





1. Introduction
In daily conversation, speakers unconsciously imitate what they perceive even in the midst of speaking. Their speech production is aligned to their arrangement of articulatory strategy when they listen to another person’s speech stream. Research on imitation have been combined with studies on listeners’ perceptions. Notably, the attention of perception and imitation were contributed to the field related to categorical perception (Liberman et al., 1956; Flege & Eefting, 1988; Shockley et al., 2004; Alivuotila et al., 2007; Honorof et al., 2011). Speech production, including its connection to the perception of the spoken language, has been perceived as being different from tightness, which is a combination of imitation and perception. Shockley et al. (2004) showed how different productions are acceptable for scaling imitation in their AXB experiment. For example, they proposed that when VOTs were shortened, speakers’ imitations were less productive than were their production-based skills. Alivuotila et al. (2007) investigated Finnish open vowels as they relate to imitation and perception, and their research showed that Finnish children and adults perceived categories that were distinct from each other. In that study, the perceptual category boundaries of children’s imitation corresponded to their imitative responses, whereas adults’ responses were not relevant to the Finnish open vowel contrasts.
The tightness of production in imitation can pursue categorical states which are then represented in speech. The imitative forms that are drawn from selective sounds help children acquire native phonetic forms. Children’s language skills are defined by their spoken language. The categorical distinction from children’s imitative responses have been observed from previous literature (Leonardo et al., 1978; Kent, 1979; Kent & Forner, 1979; Kuhl & Meltzoff, 1996). Kent (1979) examined how imitative skills compare between non- English and English vowels, and found adults and children are distinctive in the way they produce vowels; this distinction shows up in systematic clusters. In a developmental study, Kent & Forner (1979) examined synthesized vowel imitation differences between men, women, and children, and proposed vowel formation scales. Kuhl & Meltzoff (1996) investigated vocal imitation and developmental sequences in babies at ages 12, 16, and 20 weeks. The result of this research has shown that the vowels /a – i – u/ were distinguished at 20 weeks. That is, the vowels’ categories were more tightly clustered at 20 weeks than at 16 weeks, and more tightly clustered at 16 weeks than at 12 weeks.
Production and perception are the first factors in communication when speakers have a tight speech connection. Speech perception researchers have examined categorical characteristics in various speech materials. However, little attention has been paid to categorization and production using imitative methods. The relationship between categorical perception and categorical production appear through speakers’ communication; their individual speech categorization influences the process of language development. Pierrehumbert & Steele (1989) revealed that, for individualized imitations from English intonation contrast, they observed categorical boundaries in pitch contour for some speakers. All of the speakers presented in that paper showed unique patterns of categorical distinction in English pitch accent contrasts. Spring & Dale (1977) supported the idea that one- to four-month-old infants distinguish prosodic units using a fundamental frequency-based approach. The fundamental frequency in the system of a pitch accent language comes out in infants’ range of imitation and production.
North Kyungsang Korean, a lexical pitch accent dialect, has been assessed in previous works (Kim, 1988; Kim, 1997; Kim, 2012, 2014); this dialect is primarily spoken in the south-east region of South Korea. Certain pitch forms (e.g., [ka.ka.ka.ka]: HLHL, “is he/she the person?”) represent informal conversation in this dialect. A four-syllabic word consisting of [k] and [a] conveys a semantic information, assigning high-low pitch accents. Additionally, there are minimal pairs with distinctive meanings using pitch accent contrasts: for example, [kaci]: HL, “kind,” [kaci]: LH, “eggplant,” and [kaci]: HH, “branch”. Kim (1988) and Kim (1997) both employed a phonological approach that triggered a theoretic-based analysis. Kim (2012, 2014) worked experimentally, focusing on imitation, showing categorical or continuous aspects of the pitch accent contrasts. The development of the pitch accents of the North Kyungsang dialect have been assessed through the imitation method looking at spoken language from children to adults. The present paper is focused on a North Kyungsang dialect which has been observed as having a lexical pitch accent.
The purpose of this work is to describe the distribution of imitation and production represented by North Kyungsang speakers. The present study will consider the degree of similarity in the imitation and production work for categorical production.
2. Method
In the present study, nine subjects were involved with an imitation task and nine with a production task. Their ages ranged from 20 to 29. All subjects were recruited from Daegu, which is a central city in the region of North Kyungsang. No subject had any experience of living outside of Daegu, and there were no reported problems in hearing and speaking ability. They were paid volunteers.
North Kyungsang spoken words were presented for subjects in an experimental setting. The spoken words included three pitch accent contrasts.
[mo.i] HL: “feed,” LH: “conspiracy”
[mo.ɾe] HL: “sand,” HH: “the day after tomorrow”
[yaŋ.mo] LH: “wool,” HH: “adoptive mother”
These North Kyungsang Korean spoken words were produced in a consistent form as in (1), (2), and (3) for the experiment. In the production task, the spoken words in (1), (2), and (3) were recorded within six carrier sentences; for example, [yəŋmi-ka moi hako malhes-nɨnteye] “Youngmi said feed/conspiracy.” The three pitch accent minimal pairs were then excerpted from the carrier sentences. For the imitation task, the target words in the production task were resynthesized from the scale of pitch contour shape. This manipulation was conducted using Praat, a pitch-synchronous overlap and the addition of (PSOLA) algorithms, which created a range of pitch accent patterns. In other words, the pitch accents of HL and LH were divided as scales that were used as the unit of fundamental frequency. The clusters of scales for HL and those of LH formed two categories in the processes of manipulations. HH-HL and HH-LH were also divided using the PSOLA algorithms. The resynthesized lexical pitch accent items were scaled from the ones which were the endpoints of the minimal pairs as shown in <Figure 1>.
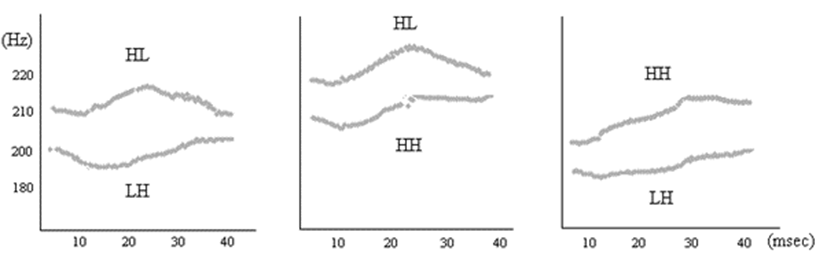
For the imitation task, the subjects were instructed to pronounce what they heard from headphone equipped. They were given practice repeating words from their native dialect, and then they imitated what they could based on what they paid attention to. The imitation task included 432 trials (i.e., 6 blocks × 72 trials).
The experimental words (i.e., three lexical minimal pairs) were displayed on a spectrogram using Praat. The minimal pairs were represented as pitch contours that could display their Hz measurements. For the present study, f0 peak and onset times were measured. The raw data from these measurements were normalized as shown in the equation below.
The normalization of peak times on the pitch contour was computed in terms of equation (4). α is a vector that accounts for a peak on the contour shape, and β is a starting point. γ involves distances of pitch contour. Based on equation (4), the normalization of f0 peak times in the pitch accent contrasts of North Kyungsang Korean effectively shows the relationship between categorization and production; categorical or continuous production could thus be derived.
The statistical analysis was conducted using a mixed-effect linear regression model using the lmer function in the lme4 package (Bates et al., 2015) in R (version 3.2.2.). The fundamental frequency (f0) values corresponding to the pitch accent patterns (HL, HH, and LH) were computed as the dependent values. The fixed-effects predictors are three lexical pitch accent patterns, HL-LH, HH-HL, and LH-HH. These patterns were obtained from the responses of the production and imitation tasks. Additionally, the Markov Chain Monte Carlo (MCMC) package (Martin et al., 2011) in R was used to get the p-values for individual speakers’ production and imitation. The random-effects predictor was used for individual speakers and items. The intercept values produced from the random-effects operation was assessed across individual variations.
3. Results
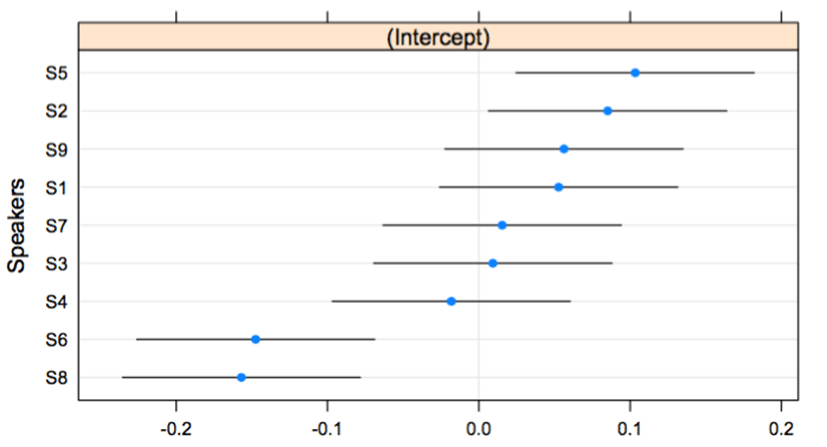
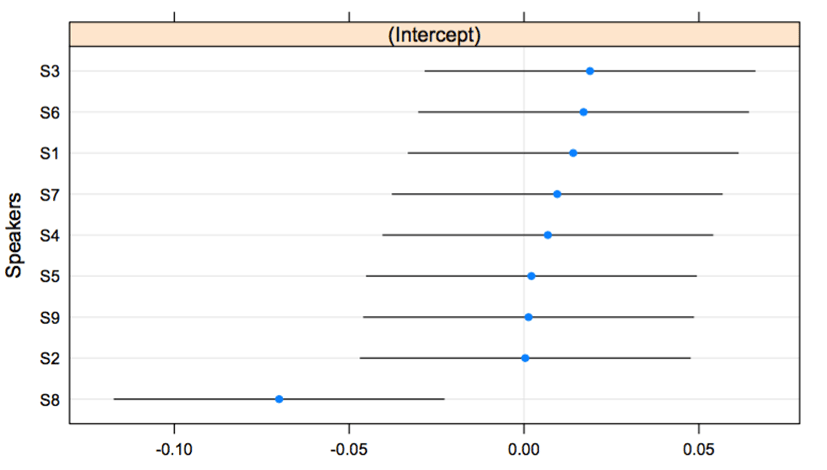
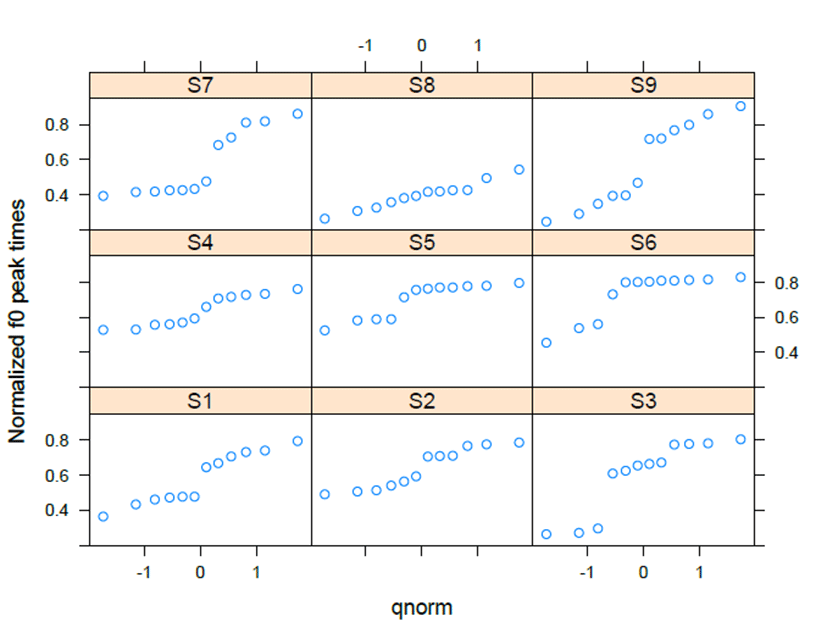
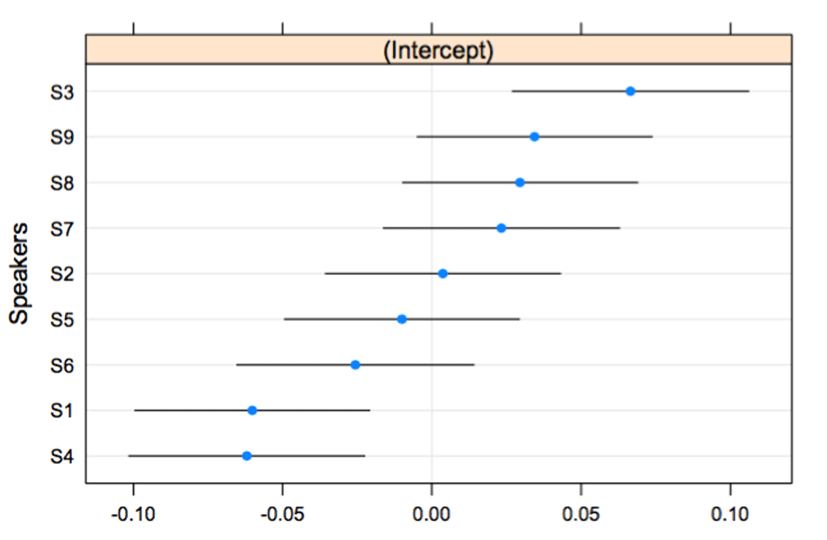
The responses of speakers’ production showed significant differences among lexical pitch accent patterns. Specifically, the pattern between HH and LH was significantly different between that of HL and LH (β=-0.161, t=-6.096, p<.001) and that of HH and HL (β=-0.250, t=-9.437, p<.001). <Figure 2> shows the production responses of the HL-LH pattern. The subject, S1, shows categorical production. That is, using qnorm scales, the difference between HL and LH for S1 appear to be around zero, reflecting a categorical effect. The idea of qnorm represents a probability. It recurs with the number whose cumulative distribution corresponds to the probability. S1 has a statistical distinction with S6 (β=-0.236, t=-2.543, p<.05) and S8 (β=-0.247, t=-2.663, p<.01). In particular, S6 and S8 display gradient curves without any boundaries. As shown in <Figure 2>, S1, S2, S4, and S7 showed clear boundaries in the middle of curves, and the boundaries reflect some spaces or abrupt changes on the curves. S3, S5, and S9 show continuous boundaries, but there are some distinctions among the curves consisting of shifts. In <Figure 3>, the categorical boundary is reflected in the values of the intercept. The intercepts of S6 and S8 are between –0.1 and –0.2. Except them, the intercept values above or around zero, linked with the distinction between HL and LH, supports categorical production in the dimension of significance values (i.e., p-values).
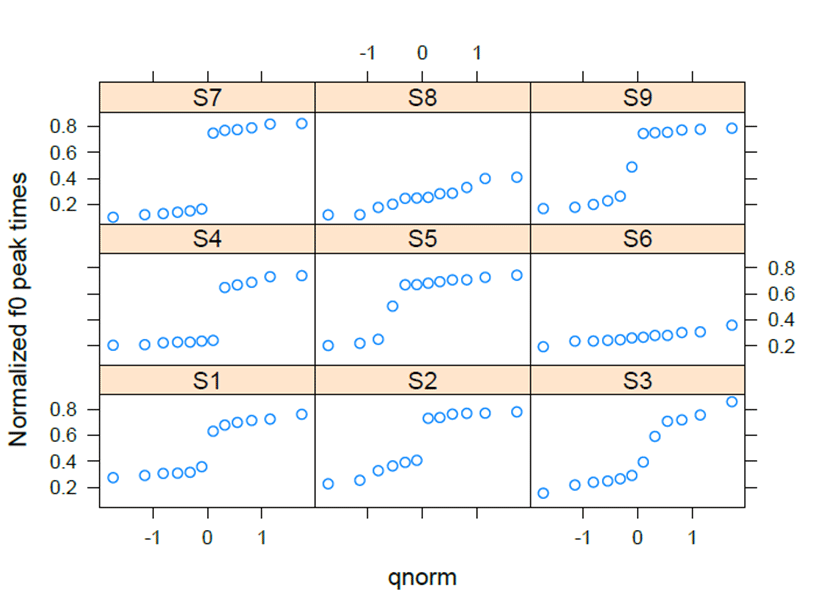
For the f0 values in HH-HL, the individuals’ patterns display more continuous curves than those of HL-LH. In <Figure 4>, there are distinctive curves only for S7 and S9. The subjects, S1, S3, S4, and S5 show continuous curves, though there are shifts at the middle of the curves. On the other hand, S2, S6, and S8 show gradient curves in the space of the qnorm scales. Statistically, S1 differed from S8 (β=-0.150, t=-2.340, p<.05), informing us that S8 did not distinguish between the HH and HL pattern. The intercept values in <Figure 5> give supportive information for subject S8.
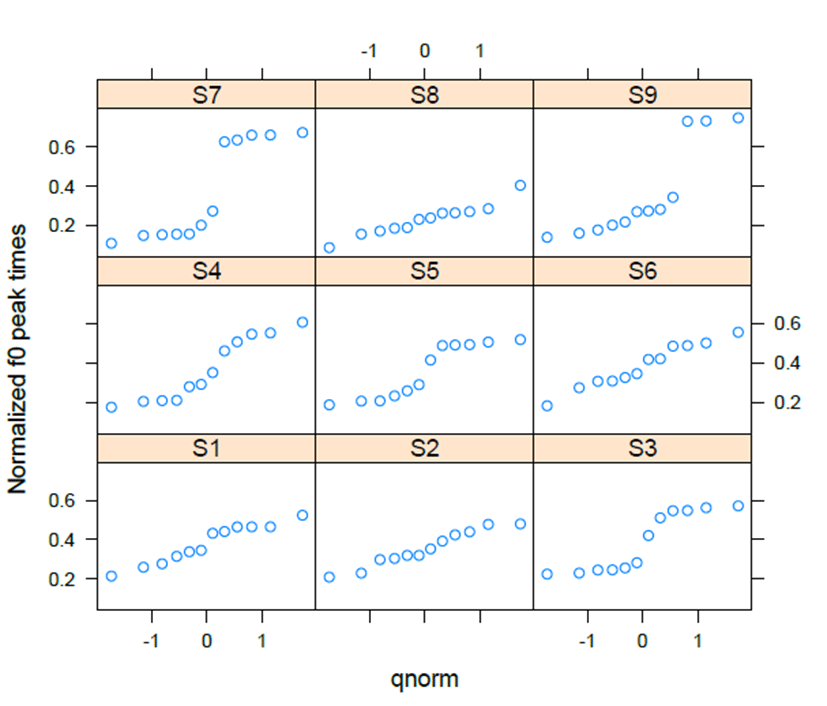
The patterns of HH-LH in <Figure 6> exhibit that S1 statistically differed in two speakers’ productions (S6: β=0.149, t=2.391, p<.05, S8: β=-0.005, t=-0.089, p<.01). The subject, S1, S4, S5, S7, and S9 show categorical distinctions, but there are continuous shifts or intervals at the middle of the curves. S2, S3, S6, and S8 show more or less continuous effects, even though there are irregular intervals on the curves. <Figure 7> shows some individuals’ patterns for intercept values, especially for S6. However, S8’s intercept value is consistent with the significance value. S8 display nearly flat lines when the other speakers show gradient boundaries in the middle of curves. The intercept values convey the values of relevant categories, which supports significant p-values for subjects other than S6.
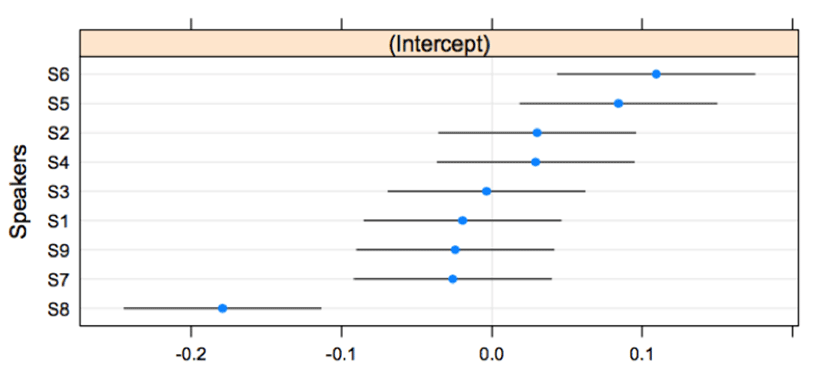
The three lexical pitch patterns in imitation responses are significantly distinctive for HH-LH and HL-LH (β=-0.092, t=-7.087, p<.001) and for HH-LH and HH-HL (β=-0.199, t=-15.289, p<.001). The patterns of HL-LH show categorical boundaries, reflecting the fact that there are abrupt curves between HL and LH. In <Figure 8>, the space is separated by categorical lines for S1, S2, S3, S7, and S9. The subjects, S4, S5, S6, and S8 showed atypical curves. Subject S1, showed a typical categorical boundary around zero in the space of the qnorm scales. S1 had a significant difference from S4 (β=-0.093, t=-2.219, p<.05) and S6 (β=-0.087, t=-2.067, p<.05). S4 and S6 display continuous curves across the qnorm scales. With respect to the values of the intercepts in <Figure 9>, S4 and S6 have the lowest values, which did not indicate categorization. For other speakers in <Figure 9>, S7 is the best performer for showing categorization between HL and LH.
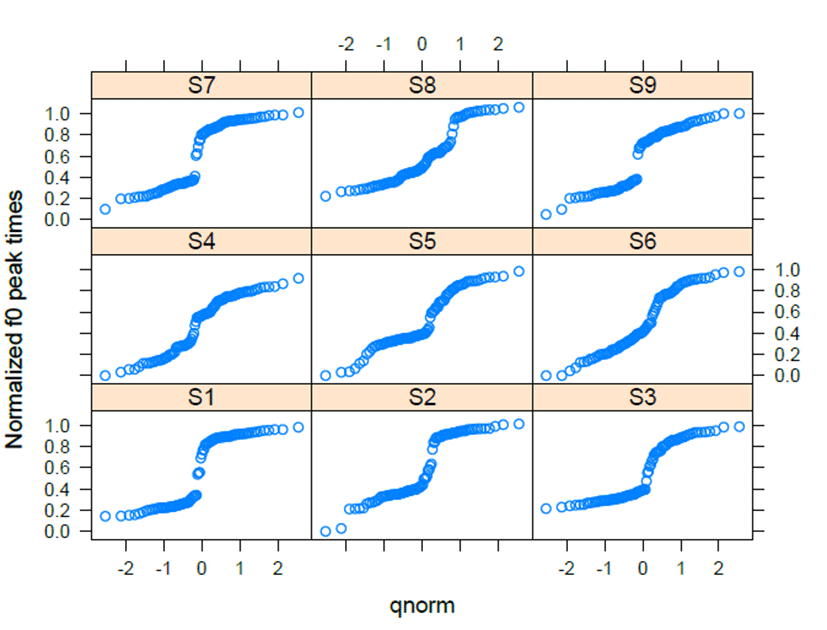
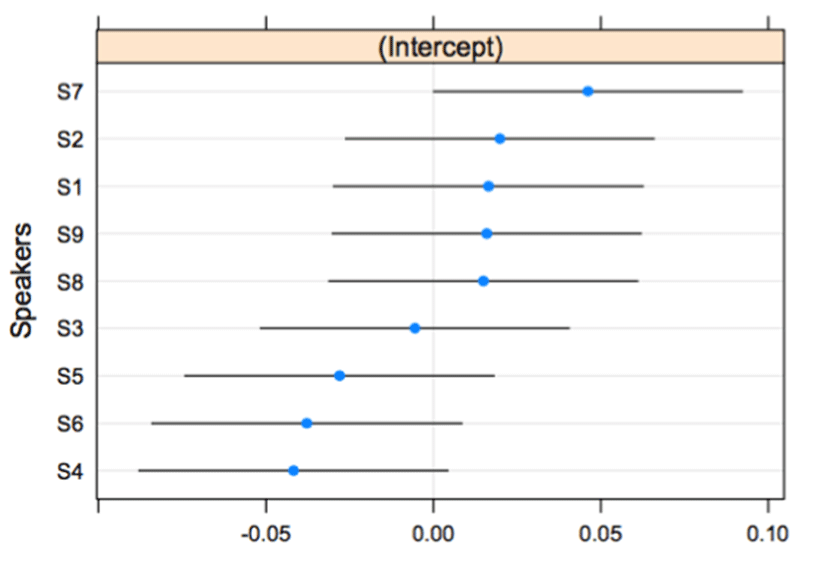
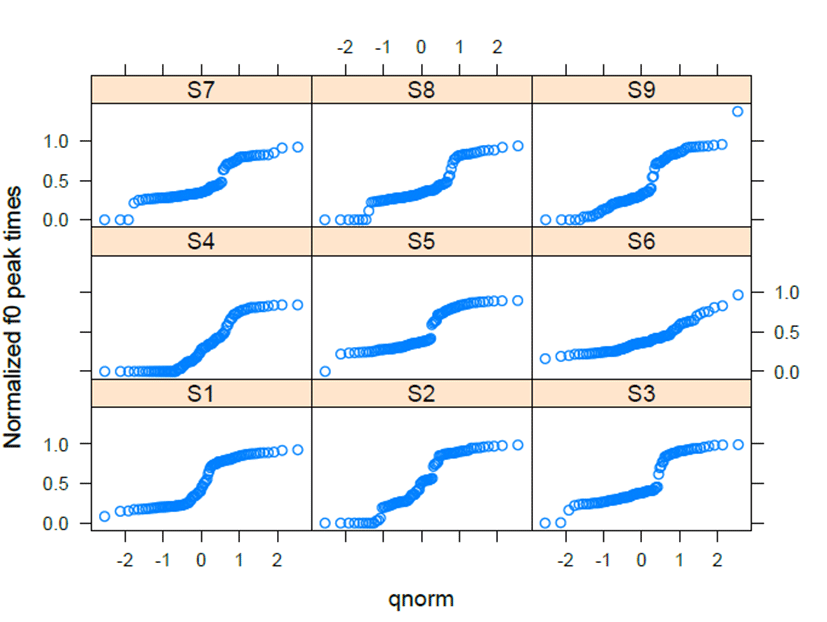
The HH-HL patterns in <Figure 10> showed more varied curves due to the competition of f0 peak times. S1, S2, S3, and S5 exhibit categorical boundaries that keep the distinction of HH and HL. S7 and S9 have more or less continuous curves that take the shape of two lines with dots, indicating a narrow space at the center of the curves. S1 had a statistic distinction from S4 (β=-0.187, t=-4.583, p<.001), accounting for that S4 took more zero. S1 also significantly differed from S6 (β= -0.107, t=-2.620, p<.01) and S8 (β=-0.090, t=-2.222, p<.05). S6 shows nearly flat lines, and S8 has more curves. <Figure 11> reflects the curves of HH-HL using intercept values. S1, S2, S3, and S5 have the highest values in the intercept scales. The intercept values in <Figure 11> correspond to the characteristics of categorical distinctions as shown in <Figure 10>.
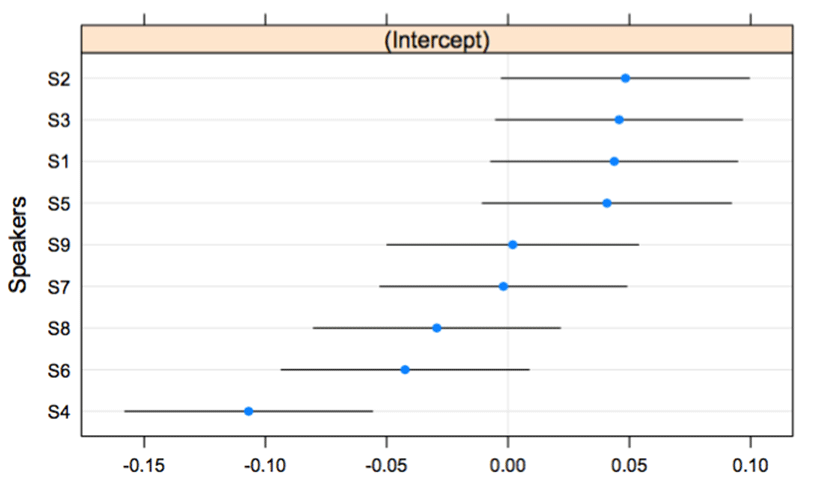
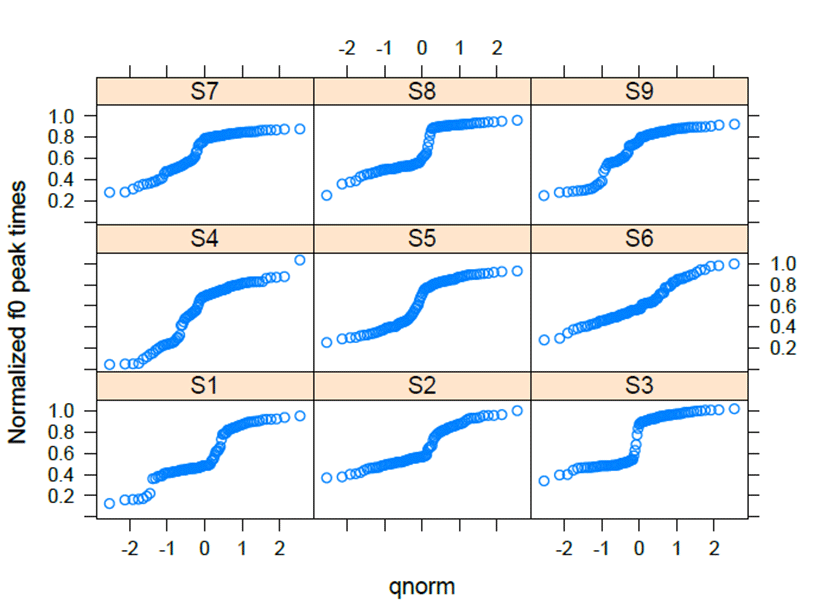
The imitation of HH-LH in <Figure 12> shows categorical or continuous boundaries that are reflected in various curves. The categorical characteristics of HH and LH produced the boundaries around zero along the qnorm scales. In <Figure 12>, S2, S3, S7, S8, and S9 show categorical boundaries at the center of the space. S3 and S8 exhibit categorical boundaries that have elaborate curves. The statistical values were compared with S1; S1 does not have the distinctive qualities of a particular type for categorization of HH and LH. S1 had a statistical difference with S3 (β=0.153, t=4.885, p<.001), S8 (β=0.108, t=3.473, p<.001), S9 (β=0.114, t=3.662, p<.001), S7 (β=0.100, t=3.215, p<.01), and S2 (β=0.077, t=2.472, p<.050). S5 (β=0.060, t=1.942, p=.052535) is borderline compared to S1’s curve. S4 and S6 showed continuous curves that are not different when compared with the normalized f0 peak times of S1. The values of intercept have the exact tendency corresponding to the curves that show categorical or continuous boundaries. In <Figure 13>, S3 is the best performer to imitate the HH-LH pattern. S1, S4, and S6 were the poorest imitators for this pitch accent pattern.
4. Discussion
In this study, the performance of production and imitation of lexical pitch accent patterns by the North Kyungsang speakers was assessed. The present research shows categorical boundaries in producing and imitating the three lexical contrasts. When the three pitch accent patterns have distinct boundaries, the categorization and production present specific visible curves. The present study’s findings depend on the curves for lexical pitch accent contrasts, which are divided into categorical or continuous performances. First, the production curves were categorized based on speakers’ imitation. The separations between production and imitation are based on categorical production; the performances with categorical characteristics have distinctive qualities in terms of lexical cohesion. Second, the differences in the performing curves should accurately portray the articulation of lexical pitch accent patterns. The patterns of these cases, including various curves in production and imitation, are not identical. To sum up, speakers’ production and imitation of pitch are affected in their performances; this gives us a good picture of the process of cognition.
The categorical performance for both production and imitation are observed in figures. The imitative behaviors show the steps on the way to production. The moment of articulators’ movement gets the timing of the difference of lexical pitch accent contrasts. The lexical categories found in this study, based on speakers’ production, are useful for understanding how speakers focus on critical signals. The production of lexical pitch accent contrasts is unique to the performance of the North Kyungsang prosodic units. The units spoken in the production process are connected to the process of imitating given pitch accent patterns.
The fundamental values of imitation can be thought of as the learning of articulatory movements while infants are in the babbling stage. The early vocal learning of infants provides the first step of acquiring their native languages or dialects (e.g., Kent, 1979; Kent & Forner, 1979; Kuhl & Meltzoff, 1996). The relationship between language processing and categorization is a challenge for infants who are undergoing the process of acquiring a native language and its dialects.
The first scenario is that when children are growing up in their language environment, their prosodic system, along with vocalic representation, acquires the contrasts as phonological units. Speakers’ access to the lexical items controls their prosodic system in their native dialect. The case of both imitation and production convey the traces of categorical distinction in their spontaneous speech. The states of categorical production absorb the unique production movements of speakers. This case is rooted in the imitative method for speakers’ curves, which is reflected in the present study.
Imitation and categorization are flexible in children and adults who have experienced other dialects or languages. However, their production and categorization will not be at the same skill level when they articulate a particular chunk of language which holds semantic information. Conscious categorization comes from imitation, which can follow an initial state of acquisition in the first steps of production. The results of the present study point out that the categorization of production and imitation allows for the tightness of distinctive production in their speech.
The second scenario is that if the units that are a vocal representation give semantic information, tiny units of prosodic clues will take on the condition of being capable of being acquired prosodically. The categorical condition is different from continuous curves, as seen in the results of the present study. After deviations were eliminated, the imitation and production tasks did not provide a series of gradient curves. Instead, categorization extends prosodic units that follow distinct pitch contours. Vocal elements thus occur on the prosodic level. Categorization of imitation is the best way in the processing of languages or dialects to acquire the syllable and prosodic combination.
The categorization appears on a case-by-case basis in the representation of production and imitation. The categorical production from both types of tasks brings about cooperation of lexical conditions. Imitation that is used to stimulate speech among speakers is productive. Additionally, this study grouped imitation and production according to categorical or continuous distinction. Categorical production shows identical contrasts in phonological units. North Kyungsang Korean speakers has lexical pitch accent contrasts, that were produced with categorical distinction in both imitation and production tasks. Categorical production can be thought of as phonological elements in a lexical mind. Categorization is thus a way for speakers to pay attention to speech categories.
The lexical pitch accent patterns derived from individual performances are central for categorization and production, and the results, based on statistical values, produced classes of lexical pitch accent contrasts for the speakers who participated in the present experiment. Simply proving classical patterns in phonological theory does not convey the notion of distinction in the categorization of lexical pitch accent patterns. That is, the term “phonological contrasts” can refer to assembling clues to distinguish the tight signal, thereby giving meaningful information. Individual speakers in the present experiment did not provide identical phonological contrasts in production and imitation tasks; instead, they displayed various curves representing pitch contrasts (in the relationship of categorization and production) suggesting a speaking continuum. Categorical representations of pitch contrasts appear for speakers who discern competing lexical items. Speakers without categorical boundaries between minimal pitch accent pairs showed continuous curves and non-categorical variants with sparse curves.
The pitch accent patterns HL-LH in the production task of the present study showed strict categorical boundaries for most of the speakers. The HL-LH pattern is a rising and falling pitch contour, and the differences in peak timing were considerable. However, the HH-HL patterns spoken by individual speakers were variable curves, indicating multi-level crossing of pitch contours. The HH-HL patterns suggests confusion on the part of some speakers between the HH and HL patterns, which produced continuous curves and even scattered dots on the qnorm scales. The HH-LH production displays pattern awareness, which can control speakers’ mastery of pitch contours produced by the participants in the present research. The peak timing of HH did not have a considerable distance from that of HL, but the LH patterns are rising contours in contrast to the falling contours of HL. The difference between HL and LH includes a large distance of timing between the peaks. The peaks of HH-LH are more relevant categories than those of HH-HL. In the categorization of production for each pitch accent pair, the effective use of peaks to split the semantic units follows individuals’ speaking patterns.
The imitation task for HL-LH, HH-HL, and HH-LH shows the effect of individual differences in the production of lexical pitch accent patterns. The present case results in the imitation responses showing the prominence of the HL-LH pattern in categorization. The categorical boundaries in the imitation responses were found in the central portion of speakers’ lexical sequence for curves on the qnorm scales. The curves within that space consist of clusters of the two separate lexical units. The relationship between categorization and production in the imitation responses is shown in the distinction of the continuance of curves, accounting for the phonological items occurring on a continuum, which shows some stages for articulatory development. The categorization of imitative responses is critical for language processing. The categorical production of lexical units was distributed on an individual level for participants in the present study. Individual speakers acquire crucial information for producing and imitating meaningful units. In this sense, categorization drawn from imitation is required for the development of articulation and to process language.
5. Conclusion
The present study showed categorization for both production and imitation with boundaries around the center of curves. The categorical boundaries did not appear for all subjects in the present study, but for some speakers, there were continuous curves showing different pitch accent patterns at both ends of the curves. Categorical production can capture selective signals for strict categorical boundaries, whereas speakers are not all tuned in to the same signals, so some produce continuous curves. Those curves at the end of speech signals give some information for differentiating minimal pairs. From the present study, the case of categorical production can be drawn in terms of cognition. The processes of cognitive activities are dependent on individual speakers’ productions. In future research, performance for the categorization of lexical pitch accent patterns need to be further investigated using a variety of speech materials.