





1. 서론
자음과 모음을 얼마나 정확하게 조음하였는가에 따라서 조음정확도와 명료도가 결정된다. 말을 정확하게 하기 위해서 입을 크게 벌리고 조음하라는 것은 자음과 모음 중에서 모음을 강조한 말이다(박상희, 2011). 모음은 혀의 높이와 혀의 위치에 따라 달리 공명되어 산출된다. 성도의 공명주파수로 정의되는 포먼트를 활용하여 모음을 효율적으로 분석할 수 있는데(성철재, 2005) 특히 첫 번째 공명주파수(F1)와 두 번째 공명주파수( F2)를 이용하여 조음과의 연관성을 밝혀낼 수 있다(Fry, 1982). 한국어에 대한 실험음성학적 연구가 시작된 이래 포먼트 값을 이용하여 모음의 특징을 기술하고자 하는 많은 시도가 이어져 오고 있으나 아직까지는 성인에게 초점이 맞추어져 있고, 아동에 대한 분석적 연구는 그리 많지 않다. 특히 모음을 객관적으로 평가할 수 있는 포먼트 분석은 아동의 모음 연구에 많이 응용되지 못하였다(조소형, 2010; Walton & Pollock, 1993).
아동은 성인에 비해 모음이 생성되는 조음공간이 작기 때문에 모음을 분석할 때 그 세심한 차이를 측정하기에 어려움이 있다(박성지, 2008). 아동의 성도는 성인과 달리 성도와 인두강의 길이가 짧고, 혀도 앞쪽에 위치한다. 또한 성인의 구인두강이 직각인 반면, 영아는 완만한 곡선의 형태로 후두의 위치도 성인에 비해 높게 위치한다. 후두개와 구개 범인두근이 가깝게 위치하기 때문에 성인과 아동은 음향음성학적으로 차이를 보일 수밖에 없다(배재연 & 고도흥, 2010). 이러한 이유로 아동 모음의 전반적인 분석 주파수 범위는 음성 분석에서 매우 중요한 고려사항이 된다(Kent & Read, 2002). 또한 아동 음성은 기본 주파수 범위가 넓고, 예상치 못한 비음화나 다양한 음성자질 등의 영향이 포먼트 분석 결과 해석에 개입될 가능성이 있어 연구에 어려움을 주기도 한다(Kent & Read, 2002).
음향 분석은 말소리를 객관적으로 수치화하고 진단과 치료 효과 판정에 사용될 수 있기 때문에 성인뿐만 아니라 아동 음성의 음향 분석 역시 필수적이라 할 수 있다(이재령, 2017; 진성민, 2004). 송인미 & 성철재(2018)와 심화영 외(2016)에서도 조음 치료 시 모음의 음향음성학적 변수들인 모음 삼각도, 모음 사각도, 모음 간 유클리드 거리 등이 치료의 객관성을 확보할 수 있는 민감한 지표로 활용될 수 있다고 하였다. 또한 박성지(2008)는 아동 모음 오류 분석에 있어 모음의 정확한 조음위치나 모음조음의 조음경향을 분석하는 방법으로 포먼트를 이용한 분석이 효과적임을 밝혔다.
그러나 아동 모음의 포먼트를 임상현장에서 직접 측정하고 이용함에 상당한 어려움이 있다. CSL(computerized speech lab, KAY, USA)은 성도길이가 서로 다른 성인 남, 녀, 아동을 구분하여 측정하게끔 하는 세팅 조건을 설정할 수 없고, Dr. Speech (TigerDRS, USA)는 약간의 세팅을 허용하나 Praat(Boersma & Weenink, 2014, Netherlands)과 같은 정교한 세팅을 할 수 없다. 무엇보다 이들 장비는 상당한 금액을 지불해야 하는 상업용 프로그램이라는 약점이 있다. 무료 소프트웨어인 Praat을 이용하면 되지만, 매뉴얼에 성인용 세팅 조건은 권고되어 있어도 아동에 대한 부분은 명시적이지 않다. 분석 최대 포먼트 주파수를 5,500 이상 8,000 Hz 정도로 하라는 애매한 권고에 그쳐 있다. 그 외 무료 소프트웨어인 WaveSurfer(Beskow & Sjolander, 2000, KTH, Sweden)는 포먼트 세팅을 할 수 있는 모듈이 없다. 그러므로 아동 언어재활에서, 임상적 접근이 쉬운 동시에 포먼트 측정이 용이하고, 모음의 조음 오류 분석 및 치료 효과를 현장에서 확인할 수 있는 도구의 개발이 필요함을 알 수 있다.
Praat은 말소리를 대상으로 하는 연구에서 음성자료 분석을 위해 가장 빈번히 사용되는 음성분석 프로그램이다. 이 프로그램은 웹에서 무료로 다운받을 수 있어 연구자와 임상가가 접근하기 용이하고, 음성 분석을 위한 다양한 모듈을 포함하고 있어 연구자의 목적에 따라 분석 스펙트럼이 거의 무한대라는 장점을 가지고 있다. 이러한 이유로 많은 연구자들은 Praat을 이용하여 음성자료 분석을 실시해왔고, 본 연구에서도 이를 이용하여 아동 모음에 대한 최적의 포먼트 분석 방법을 제시하고자 한다.
Escudero et al.(2009)은 Praat 측정 환경에서 최적의 포먼트 분석은 최대 포먼트 주파수(maximum formant)와 포먼트 개수 세팅에 따른 포먼트 측정치의 변이(variance)가 최소일 때 이루어진다고 하였다. 이 견해를 기반으로, 윤태진 & 강윤정(2014)은 성인 한국어 단모음 데이터를 이용하여 각 포먼트 값의 변이를 최소화하는 최적의 세팅으로 검출된 포먼트 값이 사람이 수동으로 측정한 값과 높은 상관관계를 가짐을 밝혔다. 이러한 연구 맥락에서, 포먼트 세팅의 섬세한 변경을 통해 좀 더 정확한 포먼트값을 얻을 수 있다는 개연성이 확보된다. Praat의 포먼트 메뉴 중 To Formant (robust)가 변이(표준편차)와 관련된 입력 옵션 그리고 반복(iteration) 횟수에 대한 옵션을 제공하기는 하나 설정 권고 가이드라인이 없어서 사용이 어렵다.
Praat 매뉴얼에서는 성도의 길이차를 반영한 포먼트 측정을 위해 최대 포먼트 주파수를 성인 여성의 경우 5,500 Hz, 성인 남성의 경우 5,000 Hz로 설정할 것을 권고하였다(Boersma & Weenink, 2014). 그런데 성인의 경우라도 후설 고모음 /오, 우/의 경우는 최대 포먼트 주파수를 약간 낮추어야 더 정확한 값이 얻어진다는 관찰도 있다(김지연 & 성철재, 2016). 그리고 Praat 매뉴얼에서 아동의 경우에는 최대 포먼트 주파수를 8,000 Hz로 설정할 것을 권고한다(Boersma & Weenink, 2014). 이는 아동의 경우, 성인에 비해 성도의 길이가 짧고 성인보다 비교적 높은 주파수로 발성하므로 모든 단모음에서 성인보다 최대 포먼트 값을 높게 설정해야 올바른 포먼트 검출이 가능하기 때문이다(김순옥 & 윤규철, 2015; Yang, 1990). 또한 혀의 전후위치 조음점에 따라 포먼트 값의 변이가 성인에 비해 더 크므로 전설모음, 중설모음, 후설모음군을 구분하여 최대 포먼트 값을 달리 제시할 필요가 있다(김지은, 2015; 송인미 & 성철재, 2018). 따라서, 아동의 경우는 각 모음에 따른 포먼트 세팅 조건을 하나하나 찾아내어야 하고, 성인 데이터의 경우는 적어도 후설고모음의 특이성을 반영한 세팅 조건을 마련해야 할 필요성이 생긴다.
아동의 모음 포먼트를 다루고 있는 김지은(2015)과 송인미 & 성철재(2018)에서는 보다 정확한 포먼트 분석을 하고자 모음에 따라 포먼트 개수와 최대 포먼트를 다르게 설정하였다. 이를 위해 수많은 시행착오 과정을 거쳤다고 하였다. 본 연구는 이러한 수작업이 필요한 시행착오 과정을 겪지 않고 최적의 아동 모음 포먼트 분석을 하기 위한 목적으로 Praat의 최대 포먼트와 포먼트 개수(number of formants) 자동 세팅 스크립트를 구현하였다.
2. 연구방법
Praat에서 제시하는 LPC를 이용한 포먼트 분석 방법 중 Burg 방법이 F1과 F2를 검출하는데 가장 적합하다고 알려져 있다(Childers, 1978; Press et al., 1992). 이 방법은 선택된 사운드 객체에 대해 단구간 스펙트럼 분석을 실시하여 포먼트 객체로 변환한 뒤 포먼트 객체 생성 시 입력된 최대 포먼트 주파수(Maximum frequency)의 두 배로 재표본 추출 과정을 거친 후, 고주파 증폭(Pre-emphasis)을 실시한다. 그리고 각각의 프레임에 가우시안(Gaussian) 분석창을 씌운 뒤, Burg 알고리듬으로 LPC 차수를 계산한다(박한상, 2011). 포먼트 검출 시 0 Hz부터, 설정한 최대 포먼트 이상까지 전체 범위에서 포먼트를 검출하게 되면 그 값이 너무 높거나 낮은 경향을 보이기 때문에 성도 공명과 연관 짓기에 무리가 있다. 그렇기 때문에 Burg 방법에 따른 포먼트 추출 과정은 측정 에러를 최소화하기 위해 50 Hz 이하와, 설정 최대 포먼트 이상의 주파수 성분을 제거한 후에 이루어진다(Boersma & Weenink, 2014). Burg 알고리듬은 Burg(1975)에서 제안된 최대 엔트로피법(maximum entropy method, MEM)을 이용하여 최대 엔트로피 스펙트럼 분석으로 필터계수를 구하여 포먼트를 검출한다. 이 방법은 짧은 음성 자료에 대해 다른 분석 방법과 비교하여 안정된 측정치를 제공한다고 하였다(Childers, 1978; Press et al., 1992).
Windows 10 환경에서 Praat version 5.3.141를 이용하여 아동 모음 연구를 위한 최적의 포먼트 세팅 스크립트를 구현하였다. 1장에서 언급한 바와 같이 최대 포먼트(maximum formant, 이하 max_F)와 포먼트 개수(number of formants, 이하 num_F) 두 가지 조건을 반복문으로 설계하여 알고리듬이 설정한 모든 경우의 수에서 F1 측정치의 변이(F1_SD)와 F2 측정치의 변이(F2_SD) 합이 가장 작은 경우를 찾아 그 때의 최대 포먼트, 포먼트 개수를 최적의 포먼트 세팅 조건으로 간주하였다. 이 연구에서는 F1과 F2 측정치의 변이를 분산값(variance)으로 접근한 Escudero et al.(2009)과 달리 Praat에서 접근하기 용이한 표준편차를 이용하였다. 분산과 표준편차를 각각 이용한 스크립트 세팅 결과는 일치한다. 그러나 praat에서 분산을 이용하는 경우, 하나의 명령어로 구해지는 표준편차에 비해 추가적인 계산과정이 필요하기 때문에 스크립트 구동에 더 효율적인 표준편차를 이용하였다. Escudero et al.(2009)에서는 데이터의 정규화를 고려하여 포먼트의 변이를 로그스케일로 변환하는 과정을 거쳤다. 본 연구 역시 F1, F2 표준편차 값을 로그스케일로 변환한 후 두 값을 합하여 그 값이 최소일 때 두 설정 조건을 검출하였다. 양병화(2006)와 여운승(2006)에서는 데이터의 변이성이 큰 정적 비대칭적 분포는 로그를 이용하여 변환하는 것이 적합하다고 하였다. 로그 스케일 변환은 편포된 데이터 간의 편차를 감소시켜 왜도를 줄여 정규성을 높임으로써 편포된 데이터로 인한 분석 왜곡 위험성을 줄일 수 있다. 두 값을 합하여 최소의 경우를 찾는 것은 F1, F2에 동일한 가중을 두기 위함이다.
분석조건에 활용되는 한국어 모음은 7모음 체계(아, 에 이, 오, 우, 으, 어)를 채택하였다(배주채, 2003). 이를 위하여 다음 방식의 스크립트로 알고리듬을 서로 다르게 설계하여 접근하였다.
첫 번째 스크립트는 Praat 매뉴얼의 권고에 따라 포먼트를 검출하도록 하였다. 즉, 모든 모음에 대하여 고정적으로 최대 포먼트 8,000 Hz, 포먼트 개수 5로 설정 후 포먼트를 검출한다(fixed_script로 명명).
두 번째 스크립트에서는 관련 선행연구를 참고하여(김지은, 2015; 송인미 & 성철재, 2018) 전설성(vowel frontness)을 고려한 모음 집단별로 서로 다른 최대 포먼트 세팅을 하였다(표 1). 포먼트 개수는 4부터 7까지 0.5 단위2로 증가하는 7가지 경우의 수로 상위 for 반복문에 먼저 설계하고, 최대 포먼트는 모음별로 100 Hz씩 증가하는 30가지 경우의 수로 하위 for 반복문에 배치하였다. 결과적으로 하나의 모음에 대하여 총 210(=30×7)가지 경우의 수에서 최적의 세팅 조건을 찾고 그에 상응한 포먼트 값을 출력해낸다(optimum_script로 명명).
세 번째 스크립트에서는 앞서 모음별로 다르게 제시했던 최대 포먼트 설정범위를 하나의 조건으로 통합하였는데 결과적으로 4,500 Hz에서 11,400 Hz까지 70회 반복문으로 구현되는 최대 확장형 알고리듬으로 설계되었다. 포먼트 개수를 함께 고려했을 때 총 490(=70×7)가지 경우의 수에서 최적의 세팅 조건을 찾도록 하였다(broad_script로 명명).
그리고 네 번째 스크립트에서는 인간의 청지각적 특성을 고려하여 4분음 척도(quarter-tone scale)를 적용한 스크립트를 구현하였다. 성철재 외(2008)에서 반음 척도(semi-tone scale)는 서양 음악의 음표 높이에 해당하여 사람이 지각하기에 용이한 높낮이 단위이긴 하지만 성조나 억양 등 말소리 신호 주파수대역에서 지각 변별력이 그 절반 단위인 4분음보다는 못함을 보고하였다. 바크(Bark), 멜(Mel), ERB 척도의 경우 말소리 신호의 통상 주파수 범위인 50–500 Hz에서 반음척도, 4분음 척도와 함께 최소 0, 최대 1 dB로 y축을 정규화 하여 비교해 봤을 때, 바크와 ERB는 1단위 차이가 50 Hz 이상에 해당하여 말소리 높낮이 표현에 적합하지 않았으며 멜 척도는 500 Hz 이하에서 선형척도와 별 차이가 없이 나타나서 로그 스케일인 청지각 척도로는 사용하기가 좀 곤란하다(성철재 외, 2008). 따라서 말소리 분석에 가장 합당한 청지각 로그 스케일을 반영하기 위하여 4분음 등비수열이 적용된 최대 포먼트 범위를 설정하였다. 4분음을 적용한 스크립트(qtone_script로 명명)는 최대 포먼트의 경우 공비(common ratio) 를 곱해가는 알고리듬으로 총 14회 반복되며, 포먼트 개수 반복 7회를 고려하면 전체 98(=14×7)회의 반복조건에서 최적의 세팅을 찾게끔 설계되었다. 각 스크립트의 모음별 최대 포먼트 설정 범위는 표 1에 제시하였다.
최적 스크립트(optimum_script)의 핵심 코드는 다음과 같다.
for num to 7
numOf =4 + (num-1) * 0.5
if vowel$ =“a”
call formantset 6500 9400 numOf
elsif vowel$ =“e”
call formantset 8500 11400 numOf
...
endif
procedure formantset range_1 range_2 numOf
for formant_max from range_1 to range_2
select Sound soundObj
To Formant (burg)... 0 numOf formant_max 0.02 50
select Formant soundObj
Rename... ‘formant_max’
Down to Table... no yes 6 no 3 yes 3 yes
select Table 'formant_max'
formant_max =formant_max + 99
endfor
Create Table with column names... 'vowel$'_SD_LIST 30
...Formant_max set_numOf_formants F1_SD F2_SD sumSD
j=1
for formant_max from range_1 to range_2
select Table 'formant_max'
f1_SD =Get standard deviation... F1(Hz)
logf1 =10*log10(f1_SD)
f2_SD =Get standard deviation... F2(Hz)
logf2=10*log10(f2_SD)
sumSD=logf1 + logf2
select Table 'vowel$'_SD_LIST
Set numeric value... j Formant_max formant_max
Set numeric value... j set_numOf_formants numOf
Set numeric value... j F1_SD f1_SD
Set numeric value... j F2_SD f2_SD
Set numeric value... j sumSD sumSD
formant_max=formant_max + 99
j=j + 1
endfor
select Table 'vowel$'_SD_LIST
sum_min=Get minimum... sumSD
fin_row=Search column... sumSD 'sum_min'
fin_formant=Get value... fin_row Formant_max
fin_F1SD=Get value... fin_row F1_SD
fin_F2SD=Get value... fin_row F2_SD
fin_sum=Get value... fin_row sumSD
...
endproc
...
endfor
상위 for 반복문에서 포먼트 개수를 의미하는 num의 초기 값을 4로 설정하고, 공차가 0.5인 등차수열을 이용하여 numOf를 계산하여 이 값을 4부터 7까지 반복한다. If 조건문을 이용하여 각 모음마다 최대 포먼트 설정 범위가 다르게 구성되고, if 조건문 이하에 subroutine인 procedure와 상호 커뮤니케이션하면서 최대 주파수를 찾고 포먼트 검출과정을 수행하도록 한다. procedure 내 하위 for 반복문의 변수는 최대 포먼트 formant_max로 초기 값인 range_1부터 상한 값 range_2까지 100 단위로 변수 값이 증가하면서 이하 과정을 반복한다.
이 과정에서 제1포먼트와 제2포먼트의 표준편차 F1_SD와 F2_SD를 산출하고 로그변환 후 두 값의 합이 최소일 때의 최대 포먼트를 찾는다. 상위 for 반복문에서 위 과정들을 반복하며 포먼트 개수마다 앞선 과정에서 찾아낸 최적의 최대 포먼트를 적용하여 로그변환된 F1_SD와 F2_SD의 합이 최소인 조건을 찾도록 한다. 마지막으로 최적의 포먼트 세팅으로 확정된 최대 포먼트와 포먼트 개수를 설정 값으로 하여 포먼트 분석을 실시하고, printline 명령을 이용하여 포먼트 관련 변수를 화면에 출력한다.
Optimum_script의 주요 구성에 대한 순서도를 그림 1에 제시하였다.
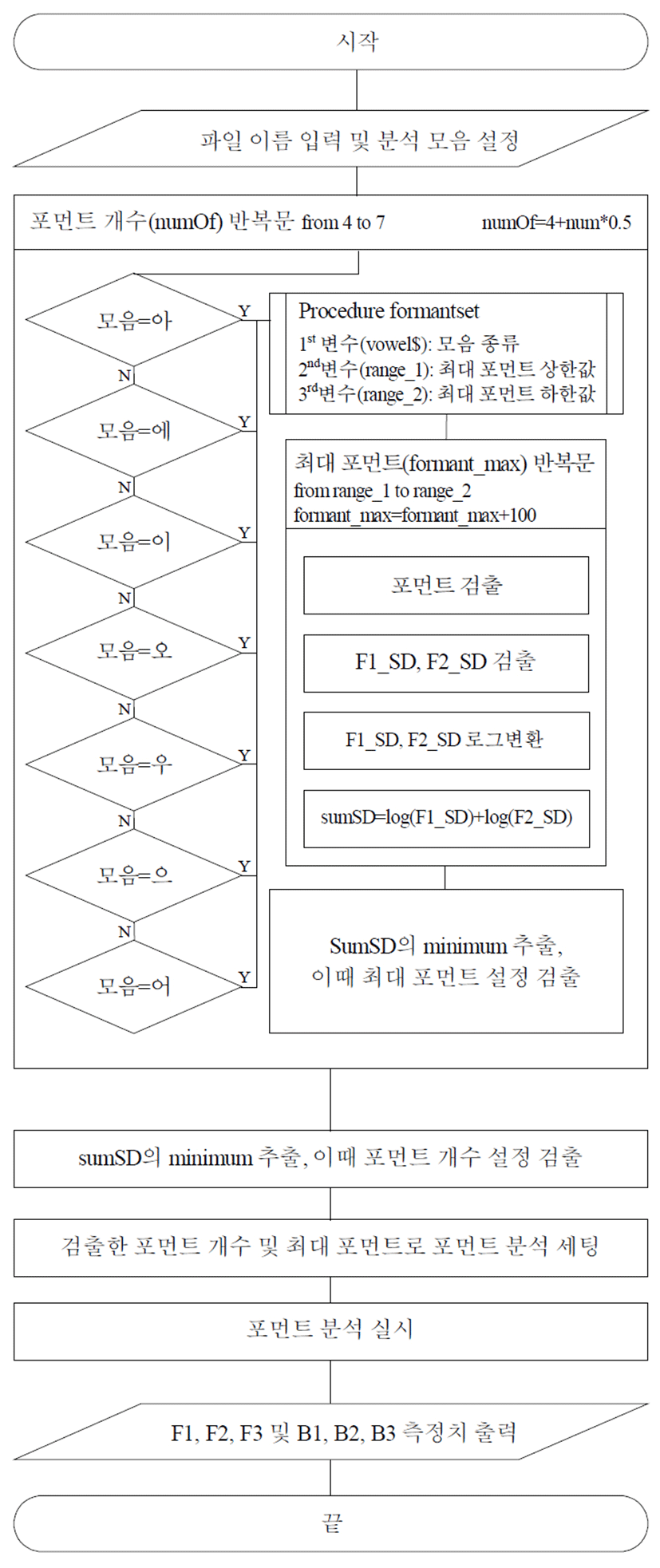
충북 영동에 거주하고 구강조음기관에 이상이 없으며 언어발달 문제가 없다고 보고된 만 6세–6세 9개월 아동 15명(남아 9명, 여아 6명)으로 하였다. 대상자 연령은 음소의 발달이 완전히 습득되는 만 6세에서 7세(6;11)라는 근거를 기반으로 설정하였다(김영태, 1996; 조소형, 2010).
녹음 과제는 한국어 7모음 체계 [아, 에, 이, 오, 우, 으, 어]로 구성하였으며 {모음+다}의 형태로 7가지 단모음을 3회 반복하여 따라 말하도록 하였다. 과제를 {모음+다}로 선정한 것은 자연스럽지 못한 인위적인 운율을 배제하기 위해 문장 틀에 넣어 발화하게 하기 위함이다(성철재, 2005). 선행 모음 연구에서 h_d 환경의 모음을 많이 사용하였으나 우리말에서는 h_d 환경으로 소리를 만들었을 때 ‘흐다, 후다’ 등 평소 사용하지 않는 조합으로 인해 부자연스럽게 느낄 수도 있기 때문에 {모음+다}의 형태로 조음하는 것이 자연스럽다고 판단하였다(문승재, 2007).
음성 수집은 충북 영동 지역 어린이집 1곳에서 진행하였으며, 교실과 분리된 조용한 방에서 실시하였다. 녹음은 TASCAM DR-05(TEAK, USA) 녹음기를 이용하여 44,100 Hz 추출률(sampling rate), 16 bit 양자화(quantization), 모노(mono) 조건 하에서 진행하였다. 녹음기는 아동의 입으로부터 15 cm 정도 간격을 두었으나 아동의 목소리가 작다고 판단되는 경우 연구자가 거리를 조정하며 녹음을 실시하였다. 총 3회 녹음된 음성파일 중 안정적으로 녹음된 음성파일 1회분을 분석대상으로 하였고, 포먼트 분석을 실시하기 위해서 아동의 각 모음 발성 앞, 뒤 1초정도를 제외한 구간을 기준으로 안정적인 펄스 신호가 유지되고, 강도(intensity)가 일정한 부분을 안정구간으로 추출하였다.
3. 연구결과
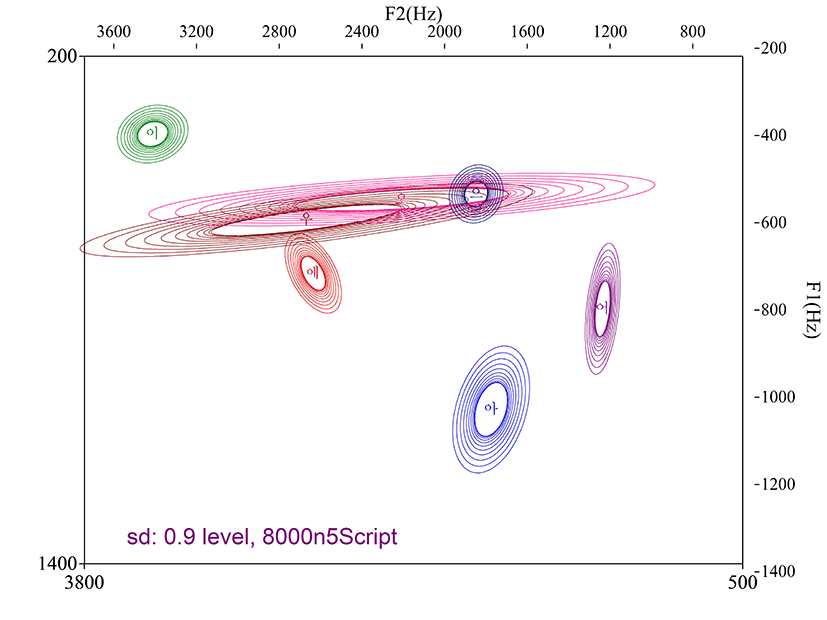
먼저 Praat의 권고 설정에 따른 fixed_script를 이용하여 각 모음별로 측정된 포먼트 분포를 산점도로 확인하였다. 다른 모음에 비하여 특히 후설 고모음 /오, 우/의 영역이 다른 전설 모음, 중설 모음과 분리되지 않고 불안정하게 측정된 것을 볼 수 있다(그림 2).
Optimum_script를 이용한 포먼트 분포를 확인하면 그림 3과 같이 7개 모음의 각 영역이 비교적 뚜렷하게 구분되는 것을 확인할 수 있다.
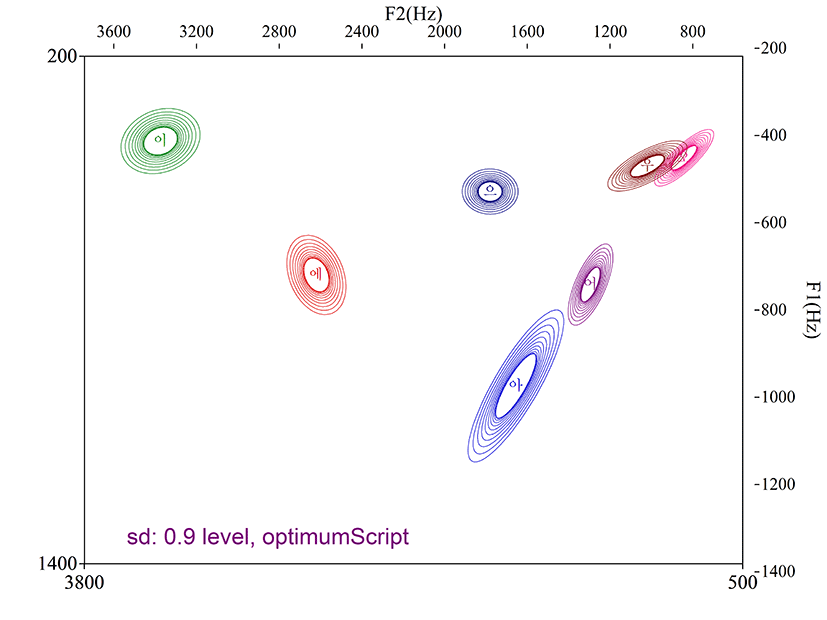
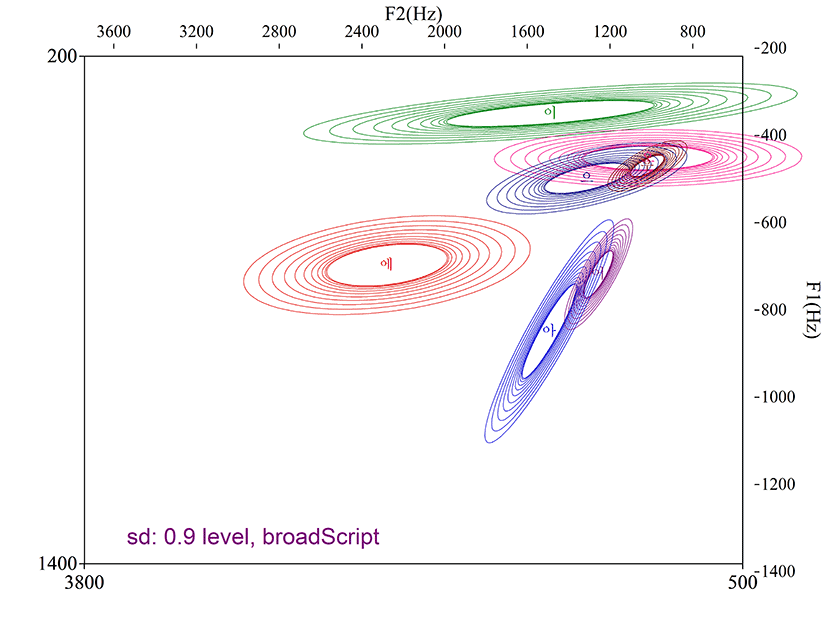
그림 4는 broad_script를 이용한 포먼트 분포다. Fixed_script나 optimum_script와 비교하여 포먼트의 정확한 측정이 어려워 각 모음의 영역 분리가 되지 않고 편차가 크게 나타났다.
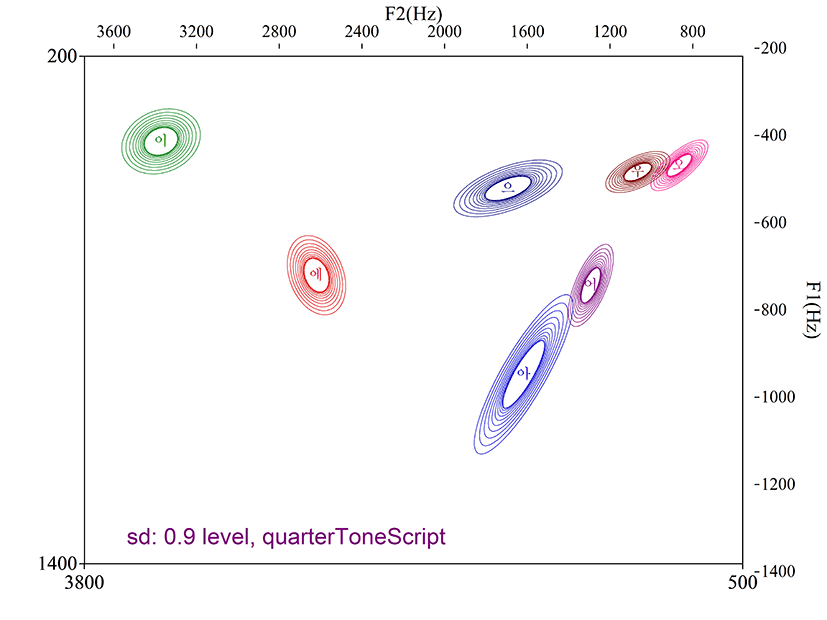
qtone_script를 이용한 포먼트 분포는 그림 5를 통해 확인할 수 있다. Optimum_script의 포먼트 분포와 유사한 형태를 보이며 각 영역이 적절히 분리된 것을 알 수 있다. Optimum_script와 비교하여 /오/와 /우/의 영역은 조금 더 분리되어 있는 반면 /아/와 /으/의 편차 영역이 비교적 크게 측정되고, /아/와 /어/ 영역이 근접하였다.
3개 스크립트(optimum_script, broad_script, qtone_script)를 이용하여 설정된 최적의 포먼트 세팅 조건인 최대 포먼트(max F)와 포먼트 개수(num of F)의 평균과 표준편차를 표 2에 정리하였다. Fixed_script는 모음마다 최대 포먼트, 포먼트 개수를 각각 8,000, 5로 고정하므로 기술통계를 별도로 기술하지 않았다.
Broad_script와 fixed_script에서 각 모음별 포먼트 측정이 매우 불안정하게 이루어진 것을 확인하였다. 따라서 두 스크립트는 고려 대상에서 제외하고, 상대적으로 정확한 측정이 이루어진 것으로 판단되는 두 개의 스크립트 optimum_script와 qtone_script의 포먼트 세팅 결과에 대하여 스크립트 간 차이가 있는지 확인하였다. 표 3에서 제시한 바와 같이, 최대 포먼트와 포먼트 개수는 모든 모음에서 스크립트 간 통계적으로 유의한 차이가 없는 것으로 나타났다.
Fixed_script, broad_script, optimum_script, qtone_script를 각각 이용하여 측정한 모음별 F1, F2의 평균과 표준편차, 최대-최저 범위(range)를 표 4, 표 5에 정리하였다.
Optimum_script와 qtone_script의 포먼트 측정치에 대한 독립표본 t-검정 결과를 표 6에서 확인할 수 있다. 모든 모음에서 통계적으로 유의한 차이가 없는 것으로 나타났으나 /오, 우, 으/의 경우는 1, 2 포먼트에 따라 유의확률 값이 상대적으로 낮은 경우도 관찰된다.
4. 논의 및 결론
아동의 모음 포먼트 분석에 필요한 최적의 세팅 조건을 Praat을 이용하여 스크립트로 구현하는 과정을 기술하였다. 조음 시 혀의 전후 위치를 고려하여 모음군별로 최대 포먼트 설정 범위를 달리한 스크립트(optimum_script)와 모든 모음의 최대 포먼트 설정 범위를 통합한 최대 확장형 스크립트(broad_script), 청지각적 인지 특성을 고려하여 설계한 스크립트(qtone_script), 그리고 Praat의 권고 설정(최대 포먼트: 8,000 Hz, 포먼트 개수: 5)에 따라 구현한 fixed_script를 이용하여 검출된 포먼트의 정확성과 그 분포의 개연성을 포먼트 산점도를 통해 비교하였다. Broad_script와 fixed_script에서 얻은 포먼트 분포는 음성학적으로 용인될 수 없었다. 모음의 개별 특성을 고려하지 않고 고정적인 포먼트 세팅을 실시한 fixed_script의 경우, 원순 후설 고모음 /오/와 /우/가 적절한 측정이 되지 않았음을 확인할 수 있었고(그림 2), broad_script는 모든 모음의 영역이 명확히 분리되지 않고, 넓은 편차 범위를 보이는 것을 확인할 수 있었다(그림 4). Fixed_script와 broad_script에서 검출된 포먼트는 측정치의 편차가 크고 불안정하기 때문에 측정치에 대한 신뢰성이 떨어진다(표 4 참고). 그러나 fixed_script의 경우는 /오,우/에 대한 적절한 설계를 가하면 활용할 수 있는 개연성이 어느 정도는 엿보인다.
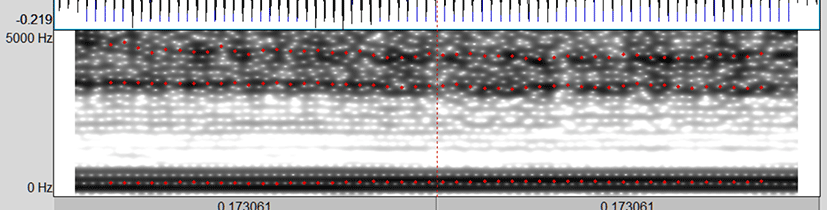
포먼트 산점도를 통해 포먼트를 비교적 안정적으로 검출함이 확인된 optimum_script와 qtone_script에 대해 최적의 포먼트 세팅으로 설정된 최대 포먼트, 포먼트 개수 및 그 결과로 검출된 F1, F2의 스크립트 간 차이를 독립 표본 t-검정을 통해 확인한 결과 두 스크립트는 모든 비교 변수에서 통계적으로 유의한 차이가 없었다. 그림 6은 최대 포먼트 9,600 Hz, 포먼트 개수 7개 조건에서 검출된 포먼트 표준편차 ‘최소’일 경우의 [이] 모음 스펙트로그램 화면이다. F1과 F2를 적절하게 검출했음을 보여준다. 반면 그림 7은 10,300 Hz, 4개 조건에서 검출된, 포먼트 표준편차 ‘최대’일 경우의 [이] 모음이다. F1 위치에서 포먼트의 붉은 가로선이 보이지 않고, F2의 위치도 적절하게 추적하지 못했다.

Optimum_script와 qtone_script에서 찾아낸 표준편차 ‘최소’일 경우의 포먼트 값은 각 모음별 영역의 구분이 명확하고 편차의 양상이 안정적이었다. 둘의 차이를 굳이 지적하자면 포먼트 산점도에서 qtone_script가 optimum_script에 비해 후설 고모음 /오/와 /우/의 영역을 조금 더 잘 구분 짓는 반면(그림 5), /아/와 /으/의 편차 영역은 optimum_script가 더 작고 /아/와 /어/ 영역을 qtone_script보다 더 잘 구분한다는 것이다. 그러나 이는 제한된 토큰수의 데이터만으로 관찰된 산점도 상의 결론일 뿐이고, 통계적으로 두 스크립트는 차이가 없다고 봐야 할 것이다. 선택된 두 스크립트는 여러 선행연구(김지은, 2015; 송인미 & 성철재, 2018)를 기반으로 모음별 특성을 고려하는 최적의 스크립트라 할 수 있다.
아동 포먼트의 경우, 본 연구에서 제시한 높은 성능으로 평가된 방법, 즉 모음 특성에 따라 최대 포먼트 범위와 개수를 다르게 설정하는 포먼트 분석 방법을 이용하여 포먼트를 검출하는 것이 앞으로의 모음 포먼트 연구에 대한 신뢰를 높일 것으로 판단된다. 구현된 아동 포먼트 세팅 스크립트는 입력된 음성자료에 대하여 최적의 포먼트 분석 세팅을 찾고, 이를 이용하여 포먼트 분석을 한 후, 사운드 에디터와 포먼트 정보가 담겨진 정보창(info window)이 모니터에 동시 출력되도록 설계하였다. 이는 언어재활 임상에서 즉석으로 녹음한 아동 모음의 조음 오류 분석이나 치료 효과 확인용으로 유용하게 활용될 수 있을 것이다. 이미 다수의 선행연구에서 포먼트 분석을 통한 음향음성학적 수치들이 아동 모음의 조음 치료에 효율적 지표로 사용 가능하다는 것을 밝혔다(박성지, 2008; 송인미 & 성철재, 2018; 심화영 외, 2016). 따라서 아동 포먼트 세팅 스크립트는 임상에서 아동의 모음 치료와 관련하여 다양한 방식으로 운용 가능할 것으로 보인다.
본 연구는 녹음 대상자를 만 6세로 제한하였기 때문에 후속연구에서는 다양한 아동 연령별로 스크립트의 성능 평가를 실시할 필요가 있을 것으로 생각된다. 이 스크립트의 배포판에서는 연산 시간의 단축을 위하여 두 변수의 반복 횟수를 효율적으로 줄일 계획이다. 데이터를 더 보충하여 평균과 중앙값을 산출한 뒤 이를 근거로 현재 스크립트를 개선하려고 한다. 또한 청지각 특성을 고려한 qtone_script 알고리듬을 연구자들의 연구 목적과 필요에 따라 대화창의 옵션으로 선택할 수 있게 할 계획이다.