





1. 서론
침상삼킴평가(bedside swallowing evaluation)의 기본요소는 관찰, 구강 운동 기능 확인, 구역 반사, 구강 감각, 수의적인 삼킴, 음식물 삼킴 그리고 목소리 변화를 든다. 이중 가장 주요한 특징으로는 ‘젖은 목소리’(wet voice quality, 이하 WVQ)로써, 목소리 변화를 보일 경우 도구적 평가가 요구된다(Groves Wright, 2007).
WVQ 특징은 흡인환자의 90% 이상에서 관찰될 정도로 그 빈도는 매우 높고(Linden & Siebens, 1983) 대다수 임상가들에게 인정받는 증상이지만(Daniel et al., 1998; Groves-Wright et al., 2010; Santos et al., 2015) 객관적으로 그 정의에 대해서는 합의되지는 않아(Wright, 2007), wet-dysphonic(Murray et al., 1996), wet-hoarse (Linden & Siehens, 1983), wet phonation(Linden et al., 1993), impaired vocal quality(Mann & Hankey, 2001), voice change with swallow(Daniels et al., 1998) 등으로 다양하게 기술되어져왔다. 임상에서 삼킴장애 환자들의 WVQ 특징은 여러 시점에서 나타난다. 이는 환자들의 구강 내 환경이 다르기 때문이다. 삼킴장애로 음식을 먹지 않아 매우 건조한 경우도 있고, 반대로 사레 증상으로 침을 삼키지 않아 항상 구강에 침이 고이게 되어 오히려 높은 가수상태가 되는 경우도 있다. 이런 다양한 구강 상태에서 유발되는 WVQ 특징은 삼킴 후 획일적으로 동일하게 나타나지 않는다.
삼킴장애는 협착성, 기형성, 구인두성, 마비성, 경련성 삼킴장애로 분류되고, 이중 구인두성 삼킴장애가 가장 높은 빈도를 차지한다. 이것을 유발하는 질환에는 뇌졸중, 치매, 퇴행성 질환(파킨슨병, 헌팅턴병 등), 방사선 치료 및 화학요법의 중재과정, 다발성피부근염 같은 결합조직 장애 등이 있다(Groher & Crary, 2011). 이런 질환은 노년층에서 빈번하게 발생하며 지역사회 노인들을 추적 조사한 보고에 의하면 70% 이상에서 삼킴장애와 동반된 병적 상태를 보였다(Groher & Crary, 2011).
노년의 성대는 생리학적으로 위축(muscular atrophy)이 발생하는데 이는 세포외기질(extracelluar matrixes)이 조밀해져 유연성이 감소하고 점막고유층(lamina propria)은 콜라겐 증가와 엘라스틴 감소로 성대가 딱딱해짐(stiffness)을 의미한다(Rapoport et al., 2018). 딱딱해진 성대는 노인성 목소리(presbyphonia)를 만들며 기식이 동반 된 거친 소리, 약한 음성강도, 최대연장발성시간(maximum phonation time, 이하 MPT) 감소, 낮은 음도, 음성 떨림 등이 그 특징이다. 일반적으로 음질(voice quality)은 탈수(dehydration) 영향을 받아 음향 변수(NHR, Shimmer, Jitter, F0, S/Z ratio)에 부정적 영향을 주는 반면, 수분 섭취는 음향변수(Shimmer, Jitter, F0, MPT)에 긍정적 영향을 준다(Alves et al., in press). 하지만 이런 일반적인 현상이 노년층에서는 다르게 나타난다. 정상 한국인 대상 연구(이효진 & 김수진, 2006)에서 연령 증가에 따라 음성에 소음(noise) 비율이 커졌고, 수분 섭취 후 오히려 정상 노년층에서 주파수 기반 음향 변수들의 수치가 상승하여 음질저하를 보였다(이솔희 외, 2018). 노년에서 나타나는 이런 변화는 연령에 따른 인-후두 감각, 설골 상승, 성대의 유연성 및 후두벽의 탄력성 저하 때문으로 추론했다.
삼킴장애가 대부분 노년층에서 발생하고, 노년층에서 후두의 생리적 큰 변화가 나타나므로 이 모든 것을 고려하여 WVQ 특징을 살펴봐야 한다. 그래서 삼킴장애 관련하여 WVQ 평가를 할 경우는 반드시 음식섭취 전후로 관찰되어져야 하고 음향분석 또한 음식섭취 전후로 바로 이루어져야 한다. 강영애 외(2017a)는 흡인 유무에 따른 집단 간 음향변수 비교에서 흡인으로 인해 음질 저하가 되어 분석 구간과 전반적인 분석 길이 변수에 영향이 있음을 밝혔다. 하지만 전체 대상자가 27명으로 적은 수로 삼킴장애 환자의 일반적인 특징으로 해석하기에는 추후연구가 필요했다. 다른 선행연구(Kang et al., 2018)에서는 Videofluoroscopic swallowing study(VFSS) 검사를 받은 165명 환자를 대상으로 흡인 유무에 따른 음향분석 결과, RAP 변수가 통계적으로 차이를 보였는데 흡인군에서 감소하고 비흡인군에서 증가를 보였다. 통계적으로는 유의성은 없었지만 Jitter와 NHR 변수도 같은 양상을 보였다. 강영애 외(2017b)는 뇌졸중 환자 대상 흡인군, 비흡인군 그리고 정상군을 대상으로 발성구간 내 음향변수의 변화를 고려한 역동적인 변수인 변동률(delta) 수식을 적용한 결과, Shimmer와 APQ 변수에서 집단 간 차이를 확인했다. 삼킴이라는 역동적인 활동을 표현해줄 변동률 변수를 제안한 점과 정상군과 환자군을 동시에 비교한 점은 획기적이고 진보적인 연구세팅이지만, 제안된 변수의 결과가 청지각적으로 어떠한 상관이 있는지를 궁금증을 남겼다.
이에 본 연구는 삼킴장애 환자를 대상으로 청지각 판단의 WVQ 유무에 따른 음향적 변화를 살펴보고자 하며 연구 문제는 다음과 같다.
첫째, VFSS 후 WVQ 유무 집단 간 음향 및 시각적 분석변수에 차이가 있는가?
둘째, VFSS 전 WVQ 유무 집단 간 음향분석 변수에 차이가 있는가?
셋째, VFSS 전후 WVQ 유무 집단 간 음향분석 변수에 차이가 있는가?
2. 연구 방법
본 연구는 임상연구심의위원회의 승인(2016-05-020-001) 하에 이루어졌다. 2015년 9월–2017년 5월까지 비디오투시조영삼킴검사(videofluoroscopic swallowing study, 이하 VFSS)에 의뢰된 427명 환자를 1차로 모집하였고 VFSS에서 MPAS 4–5점을 받아 삼킴장애로 확진된 환자 117명을 2차 선별하였다. MPAS (modified penetration and aspiration scale)는 PAS(penetration and aspiration scale)의 수정판으로 5점(1–5) 척도로 4점은 음식물이 기도로 흘러들어가고 성대 아래쪽까지 내려가며 빼내기 위한 기침 반사 등의 노력 반응을 보이는 경우이고, 5점은 음식물이 기도로 흘러들어가고 성대아래쪽까지 내려가지만 빼내려는 반응 없는 무증상 흡인상태를 의미한다. 2차 인원 중 음성분석 오류를 불러올 가능성이 있는 성대마비자 및 기관루 존재자 11명을 추가로 제외시켜 최종 106명을 선택하였다.
VFSS는 방사선 기기(Shimadzu Flexavision FD RF X-ray system, 2012년)를 사용하고 다양한 검사 식이(요거트, 죽, 물 5 mL, 물 10 mL, 밥)에 조영제(레딕스액, 황산바륨, 동인당제약주식회사, 40%w/v)를 일정비율(음식물:조영제, 3:7)로 섞어 환자에게 순차적으로 제공하면서 환자가 씹어 삼키는 동안 검사자는 실시간 촬영 모니터를 보면서 MPAS 등급을 매기는 검사이다(강영애 외, 2017b 재인용). 본 연구에서는 특정 식이 단계에서 흡인을 보일 경우 다음 식이 단계로 넘어가지 않고 환자의 안전을 위해 환자에게 기침을 하도록 권고하고 검사를 중단했다.
환자 진단명은 크게 네 범주로 나누었으며 복합 질환의 경우는 주원인이 되는 병명으로 분류하였다. 다빈도의 뇌졸중(stroke) 범주, 인후두 상태 변형이 초래되는 두경부 암(head-neck cancer) 범주, 그리고 다른 의학적 질병이 없는 노화 범주, 그 외는 파킨슨병, 알츠하이머 치매 및 운동뉴런 이상 등은 퇴화(degeneration), 호흡기 질환, 당뇨, 골절, 척추이상 및 심인성 삼킴장애는 의학적 질병(medical disease) 범주로 묶었다.
총 106명의 음성파일로 WVQ 유무의 청지각 평가를 실시하여 Wet군은 48명(남:여, 41:7), 연령은 30세에서 87세까지 분포하고 평균연령은 69.02±13.84세이며, MPAS 4점은 13명, 5점은 35명이었다. 뇌졸중 21명으로 가장 많았고, 두경부암 3명, 노화 1명, 퇴행성 질환 11명, 의학적 질병 12명이었다. Non-wet군은 58명(남:여, 44:14), 연령은 38세에서 90세까지 분포하며 평균연령은 71.19±10.35세이었다. MPAS 4점은 10명, 5점은 48명이었고, 뇌졸중이 29명, 두경부암 6명, 노화 1명, 퇴행성 질환 8명, 의학적 질병 14명이었다(표 1 참조).
청지각 평가단으로 언어치료학 전공자(석사, 박사)로 삼킴장애 환자를 진단 및 치료해 본 경험이 있고 대학병원 근무 경력이 7년 이상인 언어치료사(1급) 두 명을 모집하였다. 평가자 한 명은 연구자(Kang, Y. A.) 임을 밝혀둔다.
청지각 평가용 파일은 VFSS 후 녹음된 모음/아/의 전체구간 3회를 환자별로 한 파일로 묶어 제공하였다. WVQ은 4점 척도로 WVQ가 없다는 0점, 있다는 1–3점(1점: 조금, 3점: 심각) 중 한 점수를 매기도록 했다. 환자 당 3회의 모음발성을 대상으로 평가하기에 각 발성마다 WVQ 특성이 다를 수 있다. 세 번의 발성 중 한 번의 발성에 WVQ 특성이 있다면 1점을 매기고 세 번의 발성 모두에서 WVQ 특성이 있다면 3점을 매기도록 하였다. 평가용 파일 재생은 PRAAT의 스크립트(랜덤 방식) 방식으로 하여 평가자가 사전에 파일에 대한 정보를 확인하지 못하도록 하였고 평가자가 원하는 만큼 음성을 재생할 수 있도록 하였다. 두 평가자는 일주일에 걸쳐 106개의 모든 파일을 2번씩 평가하였다. 평가자 1의 Kappa 합치도는 0.82(p<0.01)이고, 평가자 2는 0.91(p<0.01)이며, 두 평가자 간의 Kappa 합치도는 0.62(p<0.01)이었다. 두 평가자가 매긴 등급이 불일치할 경우 해당 파일을 대상으로 청지각 평가를 다시 실시하여 최종 등급을 결정하였다. 이렇게 평가된 결과로 WVQ 0점은 Non-wet군(58명), WVQ 1–3점까지 Wet군(48명)으로 나누었다.
음성녹음은 VFSS 직전과 직후 동일 조건/장소에서 실시하였다. 편안한 발성으로 모음/아/를 3회 녹음하였고 모두 분석하여 평균값을 통계에 적용하였다. 음성녹음은 VFSS용 방사선기기의 소음이 통제되도록 방음문을 닫은 상태에서 진행하였고 삼킴 후 녹음은 VFSS 직후 바로 실시하여 성대에 황산바륨이 묻은 식이가 제거되지 않은 상태를 최대한 유지시켰다. 음성녹음은 보이스 레코더(PCM-50, Sony Corp., Tokyo, Japan)에 헤드셋 마이크(Sennheiser pc151, Sennheiser electronic GmbH & Co, KG, Germany)를 꽂아 입술에서 10 cm 내외 위치시킨 상태에서 실시하였다(input 4 level, 48 kHz Sampling rate, 24 bit Quantization).
음성분석은 PRAAT(ver. 6021)을 사용하여 모음 전체 구간을 선택하여 12개 음향변수 [fundamental frequency(F0), standard deviation of F0(F0_SD), Intensity, Jitter, relative average perturbation (RAP), Shimmer, amplitude perturbation quotient(APQ), Harmonics- to-noise ratio(HNR), Noise-to-harmonics ratio(NHR), fraction of locally unvoiced frames(FUF), degree of voiced breaks(DVB), cepstral prominence peak(CPP)]를 측정하였다(Hamming window, cross- correlation).
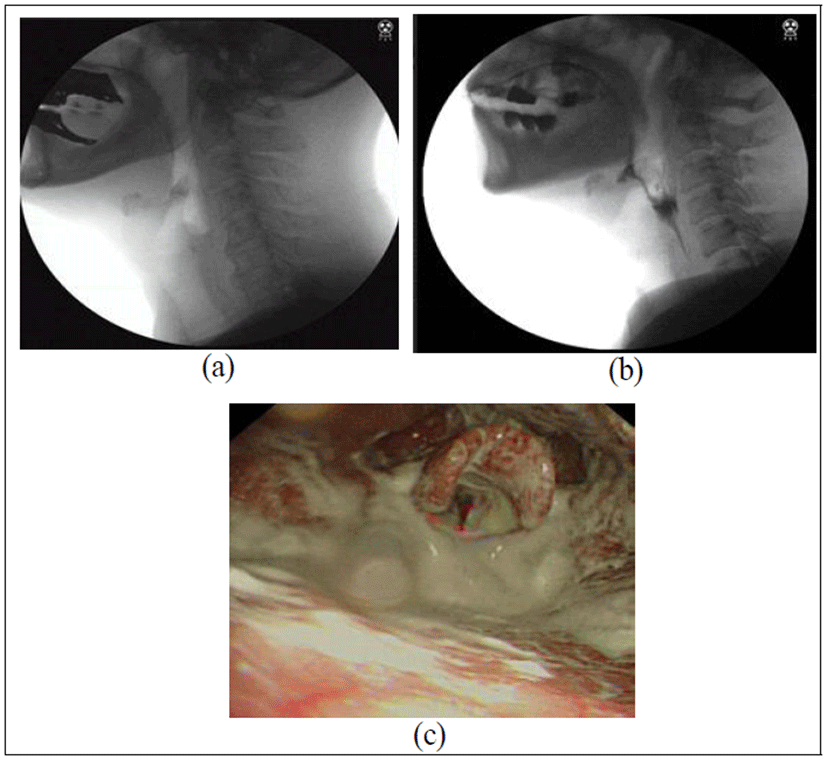
VFSS 중 실시간 촬영 모니터 화면을 통해 후두덮개 계곡에 고이는 음식량(amount of food in vallecula porch, 이하 Amount)과 황산바륨이 인-후두벽에 묻는 코팅정도(coating of pharyngeal wall, 이하 Coating)를 각 4점 척도(none, a few, moderate, profuse)로 측정하였다. 본 연구에서는 두 변수를 시각적 분석변수라고 명명하고 이해를 돕기 위해 VFSS와 내시경 사진을 그림 1에 제시하였다.
본 연구에 사용한 분석변수는 VFSS의 2개와 PRAAT의 12개로 전체 14개 변수이다. 가능한 분석변수를 짝을 이루도록 선택한 이유는 분석의 일관성을 확인하기 위해서였다(표 2 참조).
| Category | Parameter (units) |
|---|---|
| VFSS | Amount, Coating |
| PRAAT | Intensity (dB), F0 (Hz), F0_SD (Hz), Jitter (%), RAP (%), Shimmer (%), APQ (%)HNR (dB), NHR, FUF, DVB, CPP (dB) |
VFSS, videofluoroscopic swallowing study; F0, fundamental frequency; SD, standard deviation; RAP, relative average perturbation; APQ, amplitude perturbation quotient; HNR, Harmonics-to-noise ratio; NHR, Noise-to-harmonics ratio; FUF, fraction of locally unvoiced frames; DVB, degree of voiced breaks; CPP, cepstral prominence peak
본 연구는 연구 문제와 관련하여 세 가지 실험으로 구성하였다. 첫째, VFSS 후 청지각 평가로 WVQ 유무에 따라 두 집단을 나누고, 14개 변수 중 WVQ 있음에 영향을 주는 변수를 찾기 위해서 독립 표본 t-검정으로 유의미한 변수를 선별하고 이를 로지스틱 회귀분석에 적용 후 수신자 조작 특성(receiver operating characteristics, 이하 ROC)으로 분류정확도를 구했다.
둘째, VFSS 후 WVQ 유무로 나눈 두 집단분류를 VFSS 전 상태에 적용하여 독립 표본 t-검정으로 VFSS 전 두 집단 간 음성 정보를 비교했다.
셋째, WVQ 유무 집단의 VFSS 전후 음향분석 정보변화를 알아보기 위해, 반복측정 분산분석(repeated measures analysis of variance, 이하 RM-ANOVA) (mixed model) 을 적용하였다. 참고로, 성별 인자에 민감한 F0 변수는 성별을 나누어 통계검정을 하였다.
3. 연구결과
VFSS 후 WVQ 유무 집단 간 14개 변수에 대해서 독립 표본 t-검정을 실시한 결과, F0_SD(p<0.05), Jitter(p<0.01), RAP(p<0.01), Shimmer(p<0.01), APQ(p<0.01), HNR(p<0.01), NHR(p<0.01), FUF (p<0.01), DVB(p<0.01), CPP(p<0.01) 변수는 통계적으로 유의미한 차이를 보였다. HNR와 CPP 변수의 평균은 Wet군보다 Non-wet군이 더 높았고, 그 외 변수들은 Wet군이 더 높았다(표 3 참조). 참고로 Amount와 Coating 변수를 명명척도로 처리하고 카이검증을 실시하여도 유의미하지 않았다.
VFSS, videofluoroscopic swallowing study; F0, fundamental frequency; SD, standard deviation; RAP, relative average perturbation; APQ, amplitude perturbation quotient; HNR, Harmonics-to-noise ratio; NHR, Noise-to-harmonics ratio; FUF, fraction of locally unvoiced frames; DVB, degree of voiced breaks; CPP, cepstral prominence peak
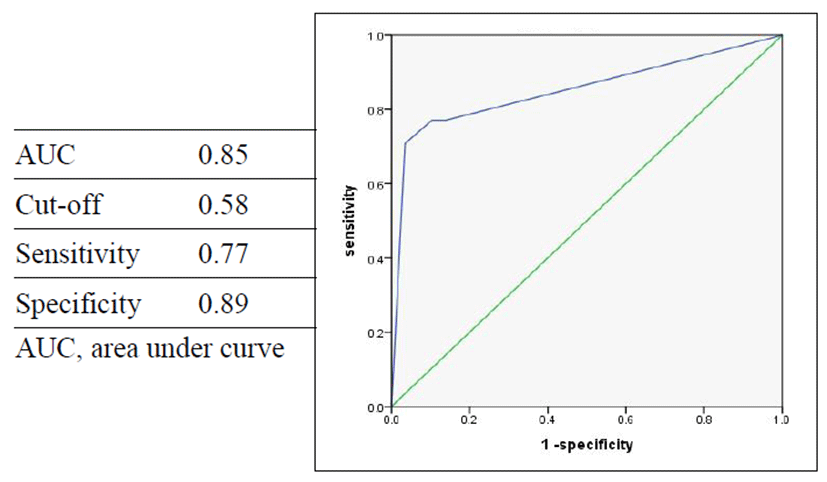
독립 표본 t-검정에서 유의미하게 나온 변수를 대상으로 다중공선성 문제를 피하기 위해 개념적으로 유사한 변수들을 대표변수 한 개로 선정하여 로지스틱 회귀분석(전진 wald 방식)에 적용하였다. NHR, Jitter, Shimmer 같이 변수 수치가 작은 것은 분석시 오즈비(odds ratio)가 기형적으로 커지므로 이를 보완하기 위해 변수의 역치 값(각각 0.190, 1.040, 3.810)을 기준으로 역치 이하는 0, 역치 이상은 1로 범주화 시켰다. 로지스틱 회귀분석결과, Jitter와 NHR 변수가 선택되었다. Jitter가 1 증가할 때(역치 이상일 때) Wet군이 될 확률은 7.59 증가하고, NHR이 1 증가할 때(역치 이상일 때) Wet군이 될 확률은 7.120 증가한다(표 4 참조). 두 변수 조합의 예측확률에 대한 곡선하영역(area under curve, 이하 AUC)은 0.853 이고 민감도는 0.77, 특이도는 0.89 이다(그림 2 참조).
| S.E | df | p $ | Exp (B) | |
|---|---|---|---|---|
| Jitter | 0.74 | 1 | 0.006** | 7.59 |
| NHR | 0.81 | 1 | 0.015* | 7.12 |
VFSS 전 분석 변수는 Amount와 Coating을 제외한 12개 변수 만 비교하였다. 독립 표본 t-검정 결과, Intensity(p<0.05), Jitter(p<0.01), RAP(p<0.01), Shimmer(p<0.05), NHR(p<0.01), FUF(p<0.05), DVB (p<0.05), CPP(p<0.05) 변수가 통계적으로 유의미하였고, 이중 CPP 변수의 평균만이 Non-wet군에서 더 높았으며, 나머지 변수들은 Wet군이 더 높았다(표 5 참조).
VFSS, videofluoroscopic swallowing study; F0, fundamental frequency; SD, standard deviation; RAP, relative average perturbation; APQ, amplitude perturbation quotient; HNR, Harmonics-to-noise ratio; NHR, Noise-to-harmonics ratio; FUF, fraction of locally unvoiced frames; DVB, degree of voiced breaks; CPP, cepstral prominence peak
RM-ANOVA 분석 결과, 시간에 따른 요인(Time) 즉, VFSS 전후로는 Intensity(p<0.01), F0_SD(p<0.05), FUF(p<0.05), DVB (p<0.05) 변수가 통계적으로 차이를 보였고, 집단에 따른 요인(Group)으로는 F0_SD(p<0.05), Jitter(p<0.01), RAP(p<0.01), Shimmer(p<0.01), APQ(p<0.05), HNR(p<0.01), NHR(p<0.01), FUF (p<0.01), DVB(p<0.01), CPP(p<0.01) 변수가 차이를 보였다. 마지막으로 VFSS 전후 집단 간 상호작용(Time×Group)은 Intensity (p<0.05), F0_SD(p<0.05), Jitter(p<0.01), RAP(p<0.01), Shimmer (p<0.01), APQ(p<0.01), HNR(p<0.01), NHR(p<0.01), FUF(p<0.01), DVB(p<0.05), CPP(p<0.01) 변수에서 차이를 보였다(표 6 참조).
VFSS, videofluoroscopic swallowing study; F0, fundamental frequency; SD, standard deviation; RAP, relative average perturbation; APQ, amplitude perturbation quotient; HNR, Harmonics-to-noise ratio; NHR, Noise-to-harmonics ratio; FUF, fraction of locally unvoiced frames; DVB, degree of voiced breaks; CPP, cepstral prominence peak
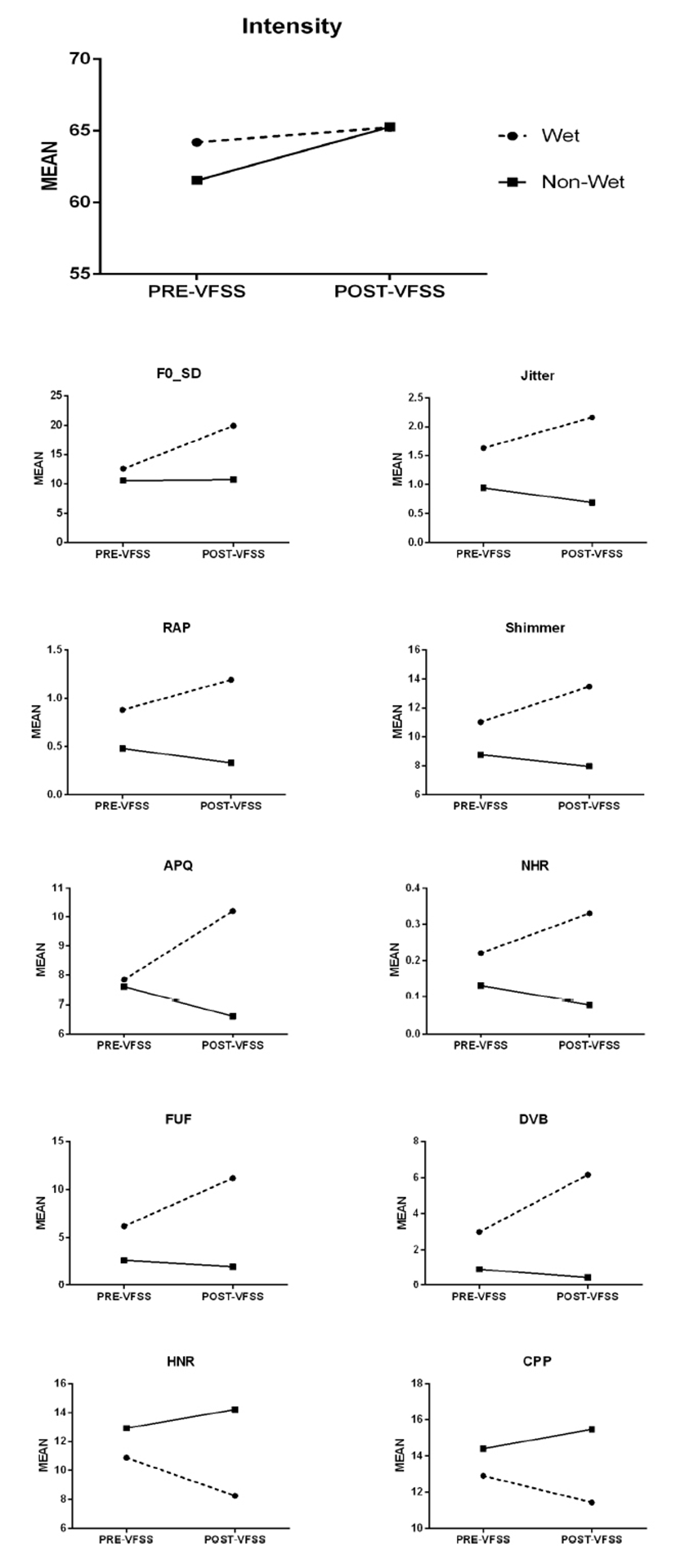
VFSS 후 Wet군의 F0_SD, Jitter, RAP, Shimmer, APQ, NHR, FUF, DVB 변수 수치가 상승하였고, HNR, CPP 변수는 감소하였다. 반면, Non-wet군은 Jitter, RAP, Shimmer, APQ, NHR, FUF, DVB 변수 수치가 감소하였고 HNR, CPP는 증가하였다. 특히, Intensity 변수는 두 군에서 VFSS 후 모두 상승하였으나 Non-wet군의 상승폭이 Wet군보다 더 컸다(그림 3 참조).
4. 논의 및 결론
본 연구는 VFSS후 삼킴장애로 확진된 환자를 대상으로 청지각 평가에 따른 WVQ 유무군에 대한 음향 분석 및 시각적 변수를 조사한 것으로 연구결과를 정리하면 다음과 같다.
첫째, VFSS 후 Wet군과 Non-wet군 간 여러 음향변수(F0_SD, Jitter, RAP, Shimmer, APQ, HNR, NHR, FUF, DVB, CPP)가 통계적으로 차이를 보였고, 변수 수치를 바탕으로 Wet군의 음질이 Non-wet군보다 더 저조함을 알 수 있었다. VFSS 후 청지각적으로 WVQ를 예측하는데 기여하는 변수는 Jitter와 NHR이며 예측 확률은 85%로 높았다.
이는 흡인 환자 음성에서 RAP, Jitter, Shimmer, SHDB, NHR 변수 상승을 보고한 연구결과(Wright, 2007)와도 일치한다. 선행연구에서는 흡인이 있지만 성대에 이물질이 없는 경우는 본 음향변수의 상승이 없었다고 보고하였다. 이런 음향변수의 변화를 포착하기 위해서는 VFSS 직후 바로 음성녹음을 해야 한다고 강조했다. 본 연구는 VFSS 직후 음성녹음을 실시하였기에 흡인 후 인-후두에 남는 음식잔여물을 최대한 확보하였고 본 결과도 이런 세팅을 간접적으로 보여준 셈이다.
다른 선행연구(강영애 외, 2017a)에서 흡인 유무 군의 모음/아/의 전체발성구간을 분석한 결과, VFSS 후 두 집단 모두에서 Jitter와 NHR 수치가 상승하였고 비흡인 환자군이 더 높은 상승폭을 보였다. 동일 연구팀의 다른 연구(강영애 외, 2018)에서는 VFSS 후 모음/아/의 안정구간을 선택하여 분석한 결과, 흡인군의 Jitter 수치가 하강하였고 비흡인군은 상승하였다. 두 선행연구에서 이런 차이점은 음성 분석 구간의 차이 때문이라고 생각한다. 전자는 분석구간을 전체구간으로 선택한 것이고, 후자는 안정구간만을 선택한 것이다. 비록 두 선행연구에서는 분석 구간의 차이로 다른 결과를 보였지만 변화를 보인 변수가 Jitter와 NHR 라는 점에서는 같다. 물 마신 후 정상 노년층에서도 Jitter 와 NHR 수치가 상승하는데(이솔희 외, 2018) 이런 변화는 청년층에서는 보이지 않았다. 이는 노년의 경우 후두 움직임이 느려 마신 물이 건조해진 점막에 분비액처럼 묻게 되므로 본 변수들의 수치가 상승되었다고 보고했다. 선행연구에서도 지적했듯이 노년의 점막 건조함 및 느린 후두 움직임이 삼킴 후 음향 변수에 영향을 준다.
둘째, VFSS 후 인후두에 남는 음식잔여물 양 및 코팅 정도는 WVQ 유무 집단 간 차이가 없었다. 이는 삼킴 후 음식물이 구강과 인-후두에 남는 것과 WVQ와 관련 없음을 보고한 선행연구(Warms & Richards, 2000)와도 일치한다. 뇌졸중 환자 23명의 모음/아/ 대상으로 WVQ 유무를 판단하고 비디오내시경(videofluoroscopy) 검사로 잔류 음식물 위치를 구강, 후두, 그리고 기관지 구간으로 살펴보았으나 WVQ와 잔류음식물의 위치 간 차이가 없었다. 또 다른 연구(Santos et al., 2017)에서도 삼킴 후 음식물(pasty consistency)이 공기 흐름을 방해하여 GRABS 척도 중 Grade와 Asthenia(정적상관), 그리고 Strain(부적상관)에 영향을 주지만 WVQ에는 상관이 없다고 보고된바 있다. 삼킴 후 잔류 음식과 WVQ 특성 간 상관이 없다면 삼킴장애의 WVQ 특성을 어떻게 설명해야할지 여전히 의문이다. 이 질문에 선행연구에서는 후두전정기관(laryngeal vestibule)에 누적되는 분비물이 WVQ를 생성한다고 주장했다(Murray et al., 1996). 즉, 흡인으로 성대에 묻는 음식물로 WVQ가 유발되는 것이 아니라 인-후두에 고이는 음식물로 유발된다고 보았다. 이런 주장은 VFSS 전 상황에서 침 고임을 보이는 환자들에게서 WVQ 특성이 보이는 임상 관찰소견과 비교해 볼 때 설득력이 있다. 하지만 본 연구결과에서는 Amount와 Coating 변수에서 통계적으로 유의미한 차이를 보이지 않았다. 이는 본 변수의 등급측정을 하는 순간은 VFSS 중 화면을 보면서 등급을 매기는 반면, 음성녹음은 VFSS 후 진행되므로 이런 시간적 차이로 인해 음식물 고임정도를 정확히 평가하기에는 현재의 연구 세팅에서는 어렵다. 고로 WVQ와 인-후두의 정밀한 음식물 고임량 상관조사는 추후 연구과제로 남긴다.
셋째, VFSS 전 Wet군과 Non-wet군 간 여러 음향변수(Intensity, Jitter, RAP, Shimmer, NHR, FUF, DVB, CPP)에서 차이를 보였다. 이는 VFSS 후와 같이, Wet군의 음질저하를 의미한다. 또한, VFSS 전후 WVQ 유무 두 군 간에도 여러 변수(Intensity, F0_SD, Jitter, RAP, Shimmer, APQ, HNR, NHR, FUF, DVB, CPP)에서 상호작용을 보였다. 변수들의 패턴은 VFSS 후 Non-wet군에서는 음질 향상을 의미하고, Wet군에서는 음질저하를 의미했다. 이 중 음성강도는 VFSS 후 두 군 모두에서 수치가 높아지는 동일 패턴을 보였으나 Non-wet군의 상승폭이 Wet군보다 더 컸다. 음성강도가 높으면 음질이 호전되는 양상을 보이므로 음성강도가 낮은 Wet군의 음질저하를 보인 것은 임상적으로 설득력이 있다. 높은 음성강도를 보이는 환자가 삼킴효율이 적어 흡인과 관련이 있다고 보고한 연구(de Bruijinijin et al., 2013)와 비교해 볼 때, 본 연구의 VFSS 전 보다 VFSS 후 음성강도가 상승한 점은 선행연구와 같은 맥락으로 해석할 수 있다. 하지만 본 연구의 모든 대상자들은 삼킴장애(흡인) 진단군으로 Non-Wet군이 Wet군보다 더 큰 상승폭을 보인 점은 주목할 부분이다. 본 연구팀은 Non-Wet군이 삼킴 후 인-후두에 이물감을 더 민감하게 느꼈기 때문에 Wet군보다 더 큰 음성강도를 표출했다고 생각한다. 뇌졸중 환자 대상으로 내시경 촉으로 성대를 건드려 촉각반응 민감도를 확인한 선행연구(Onofri et al., 2014)에서 후두의 감각저하가 흡인 가능성을 높인다고 보고하였다. 이는 흡인 환자들은 후두/성대의 민감도가 낮다는 의미로 앞서 서술된 논의에서 계속 언급된 노년층의 건조한 후두상태와 민감도와 연관되는데, Non-wet군이 인-후두에 코팅되는 황산바륨에 대한 민감도가 Wet군보다 높았기에 더 큰 음성강도를 보였다고 추론 가능하다. 다시 말해 Wet군의 후두의 민감도 및 반응도가 더 낮았기에 음성강도가 낮아졌을 것이다. 이런 낮은 음성감도는 Jitter 및 NHR 변수들의 수치를 상승시킬 것이고 청지각적으로 WVQ 판단에 영향을 주었다고 본다.
본 연구는 삼킴장애 진단을 받은 환자를 대상으로 청지각 평가로 WVQ 유무로 나누어 분석한 것이다. 주관적 평가인 청지각 평가가 갖는 신뢰성의 문제는 항상 내포되어 있다. 본 연구에서도 두 평가자의 Kappa 합치도가 낮아 재평가를 실한 결과로 최종적으로 집단을 조율했다. 추후 WVQ 평가에 대한 주관적 평가 훈련 및 논의가 이루어지길 바란다.
결국, WVQ 특성은 흡인된 음식물이 성대진동에 영향을 준 결과라고 보기 보다는 노년층의 건조한 후두 특성으로 인해 점막의 분비물 존재 효과를 주기 때문에 생성된다고 생각한다.