5: female, –0.5: male) were coded1. The factors were included as fixed effects along with all interactions. The models included the maximal random effects structure supported by the data. Table 3 provides all fixed effect coefficients along with model formulae.
There were significant main effects of Stop (β=1.1, p<.05) and Focus (β=5.7, p<.001), indicating that F0 was higher for aspirated than lenis stops and higher for focus than no-focus conditions (Figure 3). Not surprisingly, F0 was significantly higher for female than male speakers as well (β=11.4, p<.001). No interaction effects were observed.
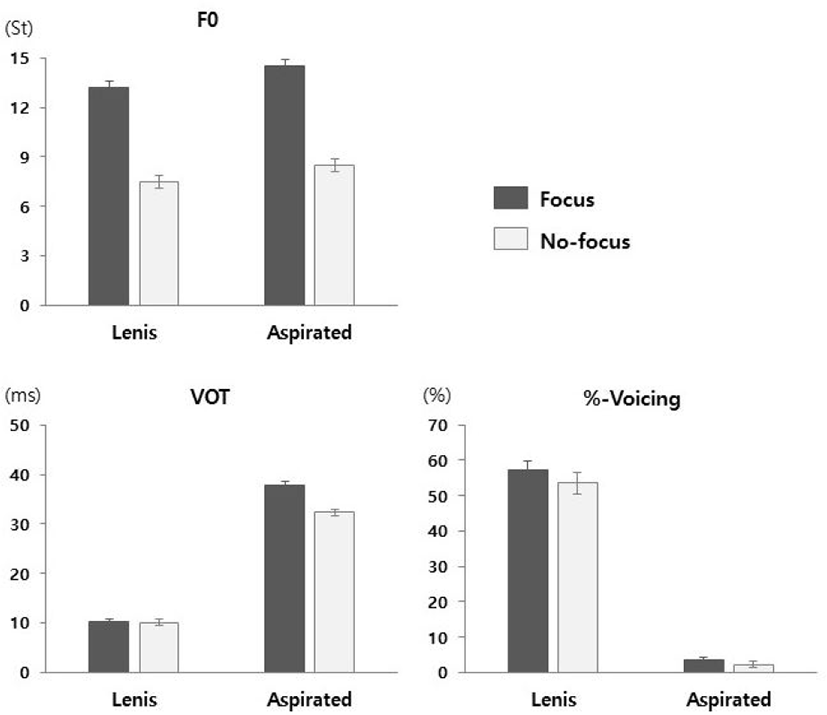
There was a significant main effect of Stop (β=24.9, p<.001), showing that VOT was longer for aspirated stops than lenis stops (Figure 3). Although VOT was numerically lengthened under focus especially for aspirated stops (5.4 ms; lenis stops = 0.1 ms), there was neither a s main effect of Focus nor interactions including Stop and Focus. Other effects were also non-significant.
We first checked how many tokens of lenis and aspirated stops were realized as voiced. Following the suggestion by Abramson & Whalen (2017), we counted tokens as voiced if there was voicing in more than 50% of the closure. As shown in Table 4, overall, over half of lenis stops were realized as voiced, and the proportion of being voiced for the lenis stops was higher for male than female speakers (83% vs. 41%). For the aspirated stops, almost none of the tokens were counted as voiced across all conditions.
Turning to results from the mixed-effects model on %-Voicing, a significant main effect of Stop was observed (β=−52.2, p<.001), indicating greater %-Voicing for lenis than aspirate stops (Figure 3). A main effect of Gender (β=−11.1, p<.05) and an interaction between Gender and Stop (β=21.0, p<.001) were also significant, showing that overall, %-Voicing was higher for the male speakers than female speakers but the %-Voicing difference between male and female speakers was reduced for the aspirated stops (0.6%, –0.6= –11.1+21.0×(0.5)) as compared to the lenis stops (21.6%, –21.6= –11.1+21.0×(–0.5)) by 21%. All the effects involving Focus were not significant.
4. Discussion and Conclusion
In the present study, we explored how word-internal intervocalic aspirated and lenis stops in Seoul Korean would be differently realized as a function of focused vs. unfocused conditions, together with whether and how the phonetic realizations of the stop contrasts would vary by speakers’ gender. Several findings emerged from the study, which are summarized and discussed as follows.
First, our results showed that F0 of the vowels following the aspirated and lenis stops became higher under focus than no-focus conditions. The focus effect of increasing F0 is consistent with Yun (2013) which found higher F0 for intervocalic lenis stops when phrases with the lenis stops in the phrase-medial positions were focused than when not focused. It has been also reported that F0 for both aspirated and lenis stops in word- and phrase-initial positions became higher with focus than without focus (Choi et al., 2020), demonstrating the similar focus effects on F0 between for the word-medial intervocalic stops and for the word- and phrase-initial stops.
Unlike F0, we did not find any robust focus effects on VOT and %-Voicing for both aspirated and lenis stops. The finding again accords with that of Yun (2013) who also found no focus effect on VOT for the intervocalic lenis stops. Studies on word- and phrase-initial stops, however, demonstrated lengthened VOT under focus. For instance, Cho et al. (2011) examined word-initial aspirated stops as a function of focus and showed that VOT of the stops became longer when the stops were focused than when they were not. In Kang & Guion (2008), the effects of speaking style (clear vs. conversational speech) were exploited for word- and phrase-initial aspirated and lenis stops, and their results also showed longer VOT in clear than conversational speech for the aspirated stops. That is, our finding with no clear focus effects on VOT differs from earlier studies on word- and phrase-initial stops, showing dissimilar focus effects on stops depending of their positions.
Finally, our results showed that male speakers produced the intervocalic lenis stops as voiced more often than female speakers, indicating a greater degree of lenition for males than females. This finding is consistent with that of Sohn & Ahn (2011) who found the greater percentage of reduction in VOT from word-initial to word-medial lenis stops for males than for females. They interpreted the finding as evidence demonstrating that male speakers are more prone to the weakening process in the intervocalic positions than females.
To conclude, this study has shown the focus effects on word-medial intervocalic aspirated and lenis stops, which differ from those of the stops in word- and phrase-initial positions. The findings add to the growing body of research that shows the varied patterns of prominence-induced strengthening, and suggest that it may be important to take into account the environments where phonemes occur to fully understand prominence-related phonetic modulation.