





1. Introduction
Speaking rate (or tempo) is a major source of variation in the realization of duration-based acoustic cues for phonological contrasts, and this poses a challenge to listeners’ perception of phoneme boundaries. Studies of voice onset time (VOT) have found that two segments that contrast based on voicedness are asymmetrically affected by speaking rate, with the phonetically longer segments undergoing a marked change and the shorter segments serving as phonetic anchors (Kessinger & Blumstein, 1997). On the other hand, it has been reported that segments that contrast based on a length distinction, such as long/short vowels in Japanese (Hirata, 2004) or singleton/geminate consonants in Italian (Pickette et al., 1999), maintain a constant duration ratio across varying speaking rates.
A related, but relatively less investigated, issue concerns the effects of coda voicing on the duration of the preceding segments under various speaking rates. It has long been known that vowels are longer before a voiced than a voiceless consonant. Additionally, it is well documented that the closure duration of the coda consonant is longer for voiceless codas than for voiced codas. However, issues such as the domain of the effects of coda voicing or the nature of tempo-dependent changes in duration conditioned by coda voicing remain largely unanswered. To address these issues, this study investigates the effects of coda-voicing on duration in CVC words and examines if there is any acoustic invariance under varying speaking rates.
The ratio between the durations of the preceding vowel and the coda consonant, henceforth the V/C ratio, has been reported to be perceptually the most relevant cue for coda voicing in American English (Port & Dalby, 1982). Similarly, Pind (1986) finds the ratio between the durations of the vowel and the rhyme (the V/VC ratio) to be a near-invariant cue for the perception of vowel quantity in Icelandic. These ratios can be defined independently of speaking rate, and thus might be worth considering as stable markers of coda voicing. If the V/C ratio is an acoustically invariant cue for coda voicing, this would predict that listeners’ perceptions of coda voicing should not be affected by the overall speaking rate of the context in which the V/C ratio is embedded. Port & Dalby (1982), however, found that listeners’ voicing judgments in American English are influenced by the speaking rate of the frame sentence. Similarly, Pind (1986) also found that the manipulation of precursor rate caused small shifts in the phoneme boundaries in Icelandic.
The influence of the contextual rate on the perception of phoneme boundaries reported in Port & Dalby (1982) suggests that the V/C ratio, while serving as a strong cue for coda voicing, may not function independently of speaking rate. Thus Massaro & Cohen (1983) suggest that if the results of Port & Dalby (1982) mirror the information in the speech signal, the V/C ratio as a cue for coda voicing must vary with speaking rate. In other words, a prediction made on production is that the decrease in speaking rate may not necessarily lengthen the vowel and closure duration by the same proportion. Despite much research on the changes of various durational acoustic properties at different speaking rates, few studies seem to have directly tested the prediction made in Massaro & Cohen (1983).
We can think of several ways in which the durations of the vowel and coda consonant as a function of post-vocalic consonantal voicing may be affected by speaking rates. One of these is the possibility that the vowel and the closure duration in the voiced and voiceless categories might undergo changes by the same proportion in varying speaking rates. This would be the case if the V/C ratio is an invariant cue for coda-voicing. Another possibility is that the relative acoustic invariance may be found in a constant ratio between the longer vowel before the voiced coda and the shorter vowel before the voiceless one, or V-to-word ratio as in Japanese (Hirata, 2004). Also, we cannot rule out the possibility that the longer vowel before the voiced coda is stretched in a greater proportion than the short vowel before the voiceless coda in slow tempo. Moreover, the closure duration of the voiced and voiceless consonants may also undergo an asymmetric change, independently from the change in vowel duration. Such a situation would be similar to the asymmetric changes reported for the VOT, where only the long-lag voiceless consonants are affected by speaking rate whereas the short-lag voiced series remain essentially the same across speaking rates.
2. Method
Seven native speakers of English, two male and five female, participated. They were all college students enrolled in an introductory linguistics class at University at Buffalo. None of them had any known problems in speaking or hearing, and all reported that they were raised in Western New York. One female speaker spoke with a slightly different accent from the rest of the subjects (notably, she showed little or no raising of /æ/ in all environments), but was not different in differentiating vowel duration as a function of the voice feature of the post-vocalic consonant. Thus dialectal variation should not affect the overall results of this study. Participation was voluntary, thus no monetary compensation was made. The participants instead received extra credit for the course they were recruited from.
The following sets of English or English-like words were used: tag/tack, tig/tick, and teg/teck. These stimuli were designed to vary in coda-consonantal voicing as well as the vowel height. Each target word was embedded in three different sentential positions in a carrier sentence: "____ sounds right" (sentence-initial), "Dance ___ fast" (sentence-medial) and "Now say ___ " (sentence-final). Each speaker read the stimuli 4 times, yielding a total of 1,512 tokens (6 words × 3 sentence positions × 4 repetitions × 3 speaking rates × 7 speakers).
The stimuli were presented on a computer screen by a custom script. The data were blocked by speaking rate, and each speaking rate block contained four blocks of semi-randomized list of the stimuli. The speaking rate blocks were preceded by short practice sessions containing three sentences presented at the corresponding speaking rate of the following recording session.
The data were presented in the order of fast, habitual, and slow speaking rate, with the interval between the onsets of each stimulus presented on the screen fixed at 2, 3.3, and 4.5 seconds, respectively. The speakers were told to speak as fast as possible, as if talking to someone leaving the room (Kessinger & Blumstein, 1997) for the fast condition, at their normal speaking rate for the habitual condition, and as slow as they could without obstructing intelligibility for the slow condition. Note that the interval between the presentations of the stimuli for the slow speaking rate condition was purposefully made quite long relative to the length of the target sentences. Speakers were encouraged to make full use of the interval in each condition, which achieved an effect of efficiently forcing the participants to speak at their slowest of speaking rate possible in the slow condition. This was necessary for the purpose of investigating the acoustic invariance in vowel/consonant ratio in the full range of varying speaking rates.
The experimenter demonstrated an example of the target speaking rate by reading several stimuli. The speaker then read the sentences presented on the computer screen for practice before each speaking rate block. The speakers were allowed to repeat the practice session if desired, but most did not require an additional practice session. After each practice session, the speakers were offered a chance to adjust the inter-stimulus interval. However, all felt the default interval values were appropriate. The recording session was started by a click of the mouse by the speaker. Participants took a short break between each speaking rate block. The entire session took about 25 minutes.
The recording was made in a sound-attenuated booth in the Linguistics Department of University at Buffalo using a unidirectional USB microphone and a pop filter. The speech was sampled at 44.1 KHz via Praat (Boersma & Weenink, 2011) and was directly saved on the computer disk.
Each utterance was aligned with its transcript at the segmental level using the Penn Phonetics Lab Aligner (Yuan & Liberman, 2008). The segmental alignment in each target word was then manually corrected by the author according to the criteria in Foulkes et al. (2010). The following measures were taken for the target word: VOT of the onset, vowel duration, and closure duration of the coda. In addition, the duration of the entire carrier sentence was measured. To check the reliability of the segmentation, a research associate coded a random selection of 10% of the tokens produced by each of the participants (a total of 154 tokens). The mean absolute differences between the two sets of boundary annotations were as follows: 4.3 ms for the vowel onset, 8.9 ms for the vowel offset / coda consonant onset, and 6.6 ms for the coda offset. Thus, all values were under 10 ms, indicating a high level of agreement between the two annotators.
Mixed effects linear regression models were constructed for statistical analyses using the lmerTest package (Kuznetsova et al., 2017) of R (R Core team, 2017). The analysis presented in this paper focused on the two fixed effects of SPEAKING RATE and the CODA VOICING. The dependent variables were SENTENCE DURATION as a proxy for speaking rate, the paradigmatic VOWEL/VOWEL (V/V) RATIO, and the syntagmatic VOWEL/CONSONANT (V/C) RATIo depending on the research question being asked. The reference level for the speaking rate was set to the habitual condition. Data with different vowel heights and sentence positions were collapsed in the current paper to focus on the interaction between the two fixed effects of SPEAKING RATE and VOICE. The variations among PARTICIPANTS and the ITEMS were treated as random effects.
3. Results
Firstly, the overall level of task efficiency in the participants’ manipulation of the speaking rate was analyzed. Using the sentence duration in each token as a proxy for a measure of speaking rate, I constructed a mixed effects linear regression model with the SENTENCE DURATION as the dependent variable, SPEAKING RATE (fast, habitual, and slow) as the fixed effect, and the ITEM and PARTICIPANT as random factors (formulae: sentence duration ~ speaking rate + (1|item) + (1|subject)). A likelihood test comparing this model with the reduced model without the fixed effect of SPEAKING RATE confirmed the significant effect of SPEAKING RATE on SENTENCE DURATION (χ2 (2)=2,289.8, p<0.001), which increased by 139 ms±56 ms (standard errors) in the habitual, and by 1,057 ms±56 ms in the slow condition compared with the fast speaking rate. The small but significant increase of duration from fast to habitual, and the large increase from habitual to slow speaking rate are demonstrated in <Figure 1>.
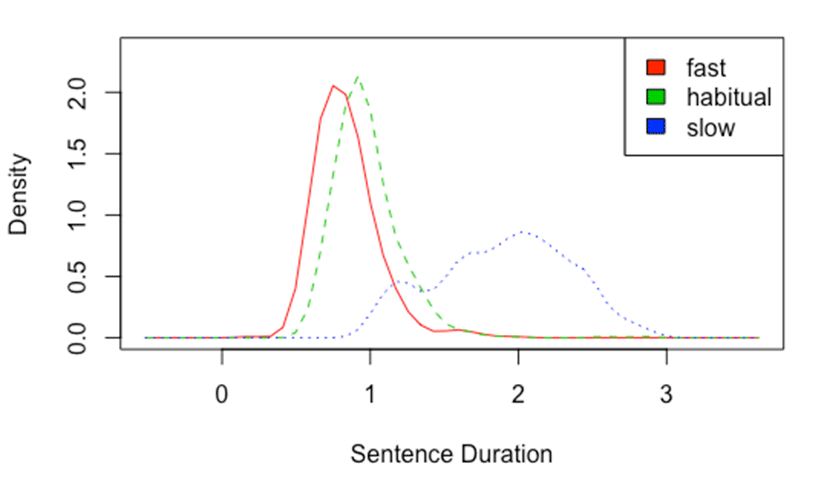
We can, therefore, assume that the participants’ manipulation of speaking rate was overall efficient, and move on to a further analysis of the data to investigate the effects of speaking rate on various aspects of tempo-related acoustic cues.
Note that the stimuli were presented at a linearly increasing interval of 2, 3.3, and 4.5 seconds for each of the speaking rate conditions, but the increase in the duration of the sentence was not linear: The mean duration of the sentences was 838 ms (SD: 208 ms), 977 ms (SD: 227 ms), and 1,894 ms (SD: 444 ms). This reflects the well-known incompressibility phenomenon (Lehiste, 1972, Klatt, 1973), whereby the combined effects of shortening become smaller and the duration asymptotically approaches some minimum value.
Before addressing the syntagmatic relation between the vowel and the consonant under varying speaking rates, we turn to the investigation of paradigmatic change of ratios between each of the syllabic components in the minimal pairs. In particular, I seek to find if there is a constant ratio maintained between the long vowel before the voiced stop and the short vowel before the voiceless stop across different speaking rates. The hypothesis explored here is the notion of paradigmatic invariance, i.e. the absolute duration of the long vowel will always be longer than the short vowel across the speaking rates but the ratio between these two vowel categories would remain constant across different speaking rates. In other words, we expect a parallel line between the regression lines for the two data categories.
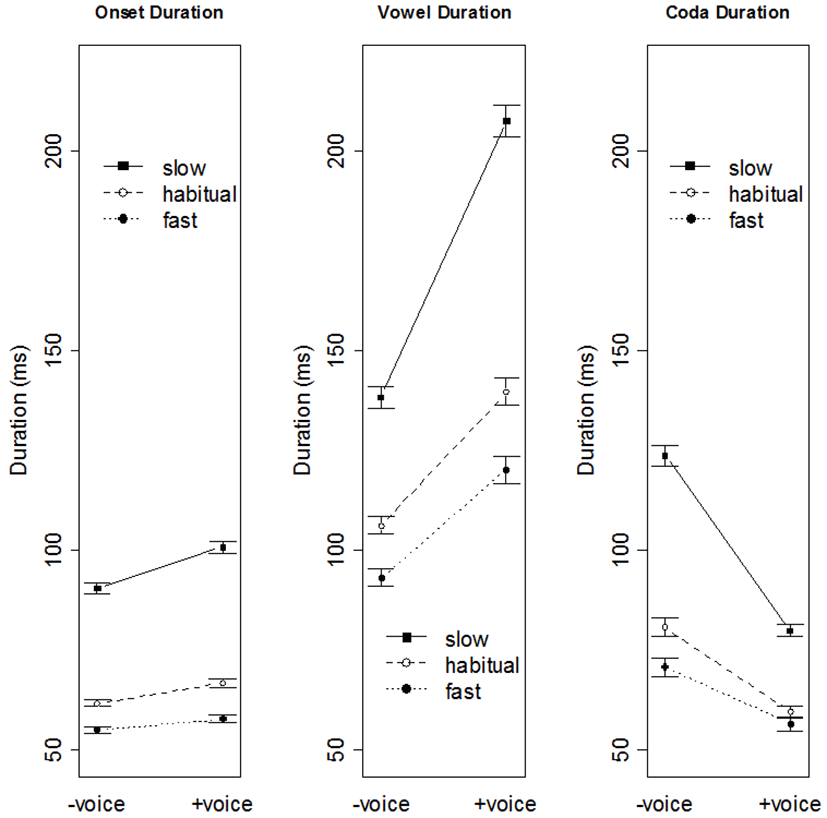
<Table 1> presents the means (and standard deviations) for the durations of the VOT of the onset consonant, the vowel, the coda consonant, and the entire target word across the three speaking rates. As expected, the absolute durations of all four categories increased as the speaking rate decreased. The respective distributions of the VOT, vowel, and coda closure durations in the voiced and voiceless conditions substantially overlapped at all speaking rates, but the mean values for the VOT and vowel were always significantly longer in the voiced category and the mean closure duration was always longer in the voiceless category.
The longer mean duration of the onset VOT in the voiced category compared to the voiceless category was particularly interesting, since it shows that the voice feature of the coda affects the duration of the onset from a distance. <Figure 2> provides a graphical comparison of the effect of coda consonant voicing on the duration of the three different segments (onset, vowel, coda) across the three different speaking rates.
To statistically test the invariant hypothesis of the paradigmatic relation between the vowel duration before a voiced and a voiceless consonant, i.e. abbreviated as the V/V ratio, a mixed effect linear model was constructed with the V/V RATIO as the dependent variable, SPEAKING RATE and CODA VOICING as fixed effects, SUBJECT and ITEM as random factors (formulae: V/V ratio ~ speaking rate + (1|subject) + (1|item)). To prepare the data for this formulae, a mean of the four repetitions for each word in each speaker was taken. This reduced the total number of tokens to one fourth of the original 1512, i.e. 378 data points. Then the V/V ratio was calculated for each minimal pair by dividing the mean duration of vowel before the voiced coda by the one before the voiceless coda, resulting in a 189 final data points.
A likelihood test of this model with and without the fixed effect shows that speaking rate has a significant effect on the V/V ratio (χ2 (2)=56.1, p<0.001). An inspection of the three levels of speaking rate revealed that the V/V ratio of fast speaking rate is not significantly different from the V/V ratio of habitual speaking rate (t(178)=-0.70, p=0.49). The V/V ratio in the slow speaking rate, however, was significantly greater by 0.22±0.03 (standard error) from that of the habitual rate (t(178)=6.6, p<0.001).
The significant effect of speaking rate on the V/V ratio found above indicates that the change in the speaking rate did not affect the segment duration by the same proportion. That is, although the absolute duration of each segment increased as speaking rate decreased in both the voiced and the voiceless coda conditions, the duration of vowel in the voiced condition seems to have expanded to a greater degree than the voiceless condition. This trend was particularly salient in the slow speaking condition. Such asymmetric expansion of segment duration could have affected the syntagmatic relation between the coda consonant and the vowel. I will now move on to looking into this relation.
As shown in <Table 2>, the ratio of vowel durations before voiced/voiceless consonants (the V ratio) increased whereas the closure duration in voiced/voiceless consonants (the C ratio) decreased as the speaking rate decreased. Consequently, the V/C ratio increased with a decrease in speaking rate in the voiced coda condition but an opposite trend was found in the voiceless coda condition, as shown graphically in <Figure 3>.
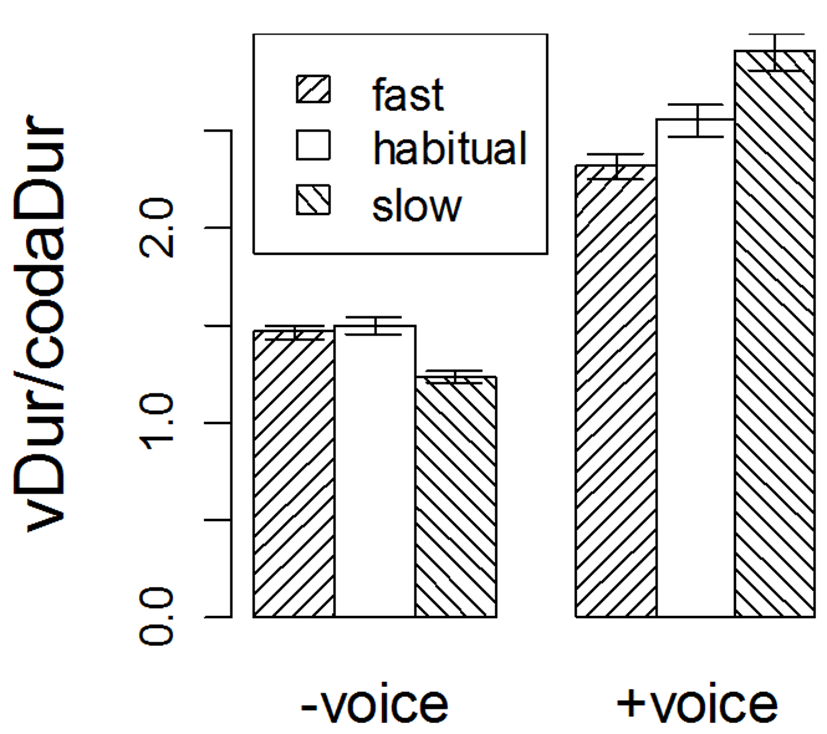
These asymmetric changes reflect the combined effects of incompressibility: in the voiced category, vowels are generally longer but the coda closure duration is shorter than the respective values in the voiceless category. As speaking rate decreases, the duration of the vowel stretches more before the voiced coda than the voiceless coda, whereas the closure duration stretches more in the voiceless coda than in the voiced coda.
A mixed effect linear regression model was constructed to test the statistical significance of the interaction between SPEAKING RATE and CONSONANTAL VOICING on the vowel/consonant ratio (formulae: vcRatio ~ voice * speed + (1|subject) + (1|item) ). The summary of this model is presented in <Table 3>. A comparison of this model with the one without the interaction showed that a model with a significant interaction between the speaking rate and consonantal voicing explains the data better (χ2 (2)=73.0, p<0.001).
An inspection of the interaction at different levels of speaking rate reveals that the interaction between the coda consonantal VOICING and SPEAKING RATE was significant at all levels. Specifically, the interaction between –VOICE: SPEEDFAST indicates that effect of the fast speaking rate on the V/C ratio in the voiceless condition increased by approximately 0.195 compared to the effect of fast speaking rate in the voiced condition. The interaction –VOICE: SPEEDSLOW indicates that the effect of voiceless coda consonant under the slow speaking rate decreased by approximately -0.62. Both of these interactions show that the V/C ratio in the voiceless condition decreases if speaking rate slows down.
4. Discussion
This study showed that the ratio of vowel duration before voiced/voiceless coda consonants increases non-linearly as the speaking rate decreased. This finding poses challenge to the notion of ‘stability of temporal contrasts’ suggested in Smiljanic & Bradlow (2008). The claim was that contrasts in the duration of pre-consonantal vowels maintain a stable ratio across different speech styles such as normal and clear speech. In the present data, however, both the absolute and proportional distance between the vowel durations before the voiced/voiceless codas increased as speaking rate decreased.
This discrepancy may be explained by the different ranges of variation in tempo. The ratio of mean sentence duration in our study was 0.42 for fast/slow speech compared to 0.72 in a similar study (Port, 1981). Smijlanic & Bradlow (2008) do not report the durational difference between the different speaking styles, but, judging from the lack of any specific reference to tempo in the instructions to speakers, it is likely that the clear speech in their study might have had only a slightly slower speaking rate than the normal speech. Given that the ratio of vowel durations before voiced and voiceless codas in fast and habitual tempo in this study also came out very close to each other (1.29 in fast speech and 1.31 in habitual speech), but substantially increased (to 1.5) in slow speech, the stability of temporal contrasts put forth in Smiljanic & Bradlow (2008) seems to hold only in a limited range of temporal variation.
The results of this study can be contrasted with the patterns reported with Japanese long and short vowels (Hirata, 2004), where the long-to-short vowel ratio or V-to-word ratio in each of the short and long vowel categories did not change under different speaking rates. This stability in temporal contrasts was found under a condition where the ratio of fast speech over slow speech (0.40) was comparable to ours (0.42). Such a cross-linguistic comparison of the data on vowel duration in varying speaking rates suggests that tempo-dependent modulation of durational cues may be implemented according to language-specific principles.
The present finding of longer VOT duration in words ending in a voiced coda compared to those ending in a voiceless one reveals that the effect of coda voicing on duration reaches beyond the immediately preceding vowel. As expected, however, the magnitude of the effect of coda voicing was greater for the vowel than the onset consonants. That is, the onset VOT in the voiced category was on average 5% (2.83 ms) and 11% (10.58 ms) longer than the value in the voiceless category at fast and slow tempo, respectively. In comparison, the duration of vowels before voiced codas was 26% (24.22 ms) and 50% (68.45) longer than before a voiceless coda in fast and slow tempo, respectively. This finding is reminiscent of phrase-final lengthening, where the lengthening effects of the phrasal boundary have been shown to begin before the phrase-final syllable although the magnitude of lengthening is stronger approaching the boundary (Turk & Shattuck-Hufnagel, 2007).
Not all languages demonstrate a proportionately greater stretching of longer duration in slow speaking rate. While a pattern similar to the finding in this data is reported for Arabic (Port et al., 1980) and Icelandic (Pind, 1999), Thai data in Svastikula (1986) suggests the opposite trend where long vowels are increased in a smaller proportion than short vowels with the decrease in speaking rate. Moreover, the data in Port et al. (1980) suggest that the V/C ratio of Arabic long vowels before /t/ increases with the decrease of speaking rate (from 2.03 in fast to 3.49 in slow tempo), contrary to the pattern found in our English data. Thus, it seems that the asymmetric V/C ratio changes under varying speaking rates found in our study are not the results of a universal or an automatic phonetic process but reflects a more carefully controlled temporal adjustment in reference to the phonological representation of the postvocalic consonant.
I suggest that the motive behind the asymmetric changes in the V/C ratio could be speakers’ listener-oriented adaptation of articulatory behavior to enhance auditory distinctiveness. That is, by lengthening or shortening a vowel, speakers can make the following short or long closure duration of a voiced or a voiceless consonant appear to be even shorter or longer than it is (Kluender et al., 1988). The present finding of the asymmetric V/C ratio change in the voiced/voiceless coda as a function of tempo is particularly interesting in that it illustrates a case of how such an auditory enhancement effect can be augmented even further by decreasing the speaking rate. The auditory account of the asymmetric V/C ratio changes thus suggests that speakers might use slow speaking rate to provide enhanced auditory cues.
5. Conclusion
This study found that the V-to-C ratio and other related measures of relative duration changed asymmetrically before a voiced vs. voiceless coda as a function of tempo, which yielded a greater, thus more enhanced, durational contrast between the vowel and the coda closure duration as the speaking rate decreased. In addition, this study found that the scope of the effects of coda voicing on the preceding segmental duration goes beyond the pre-consonantal vowel. These findings challenge the notion that a stable ratio of durational cues is maintained across different speaking rates in English.