





1. Introduction
For the past couple of decades, a number of studies have documented on-going changes of acoustic properties associated with the vowel /u/-/o/ contrast in Seoul Korean. They reported observations of decreased F1 values of /o/ vowels, yielding in turn the reduced acoustic distance between /u/ and /o/ along the F1 dimension. When examined locally, on the one hand, this /o/-raising (indicated by lowered F1) resulted in a seeming merge of /o/ into /u/ as discussed in the earliest studies (e.g., Han et al., 2013; Han & Kang, 2013; Jang et al., 2015; Moon, 2007; Seong, 2004). On the other hand, more global examination of the whole vowel system in subsequent acoustic studies raised an alternative view that the /o/-raising is a part of systematic chain-shift taking place in the vowel system. That is, non-front vowels in the modern Seoul Korean undergo sound changes of raising or fronting themselves: /ʌ, o/ vowels have decreased F1 values (/ʌ, o/-raising), and /u, ɨ/ vowels have increased F2 values (/u, ɨ/-fronting) (Kang, 2014; Kang & Kong, 2016; Lee et al., 2016; Lee et al., 2017). Since these global changes have not accompanied any reported perceptual confusion between categories, which then would possibly imply a merge of vowel categories, this sound change can be viewed as a process of the vowels being acoustically redefined with no changes of phonological role. In this sense, the /u/-/o/ contrast is manifested with F2 difference more effectively than with F1 difference.
The current study is interested in understanding how the speakers in the speech community interact with this on-going sound change related to a /u/-/o/ contrast. This question has been investigated so far in terms of gender differences in many prior studies. As Labov (1990) proposed, women are known to lead the sound change by being more adaptive to the new forms of the sounds than men as long as the forms are not socially stigmatized. With respect to the current topic of the /o/-raising, studies have found that more female speakers than male speakers produced /o/ vowels with low F1 values almost overlapping with those of /u/, indicating that female speakers are progressive in employing the new raised form of /o/ (e.g., Han & Kang, 2013; Seong, 2004). Examining the Korean vowel system globally, other studies also pointed out the tendency that female speakers realized greater F2 differences between /o/ and /u/, while male speakers tended to rely on F1 differences (e.g., Kang & Kong, 2016).
Even beyond the gender group characteristics, there can be individual differences in processing speech depending on their cognitive ability (e.g., working memory: Gordon-Salant & Cole, 2016; Janse & Jesse, 2014; inhibitory control: Bank et al., 2015; Lev-Ari & Peperkamp, 2013; attention shift: Kong & Edwards, 2016). Janse & Jesse (2014) found that working memory capacity as well as age affected old adults’ ability to use context information in the spoken- word recognition, which reliably indicates one’s overall listening performance. Old adult listeners with better verbal working memory skills (better at storing new and updating old information in memory) performed better in recognizing spoken words by utilizing contextual probability information. Other types of executive function capacity such as inhibition control turned out to be associated with less influence of a foreign language on the learners’ use of their first language because better inhibitory control helped the foreign language learners to suppress irrelevant information of non-native language when they were in the L1 context. As for the ability to shift attention, Kong & Edwards (2016) reported the tendency that the English listeners having better cognitive flexibility were likely to process the speech signal gradiently (or less categorically) utilizing the redundant acoustic information more than others.
Similar to evidence related to cognitive ability measured by executive functions, Stewart & Ota (2008) reported that for neurotypical adults, perceptual shift to existing words (namely Ganong Effect) in the identification task was weakened as a function of autistic traits. Autistic traits are related to symptoms of autism, abnormalities in social and communication development (e.g., Baron-Cohen et al., 2001). Within the normal range of autism spectrum, the adult listeners with higher autism spectrum quotients were less subject to the lexical bias in the speech processing, indicating that the listeners’ ability to incorporate contextual knowledge can be a source of individual differences in the speech processing.
Yu and his colleagues (2010, 2011) probed this individual-level interaction with sound variations specifically aiming to demonstrate the social dynamics of the sound change. In Yu et al. (2011), they investigated how individual listeners with a range of autism spectrum quotient would parse context-induced variations of the speech sounds. In identifying /s/ and /ʃ/ preceded by consonants /r, l/ or vowels /a, i, u/, neurotypical listeners with higher autistic traits were less affected by phonotactic context of the sibilants in English. The studies proposed that listeners’ inherent features of autism spectrum quotients might possibly explain the way the speakers/ listeners interact with the new sound forms in the acoustically variable contexts.
Supporting Yu’s proposal, Lee & Kong (2016) showed that individuals with better executive function capacity were more likely to maintain the conservative phonetic cue along with the innovative cue in their perceptual representations of the sound categories. In distinguishing /t/ from /th/, laryngeal stop categories in Korean known to undergo a sound change, listeners with higher working memory were more sensitive to a conservative acoustic cue of VOT compared to those with lower working memory, presumably because they are better at storing old information as well as new information associated with the linguistic contrast. Both Lee & Kong (2016) and Yu et al. (2011) demonstrated that individual differences in cognitive capacities could, in part, account for an introduction and use of innovative forms of the sound, which would result in the sound change in the speech community.
Inspired by experimental evidence so far, the current study aims to look into the on-going sound change of the /o/-/u/ contrast in Seoul Korean focusing ton interactions with individual speakers’ traits and cognitive ability to utilize the acoustic information. We question who in the community would be more likely to employ the innovative sub-phonemic acoustic variable (F2) or to insist the old acoustic variable (F1) for the realization of the /o/-/u/ contrast. As prior findings suggest poor ability of individuals with higher autistic traits in reflecting contextual variations, we predict a greater weighting on F2 in the production of /o/ and /u/ vowels would be associated with the speakers with higher autistic traits who are less rigidly tied to existing representations of the categories. As regards cognitive ability, the findings from previous research render us hypothesize that more uses of F1 would be associated with speakers with better working memory. That is, we expect that the better capacity to hold and control multiple information would enable the speakers to better utilize an old conservative cue along with a new innovative cue.
Besides working memory, we also examine how the individual differences in inhibition and attention shift ability would be related to the use of acoustic variables for the /o/-/u/ contrast. While the lack of existing experimental works makes it difficult to predict the role of these two executive function capacities in the speakers’ utilizations of the acoustic variables, we picture that the speakers with better executive function controls are able to accommodate more cues to manifest the vowel contrast. Our goal is to test the hypotheses regarding the relationship in order to better understand the individual level interactions with synchronic sound variations. In combination with gender differences in the sound change (i.e., progressive women and conservative men in general), it is of our interest to look into cognitive modulations of multiple acoustic cues (F1 and F2) in each gender. Through this novel attempt, we aim to better understand the linguistic nature and the social dynamics of sound changes in progress in the Korean vowels.
2. Method
The data for this study were a subset of word productions originally designed and collected for an obstruent study (Kong et al., 2014). The production database provided recordings of fifty five college students (F=27, age range: 20-27), native Korean speakers of Seoul Korean with no reported history of hearing or language problems. In terms of the task, the productions were elicited by participants’ reading a list of words (310 words in total) written on a piece of paper over the microphone (Shure SM81) and recorded using digital recorder (Marantz PMD 661) at the digitization setting of 44,100 Hz sampling rate and 16 bit quantization.
Sixty words were chosen from the production database to examine acoustic realizations of the target vowels /o/ and /u/: 33 /o/-target words, and 26 /u/-target words. The words were di-/tri-/ quadri-syllabic where the two target vowels were located in the first or second syllable. The target vowels were preceded by obstruents (/t, t’, th, s, s’, tɕ, t’ɕ, tɕh/) either in an open or closed syllable: e.g., /to.ma/ ‘cutting board’, /tɕi.to/ ‘map’, /thu.su/ ‘pitcher’, /tɕil.thu/ ‘jealousy’.
The first two formants (F1 and F2) were measured at the center of vowel duration. For the formant extraction, each target words were pre-processed manually by the authors to identify the vocalic onset and end of the vowels. The voicing onset was defined as a zero- crossed time-point at the beginning of the first upswing wave after the consonant onset. The end of the vowel was indicated by the disappearance of the first and second vowel formants. Once the boundaries of /o/ and /u/ were event-marked, the vowel mid-points were identified automatically by the script in Praat (Boersma & Weenink, 2018), the analysis platform where the formant values were assessed. It is noted that fully or partially devoiced vowels were visually inspected by the researchers to be eliminated from the data set of acoustic analysis. Besides devoiced vowels, the acoustic analysis also excluded the tokens less than 50 ms long to ensure reliable F1 and F2 values. This process yielded 2,449 vowels (/o/: 1,476, /u/: 973) with reliable formant values ready for the statistical analysis.
Three types of logistic mixed-effects regressions were constructed to examine the role of F1 and F2 cues in differentiating the targets /o/ and /u/: Model-F1, Model-F2, and Model-F1F2. While all three models were designed to predict the two vowel categories (/o/ and /u/), they differed in the number of fixed variables. The Model-F1 predicted one vowel over the other simply with a F1 parameter, and the Model-F2 simply with a F2 parameter. The Model F1F2 was slightly more complex in that it predicted the target vowels by having two fixed variables of F1 and F2. The three models considered random slope(s) of the formant variables at the speaker level but did not allow a random intercept in order to attribute the variation to the acoustic parameter as much as possible.
Accuracies of the two simple models, i.e., Model-F1 and Model- F2, were calculated by counting the matches between the target vowels and the predicted vowels from the model: fitted (Model-F1), and fitted (Model-F2). Besides the accuracy of the simple models, the random coefficients of F1 and F2 from the complex model (Model-F1F2) were considered as individual speakers’ relative reliance on each acoustic variant in their productions of /o/ and /u/. The statistical analyses were performed at R platform using lme4 package (Bates et al., 2015; R Core Team, 2017).
Three tasks of measuring executive function capacity (EF) were administered to the participants (e.g., Diamond, 2013; Miyake et al., 2000): Digit N-Back for working memory, Stroop for inhibition control, Trail-Making Task (TMT) for attention shift (or mental flexibility). Digit N-Back task aims to measure working memory capacity, an ability to process one information while holding other information (Baddeley, 2003 among others). Consisting of three sequential sessions, the Digit N-Back task asked participants to determine fast and accurately whether or not the number on the current slide is identical to the one on the previous slide (1-Back), the one on the two slides before (2-Back) and the one on the three slides before (3-Back). Programmed in the stimuli presentation tool of E-Prime software (Psychology Software Tools, Pittsburgh, PA, 2012) each session contained 10 trials of match (target trials) and 30 trials of mismatch between numbers. Correct responses of (1) target match-trial and (2) total trials were counted, respectively, to represent how good their WM is. In the Stroop task, participants were instructed to fast and accurately identify the font color of the letters on the screen and respond by choosing one of the four option colors (Eriksen & Eriksen, 1974). 40 trials out of total 80 trials displayed color names congruent with font colors (i.e., “빨강” red in red), while 12 trials showed color names incongruent with font colors (i.e., “빨강” red in green). The rest of the trials presented nouns irrelevant to colors or nonce words. Reaction time of congruent and incongruent trials was collected by E-Prime software to indicate their performance of inhibition control. Finally, participants were given a paper-and-pencil version of TMT where they connect numbers in sequence from 1–14 (TMT-number), letter in sequence from 가–하 (TMT-letter), and number-letter sequences (i.e., 1→가→2→나 and so forth, TMT-NL)(Arnett & Labovitz, 1995). The total duration of each session was measured manually by the researcher using a stop-watch to indicate abilities of attention switch.
Besides, the participants completed a written survey of 50 questions designed to quantify Autism Spectrum Quotients (ASQ, Baron-Cohen et al., 2001). While scores of the survey turned out to be distributed at a normal range of autistic spectrum, higher scores indicate more autistic traits. Fifty survey questions were further divided into subcomponents indicating social skills, attention to local details, attention switch, communication, and imagination. We estimated the scores of each sub-area of autistic traits so that the averaged trend can be confirmed by specific autistic characteristics.
The numeric indices of individual traits collected from EF tasks and ASQ survey were correlated with the coefficients of each acoustic variable from the production models. Taking a potential correlation between multiple variables of the mixed effects model (i.e., F1 and F2) into consideration, we controlled for F2 coefficients in estimating the correlation coefficients between F1 and each of task scores and vice versa. A series of partial correlation tests were performed using ppcor in the R platform (Kim, 2015).
3. Results
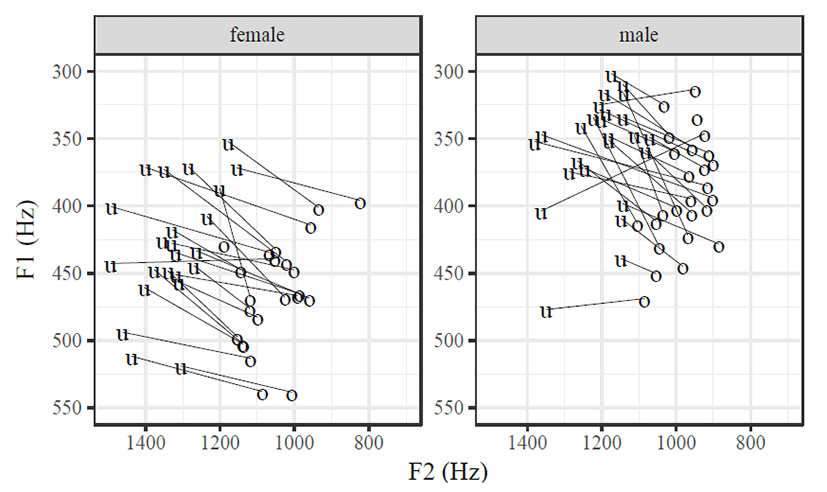
Figure 1 depicts distributions of F1 and F2 mean values of /o/ and /u/ produced by each speaker. Separated by gender, the two panels show in common that /o/ differed from /u/ not just along the F1 dimension but also the F2 dimension as the connected lines between the vowels were slightly tilted rather than straightly vertical or horizontal. Although not verified in a statistical term, however, the female speakers’ lines at the left panel tended to exhibit more horizontal angles (implying greater role of tongue advancement for a /o/-/u/ distinction), whereas there were many numbers of male speakers whose connecting lines were rather vertical (implying greater role of tongue height for a /o/-/u/ distinction). This observation is consistent with Han & Kang (2013) in that female speakers were advanced in adapting the new acoustic parameters (F2) for the /o/-/u/ contrast.
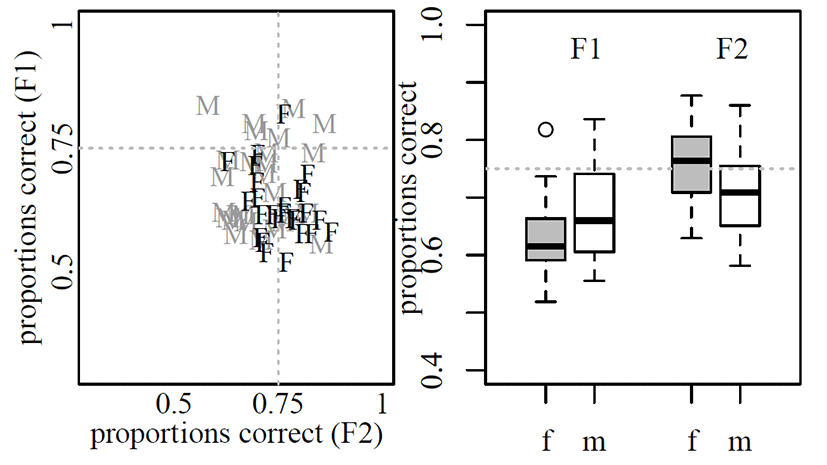
Outputs of the two simple models (Model-F1, and Model-F2) showed that accuracies of predicting /o/ and /u/ categories were considerably high even with a single acoustic dimension. Mean accuracies of the Model-F1 were 64% and 68% for females and males, respectively, and those of F2-model were 75% and 73% for females and males, respectively. Figure 2 displays the accuracies of Model-F1 against those of Model-F2 (left) and interquartile ranges of accuracies by gender (right). The distribution of accuracies revealed that Model-F1 accuracy based on females’ productions was overall lower than that of males’ while Model-F2 accuracy was higher than that of males’. There was only one female speaker (vs. 5 male speakers) whose Model-F1 accuracy proportion was above .75. By contrast, there were 13 female speakers (vs. 11 male speakers) whose Model-F2 accuracy proportion was above .75. This suggests that F2 was more effective than F1 in identifying female individuals’ /o/ and /u/ compared to the patterns in male speaker’s production models.
Outputs of a complex model with both F1 and F2 as fixed variables were visualized at Figure 3. Statistical results yielded significant coefficients of F1 and F2 variables. According to the model of female speakers’ production, /u/ were identified over /o/ as F1 values decreased (β=–1.19, SE=0.14, p<.0001), and F2 values increased (β=1.88, SE=0.16, p<.0001). The magnitude of F2 coefficient was greater than that of F1 coefficient indicating that female speakers’ /u/ and /o/ were more effectively differentiated by F2 than F1. A steeper slope of F2 than F1 in the leftmost panel of Figure 3 illustrates the relative effect of the parameters in the female model.
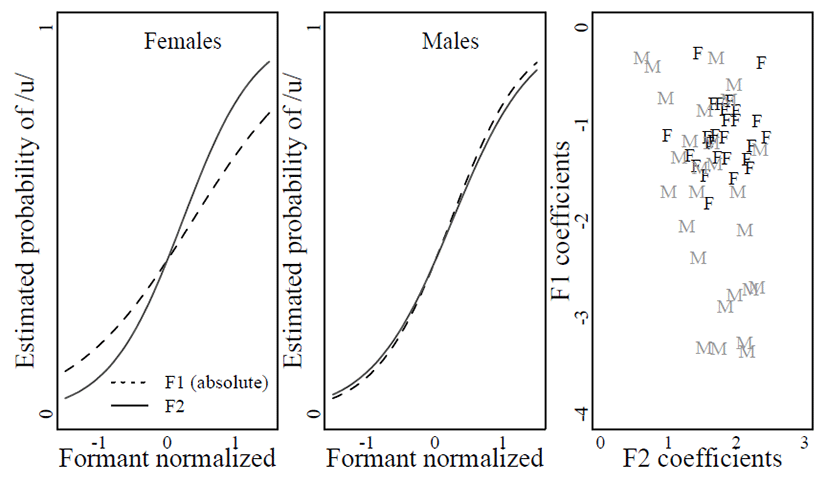
The complex model of males’ productions revealed coefficients of F1 and F2 with little magnitude difference, unlike the females’ complex model. The magnitude of F1 coefficient (β=–1.83, SE=0.30, p<.0001) was even slightly higher than that of F2 (β=1.80, SE=0.19, p<.0001), suggesting that F1 was almost equally as effective as F2 in distinguishing male speakers’ /u/ from /o/. The center panel of Figure 3 displays the logistic curves of F1 as steep as F2, irrespective of the sign.
The gender-differentiated patterns of cue-weighting between F1 and F2 were confirmed in the individual patterns when the coefficients were plotted against each other, as shown in Figure 3-right. Female individuals’ coefficients were narrowly clustered at the low magnitude of F1 (near zero at the y-axis) and the high magnitude of F2, whereas male individuals’ F1 random coefficients were distributed widely covering both low and high magnitude range of F1 coefficients.
Taken together, all statistical models currently considered (two simple models of measuring accuracy of each acoustic dimension (F1 and F2), and one complex model of estimating the relative role of the two acoustic cues F1 and F2) appeared to exhibit two patterns in common. First, both F1 and F2 played important roles in differentiating /u/ from /o/ for males and female speakers. Second, there was a gender-separated pattern that female speakers relied less on F1 than F2, whereas male speakers depended on F1 and F2 almost equally. Furthermore, male speakers with greater use of F2 utilized F1 more than others. Considering the sociolinguistic context where the acoustic characteristics of the /u/-/o/ contrast are changing, the current results support that females are more adaptive to an innovative trend (role of F2 greater than F1) for the contrast than males, and females are less likely to adhere to the old cue (F1) in producing the vowels /u/ and /o/.
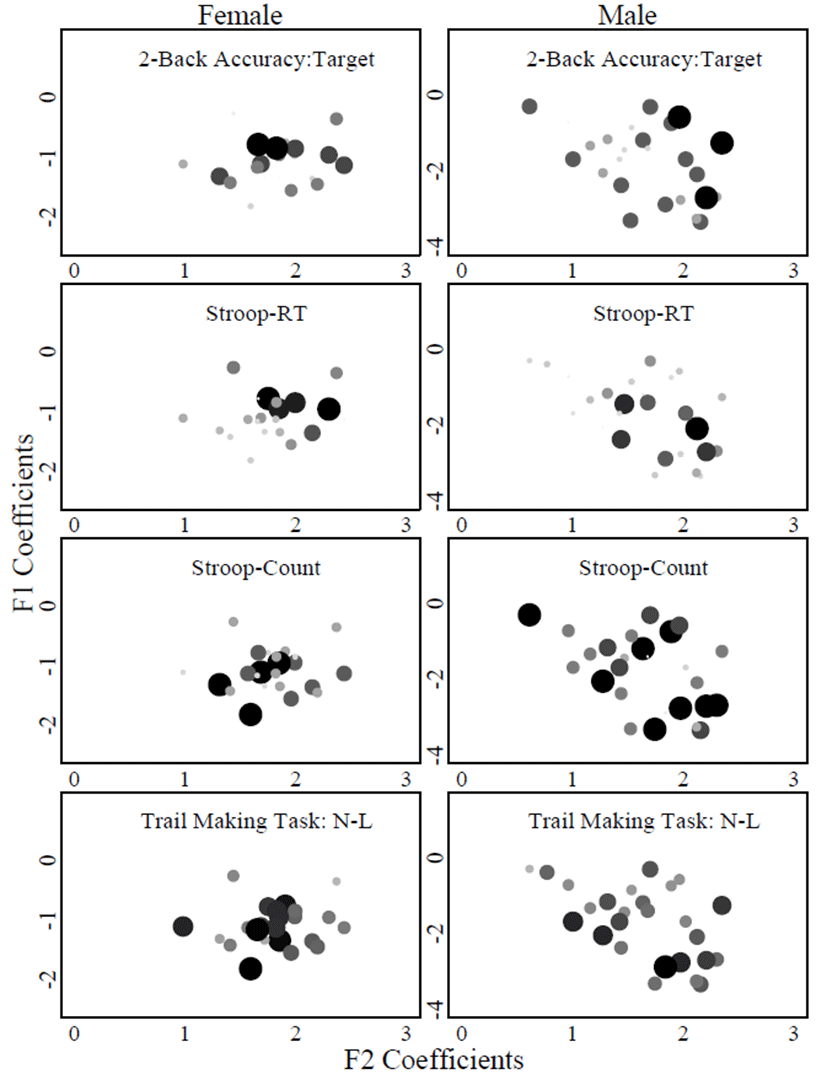
Table 1 summarized outputs of the partial correlation tests between model-estimated coefficients of acoustic variables (F1 and F2) and each of EF task scores. Figure 4 visualizes the distributions of F1 and F2 coefficients with the varying size of plot characters indicating the EF scores. For female speakers, no statistically significant correlations were found between individual speakers’ coefficients of F1 or F2 and EF task scores at the reference significance level of p<.05. Nevertheless, two marginally significant relationships were found (1) between F1 coefficients and accuracy scores of Stroop task, and (2) between F1 coefficients and response times of TMT. This negative correlation coefficient between F1 use and Stroop performance shows a tendency that greater reliance on F1 (lower F1 coefficients) was associated with better performance in the Stroop task. Likewise, lower F1 was associated with faster completion of TMT (Number-Letter Sequence), revealing a tendency that the speakers with greater F1 use performed better in the TMT task. Although not robust in statistical terms, it was a F1 dimension that exhibited consistent individual differences in correlating with cognitive controls. The directions of individual differences were also consistent in that better cognitive abilities (i.e., inhibition control and attention shift) were associated with more use of the F1 cue.
Unlike tendencies observed in female speakers, it was a F2 dimension that revealed consistent individual differences with respect to the EF task performance. Greater F2 coefficients were associated with higher WM scores (r=.44, p<.05) and faster Stroop response time (r=–.47, p<.05), indicating that male speakers with higher executive function capacity (i.e., better working memory and inhibition control) tended to use F2 cue more than others with lower executive function capacity. No statistically consistent individual difference was found with F1 coefficients in male speakers.
When separated by sub-categories of ASQ survey questions, there was no consistent individual difference in speakers’ F1 & F2 coefficients and ASQ scores at the significance level of p<.05 (see Table 2). The strongest correlation was found between female’s social skills and their use of F2 where better social skills were associated with less use of F2: r=.369, p=0.082. Scores of any ASQ sub-categories were not correlated with female speakers’ uses of F1 nor with male speakers’ uses of F1 and F2.
4. Discussion & Conclusion
The present study explored whether and how Korean speakers’ relative uses of acoustic variables for a /u/-/o/ contrast are related to speakers’ individual characteristics such as cognitive capacity and individual traits measured by autistic spectrum quotients. Acoustic examinations showed that Korean young adults produced the target vowels /u/ and /o/ distinctively along F2 dimension as well as F1 dimension, which is congruent with recent documentations of the changes in /o/-/u/ vowels as a shift in the acoustic space (e.g., Kang, 2014; Kang & Kong, 2016; Lee et al., 2016; Lee et al., 2017) but rules out a view of this change as a merge (Han et al., 2013; Han & Kang, 2013).
One contribution of the current study is that we showed an experimental evidence of the vowel shift at the individual level, which subsequently revealed a gender-differentiated pattern at the group level. While speakers in general utilized the acoustic dimension of F2 by realizing a /u/-/o/ contrast with a front-back difference, there were more male speakers than female speakers who utilized the acoustic dimension (F1) as importantly as they did so with the acoustic dimension (F2). This finding is consistent with existing studies investigating the same target vowels in Korean (e.g., Han & Kang, 2013) in that the male speakers were less progressive in adopting the new forms of sound in their productions. Given the context of vowel-shifts in Korean where the /u/-/o/ vowels became contrastive less in terms of height (but more in terms of advancement), the association of male speakers with the tendency of maintaining a height contrast for the /u/-/o/ contrast supports the claim that men are generally behind women in the sound change (Labov, 1990).
Similar to the gender difference in the acoustic realizations of a /u/-/o/ contrast, there also was a gender-related difference in how the individual variabilities of utilizing these two acoustic dimensions are systematically related to their cognitive abilities or individual traits. On one hand, our male speakers exhibited systematic variabilities in using F2 in a way that those with better executive function capacities (indicated by better working memory and better inhibition control) tended to utilize the innovative acoustic dimension more in realizing /u/ contrastively with /o/. One way to understand this relationship concerns with previous findings that the speakers with better cognitive ability are better at controlling multiple acoustic information including redundant components (e.g., Kong & Edwards, 2016). As the gender-differentiated acoustic patterns suggest, F2 might serve as a new acoustic dimension while F1 distinguished /u/ vowels from /o/ vowels primarily. In this speech community where the sound change is still in progress, cognitive ability such as executive function controls might facilitate the male speakers to accommodate newly available acoustic information to achieve a vowel contrast while maintaining previously important information. That is, for the male speakers, the source of individual differences in realizing a /u/-/o/ contrast in Seoul Korean existed in terms of how they adopt the innovative acoustic information, i.e., the F2 dimension.
On the other hand, our female speakers showed a somewhat consistent association of more use of F1 with better control of executive function. Although statistically weak, this relationship is in line with how cognitive ability affects speakers in utilizing redundant information in their speech for a linguistic contrast. Recall that the female speakers of the current study used F2 more than F1, indicating that F1 played a secondary role in realizing the contrast between /u/ and /o/ in this speaker group at an advanced stage of sound change. Given the group characteristics, better executive function might have helped the female speakers utilize redundant information of F1 in their production of /u/ and /o/ vowels. Unlike male speakers, systematic individual differences among female speakers resided in their differential uses of the old acoustic information, i.e., the F1 dimension.
Taken together, comprehensive understanding of the current results is stated when we properly take the gender group differences into consideration. While we found consistent relationship between cognitive abilities and speech production patterns across participants, the relevant acoustic information and the direction of the relationship differed depending on how advanced individual speakers are in the sound change context of the target vowels. Whether the speakers are ahead or behind of the trend of sound change taking place in the speech community, their cognitive ability influenced utilization of acoustic information which is non-primary or redundant to them. Our findings add experimental evidence to existing literature arguing that individual differences of a language use can be explained by their cognitive abilities.
Contrary to the executive function capacities, individual traits measured by ASQ questionnaire were not successful factors to explain individual variabilities of speech production patterns. Correlation tests failed to yield coefficients with a statistical significance and to provide the direction of the relations consistent across the sub-components of ASQ survey. We do not seem to have clear explanation of these failures: it could be attributed to a small sample, or to a way too simple analysis method of correlation or to a true lack of correlation between the variables. Perhaps, we should have used different types of tasks or surveys than ASQ questions by Baron-Cohen et al. (2001). As long as the current study did not disprove the individual traits as a possible factor, our current failures should not prevent us from pursuing further experimental studies in order to extend our understanding of what drives sound change in the speech community.
Finally, we should add a cautionary remark that current discussion of experimental findings is based on much relaxed interpretation of the correlation analyses whose statistical effects might be less important if one takes a conservative attitude towards the performance of multiple correlation tests. For example, we interpreted those marginally significant coefficients (.05<p<.1) at Table 1-female as meaningful outputs. And we also did not apply Bonferroni correction in our set of multiple correlation tests, which is known to make an acceptance level of null-hypothesis redefined (or lowered) accommodating the number of repeated variables. Regardless of attitudes towards statistical significance, what we consider important is that the consistent tendency of production associated with cognitive ability should not be underestimated. It needs to be highlighted that individual cognitive differences might be worth investigating further in order to better understand the dynamic mechanism of sound change in the speech community with the language users counted as useful agents of the change. Further research would improve our understanding yielding more reliable outputs when equipped with refined analysis methods and more relevant tasks of measuring cognitive abilities and individual traits.