





1. Introduction
Korean exhibits a single liquid phoneme /l/ that has two distinct allophones, the flap [ɾ] and lateral [l]. Previous studies have suggested that the liquid phoneme has an underspecified feature at a phonological level (Iverson & Lee, 2006; Iverson & Sohn, 1994; Kang, 2003, 2011); it becomes a flap [ɾ] in syllable onset position and a lateral [l] in syllable coda position (Ahn, 2017; Gick et al., 2006; Iverson & Sohn, 1994; Ladefoged & Maddieson, 1996; Lee, 1996; Oh & Gick, 2002).
Although the phonological representation of the Korean liquid has been broadly discussed, relatively little attention has been given to the phonetic realizations. In particular, few articulatory studies have been conducted, and thus the articulatory characteristics of the Korean liquid still remain unclear.
The Korean lateral allophone has been described as a typical lateral sound (Kim & Lotto, 2004; Park & Jang, 2016; Shin, 2004), which involves airflow around the sides of the tongue having an anterior occlusion (Ladefoged & Maddieson, 1996:182; Maddieson, 2013; Narayanan et al., 1997; Stevens, 1998:532). However, the articulatory characteristics have been mostly inferred by authors’ native intuitions or the formant values.
There have been a series of 2D ultrasound publications (Gick et al., 2001; Gick et al., 2006; Oh, 2002; Oh & Gick, 2002) and one real-time MRI study (Lee et al., 2015) to investigate articulatory characteristics of Korean liquids. They reveal similar results: For the lateral [l], it was reported that the two main gestures are 1) tongue tip closure and 2) tongue body raising (palatalization), though a tongue root fronting gesture is also observed along with the raised tongue body. They also assert that there is no significant tongue body/root movement in the flap context. Tongue tip raising is greater for the lateral than the flap as well. In addition, Gick et al. (2001) and Oh (2002) reveal that the tongue tip and the tongue body gestures for the Korean lateral [l] occur almost simultaneously, having no timing lag between them.
Although these studies have greatly contributed to the understanding of the articulatory characteristics of Korean liquids, each study had methodological limitations that could have affected the results. These MRI and 2D ultrasound studies are only able to observe a single plane that approximately represents the midsagittal plane. Lateral sounds are often reported to be articulated with asymmetrical tongue movement, but the midsagittal view alone is not able to provide information about the asymmetry of the tongue gesture. For example, a 2D midsagittal image of an asymmetrically articulated /l/ might appear as though there is no constriction articulated at all because it occurs off the midline. Also, without imaging the surrounding parts of the vocal tract away from the midline, there is no guarantee that the visible data represent the midsagittal plane of the vocal tract. The tongue side gesture plays an important role in the production of lateral sounds, but both the MRI and 2D ultrasound studies do not provide this information. Moreover, the ultrasound methodology does not show the location of the palate (Stone, 2005), and this results in difficulties achieving detailed and accurate representations of the tongue movement. For instance, the midsagittal view of the tongue without the palate information does not show exactly which part of the palate is in contact with the tongue tip/blade or how closely the tongue body is raised toward the palate.
With new 3D ultrasound methods, many of the ambiguities in the previous MRI and 2D ultrasound images can be resolved because sagittal, coronal, and transverse planes can be examined. In addition, it is possible to combine a 3D scanned palate impression with 3D ultrasound, providing complementary information about the location of the tongue relative to the palate and teeth. This method can be used to construct a more accurate representation of the tongue shape, and this is especially helpful for articulatory research on lateral sounds since a tongue side gesture and asymmetries in tongue surface that are commonly found can be identified and visualized (Charles & Lulich, 2018).
The previous 2D ultrasound and real-time MRI studies (cited above) included only two participants, and they mostly focused on investigating distinctions between the flap [ɾ] and the lateral [l]. That is, little attention was given to the articulatory variation of Korean laterals. Lateral approximants have been reported to have substantial cross-linguistic, dialectal, context dependent, and idiosyncratic variation in their articulation (Ladefoged & Maddieson, 1996:183-193; Proctor, 2011). Thus, it is important to investigate the articulatory variation to have a better understanding of Korean laterals. Since Korean does not have a phonemic distinction between /l/ and /r/, Dispersion Theory (Flemming, 1995, 2017; Liljencrants & Lindblom, 1972; Lindblom, 1990; etc.) would predict that the Korean lateral [l] might occupy a larger acoustic and articulatory space than laterals in other languages that have this contrast. In fact, Korean laterals have been acoustically described as somewhere between English light /l/ and word-final /r/. F2 values are reported to be higher than English /l/ and more like English word-final /r/ (Kim & Lotto, 2004), whereas F3 values are lower than English /l/ but higher than English /r/ (Park & Jang, 2016). Also, Korean lateral formant values have been reported to be greatly affected by neighboring vowels (Ahn, 2017; Lee & Kang, 2003). We therefore hypothesize that Korean laterals might display large between speaker and vowel-dependent articulatory variation.
The aim of this study is to improve our understanding of the articulatory characteristics of Korean lateral [l] using novel 3D ultrasound methods. This study will focus on investigating general articulatory characteristics of the articulation of the Korean lateral [l] and examining individual speaker and vowel-dependent variation.
2. Method
Data were collected from five native speakers of Standard (Seoul) Korean, and the age of participants ranged from 22 to 25 (Mean age=23.6). All participants were female and born and raised in Seoul, the capital of South Korea. At the time of the data collection, they were studying at a major Midwest university in the U.S. (Indiana University) and the length of residence in the U.S. ranged from three months to four years (Mean length of residence=20.8 months). Participants reported themselves as intermediate or high proficiency English speakers, and everyone reported that they started studying English before the age of ten. The reported period of studying English was between 12 and 15 years (Mean years of experience=14).
The stimuli consisted of five mono-syllabic Korean words with a lateral [l] in word-final position. The words included five different vowels /i, a, Λ, o, u/, and they are shown in Table 1 below. In addition to these words, eight filler words with no word-final lateral were included to reduce a possible bias. The participants were seated in a double-walled sound-attenuating booth, and the stimuli were presented in random order, one at a time, on a computer monitor located in front of the participants. The complete list of stimuli was presented twice. The participants were instructed to pronounce each word naturally and out loud.
| [tal] | ‘moon’ |
| [pul] | ‘fire’ |
| [pol] | ‘cheek’ |
| [tΛl] | ‘less’ |
| [ɕil] | ‘thread’ |
Two different forms of articulatory data were collected. As the primary form of articulatory data, three-dimensional wedge-shaped volumetric images of the tongue were recorded using a Philips 3D/4D EPIQ 7G ultrasound machine with a Philips xMatrix x6-1 digital 3D/4D transducer (see Lulich et al., 2018 for technical details). The transducer was stabilized under the jaw with a customized Articulate Instruments Ltd headset, which restricts probe movement (Scobbie et al., 2008). As the secondary form of articulatory data, a palate impression was made using dental alginate (Ladefoged, 2003). The three-dimensional palate impression was scanned and digitized using a NextEngine Desktop 3D Scanner, and registered with the ultrasound data using the method described by Charles & Lulich (2018).
In addition to articulatory data, audio signals were recorded simultaneously with the ultrasound data, using a SHURE KSM32 microphone placed approximately 1.5 m in front of the participant. Recordings were made with a 48 kHz sampling rate and 16 bit quantization.
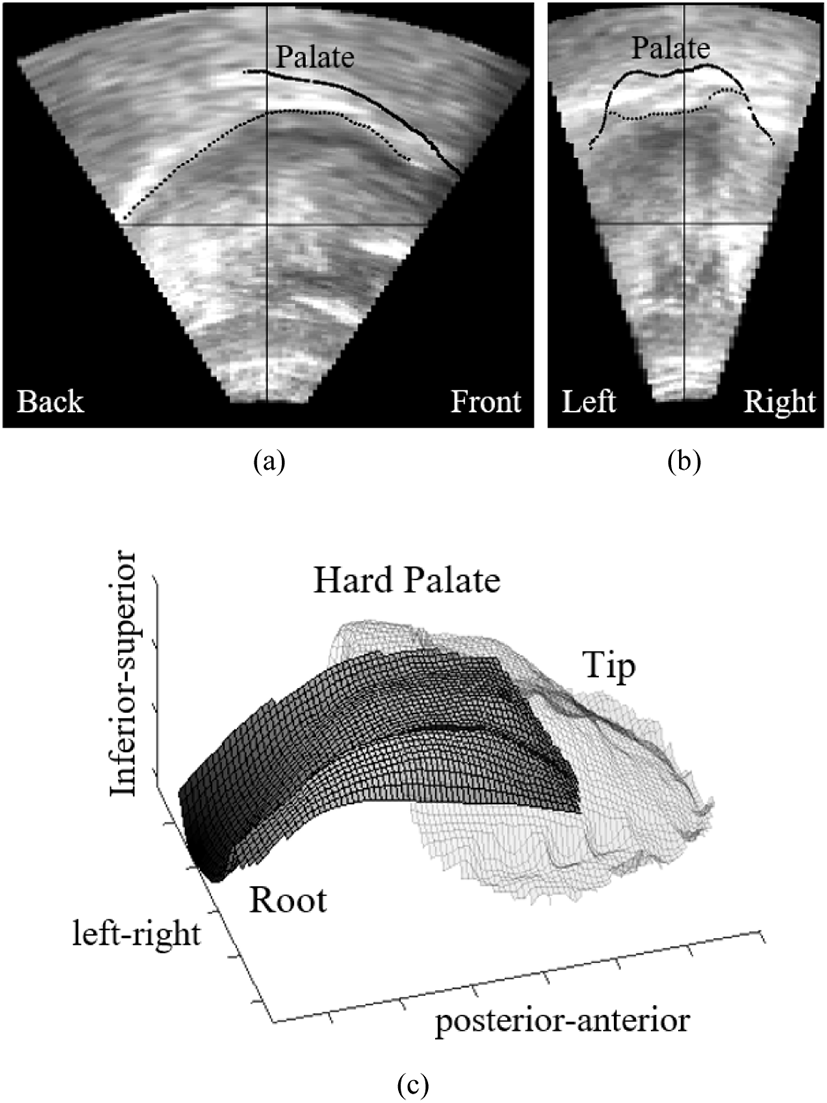
The articulatory data collected in this study were analyzed in two different ways. First, qualitative analyses were conducted with a custom-built toolbox for MATLAB (MathWorks, 2017), which combines the ultrasound data, palate impression data, and acoustic signal data. The tongue surface was visually identified and manually segmented in every fifth sagittal plane and every tenth coronal plane. This formed a regular grid of tongue surface contours, which were used to interpolate the full three-dimensional tongue surface (similar to the segmentation methods used in Charles & Lulich, 2018; Csapo & Lulich, 2015; Lulich et al., 2016). An example of these methods is shown in Figure 1. The manual segmentation was done for the frames that occurred during the target segments in addition to one frame before and one frame after. The peripheral frames were not analyzed in this study.
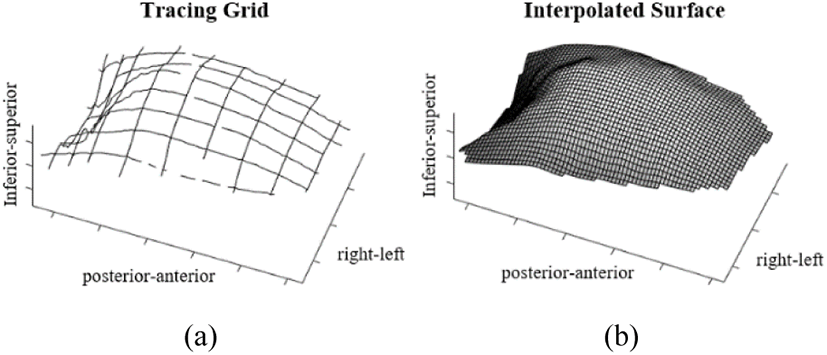
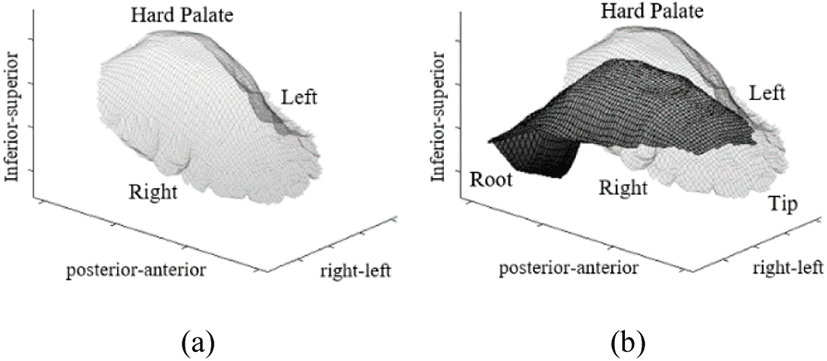
The 3D palate impression data were registered with the ultrasound data to visualize how the tongue and palate are aligned with each other. A sample image of a 3D palate impression (a) and an interpolated 3D tongue surface registered with the 3D palate impression data (b) is presented in Figure 2 below.
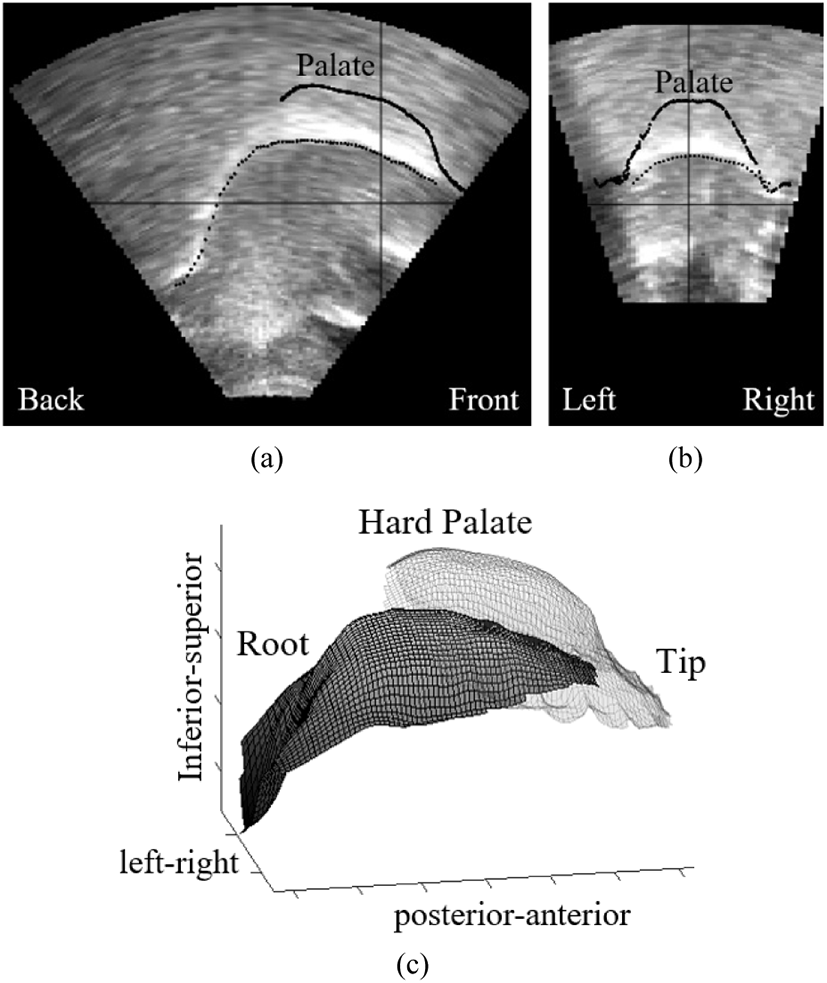
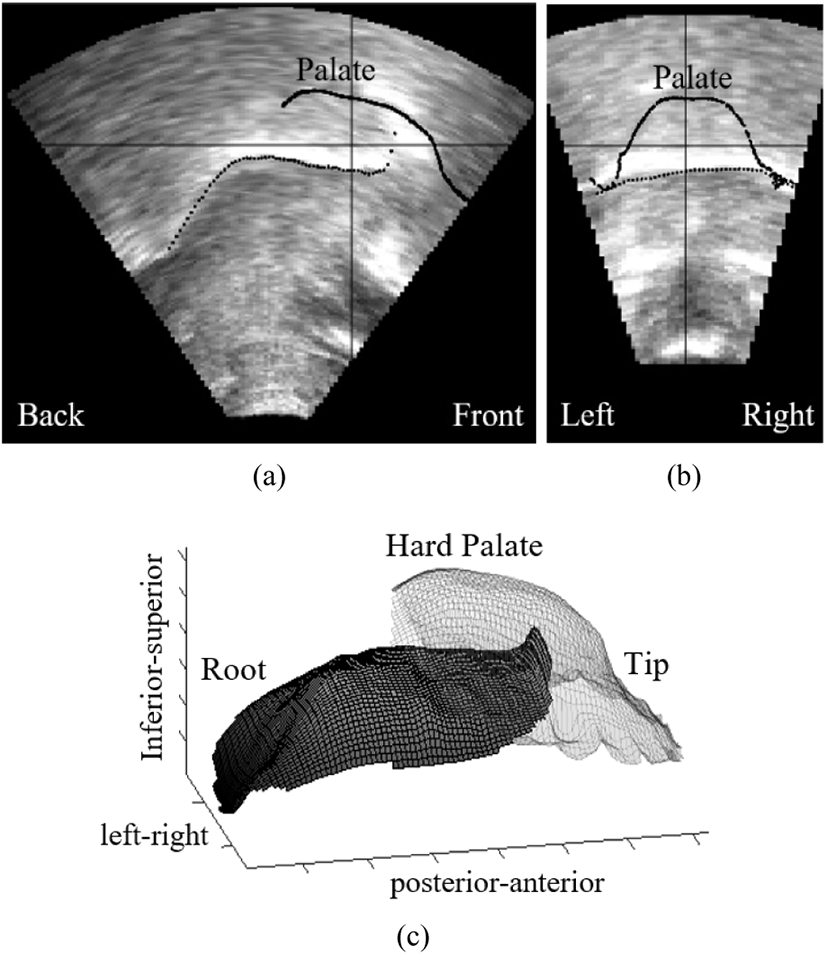
The qualitative analysis relies on the visualization of two intersecting two-dimensional planes and a composite three-dimensional image of the same token. Sample images are shown in Figure 3. For two-dimensional planes, the palate is represented as a solid line, the tongue surface is represented as a black dotted line, and the intersection of the planes is represented by the black crosshairs. For three-dimensional image, the palate is represented as a transparent grid and the tongue surface is represented as a gray grid under the palate.
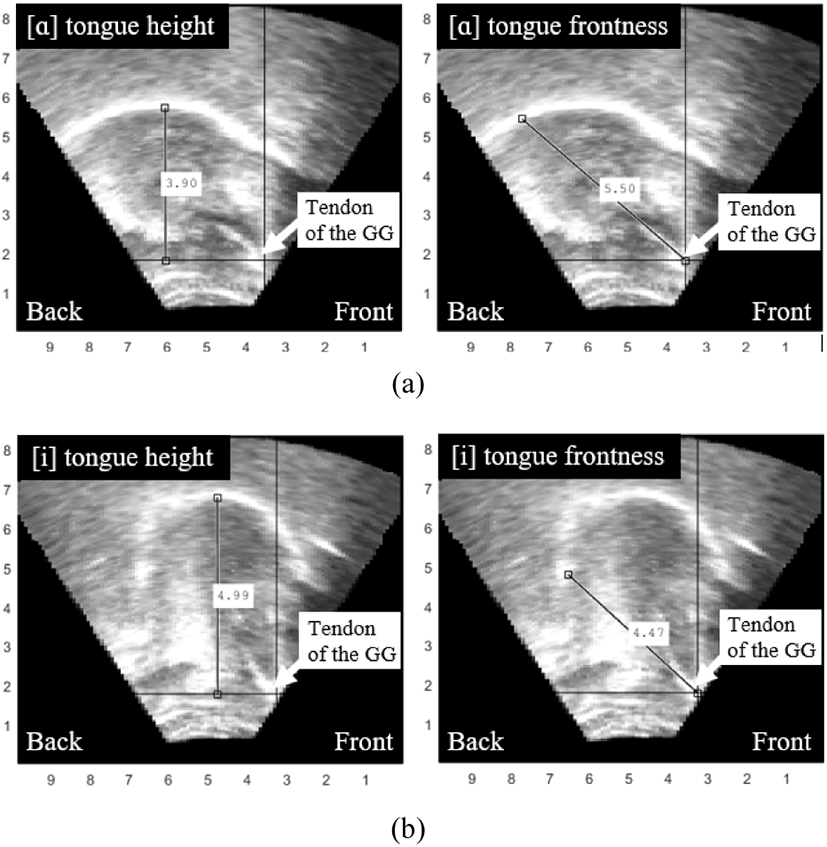
For the second, quantitative analysis of the articulatory data, anatomical distances for the height of the tongue body and the frontness of the tongue root were measured from a midsagittal ultrasound image of each token. For the measurement of tongue body height, the vertical distance from the tendon of the genioglossus (GG) to the highest point of the tongue was measured in centimeters. For the measurement of tongue root frontness, the distance from tendon of the GG to the tongue root was measured in centimeters at an angle of 45 degrees. These measurements reflect anatomical distances between landmarks, and should not be confused with indices of frontness or height.
These measurements were recorded at the midpoint of the /l/ tokens. Each stimulus was articulated two times, and all tokens were measured. In addition, distance measurements were recorded for the low back vowel [α] and the high front vowel [i] taken from recorded filler words. These values served as anchors at the extreme ends of the tongue body height and tongue root advancement scales, and thus enable within- and between-speaker comparisons. Example midsagittal ultrasound images illustrating these measurements of tongue body height and tongue root frontness in the articulation of the low back vowel [α] (a) and the high front vowel [i] (b) are presented in Figure 4. The left two images show the measurement of tongue body height (vertical distance), whereas the right two images exhibit the measurement of tongue root frontness (the distance at an angle of 45 degrees). From these images, it can be observed that the vowel [i] has a longer anatomical distance for tongue body height and a shorter anatomical distance for tongue root frontness than the vowel [α]. This shows that the vowel [i] has a more raised tongue body gesture and a more fronted tongue root gesture than the vowel [α], which is expected.
3. Results
The results from the articulatory analyses exhibit high between-speaker variation and some vowel-dependent variation. Each participant shows their own unique articulatory strategies to form the word-final Korean lateral [l], including lamino-postalveolar, apico-dental, retroflex, and lamino-alveolar strategies. Each of these strategies is described separately below. In each case, an example token will be displayed from each relevant speaker, together with the results of the tongue body height and tongue root frontness measurements. In the figures with tongue body height and tongue root frontness measures, each point represents the average of two tokens.
Among the five participants, two participants (P1 and P2) show a similar tongue gesture for the word-final laterals. They exhibit an occlusion between the tongue blade and the back of the alveolar ridge extending to the most posterior molar. They consistently produced these lateral sounds asymmetrically, occluding only one side of the oral cavity while maintaining a small opening on the other side from the most posterior molar to the incisors. One subject occludes the right side and the other occludes the left. For both participants, the tongue body is in a raised position, approximating the palate, similar to a high front vowel. As a consequence, the tongue root is advanced relative to other sounds in the data (such as an /α/ vowel), creating a clear midsagittal groove from the top of the tongue body to as far posterior as the ultrasound image shows. Figure 5 and Figure 6 display an example token from each of these two participants in two intersecting two-dimensional planes (a, b) and a composite three-dimensional image (c).
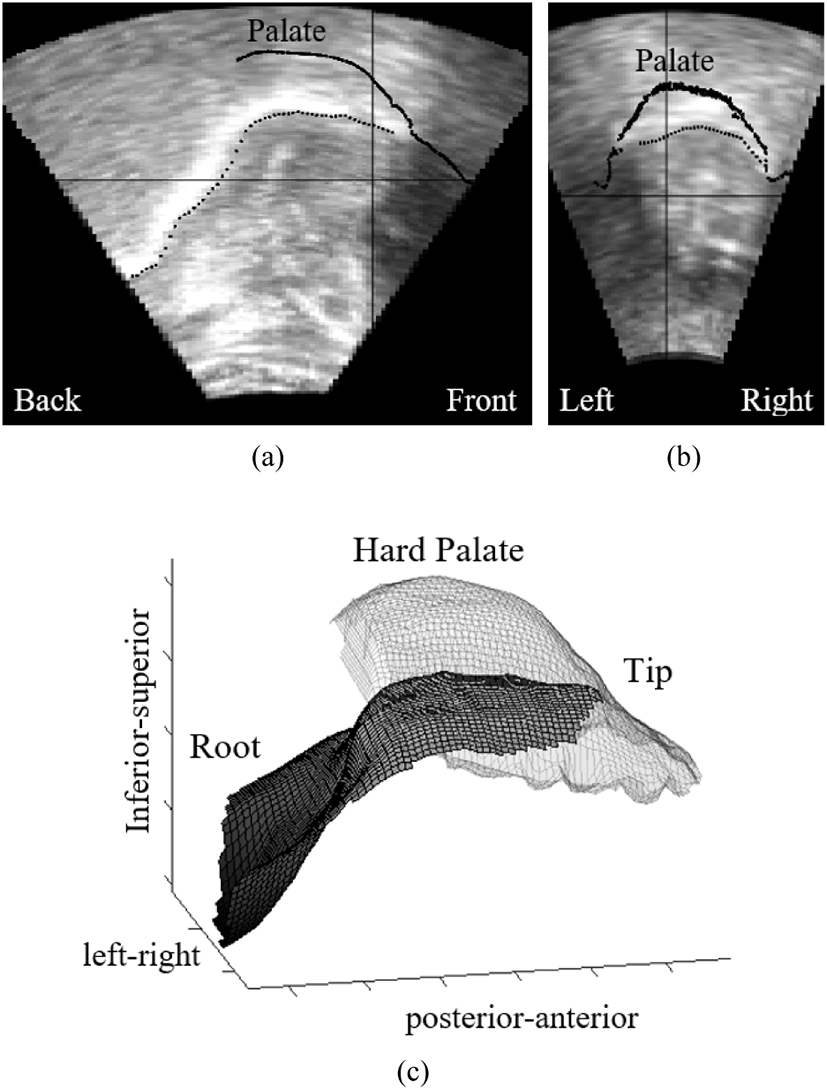
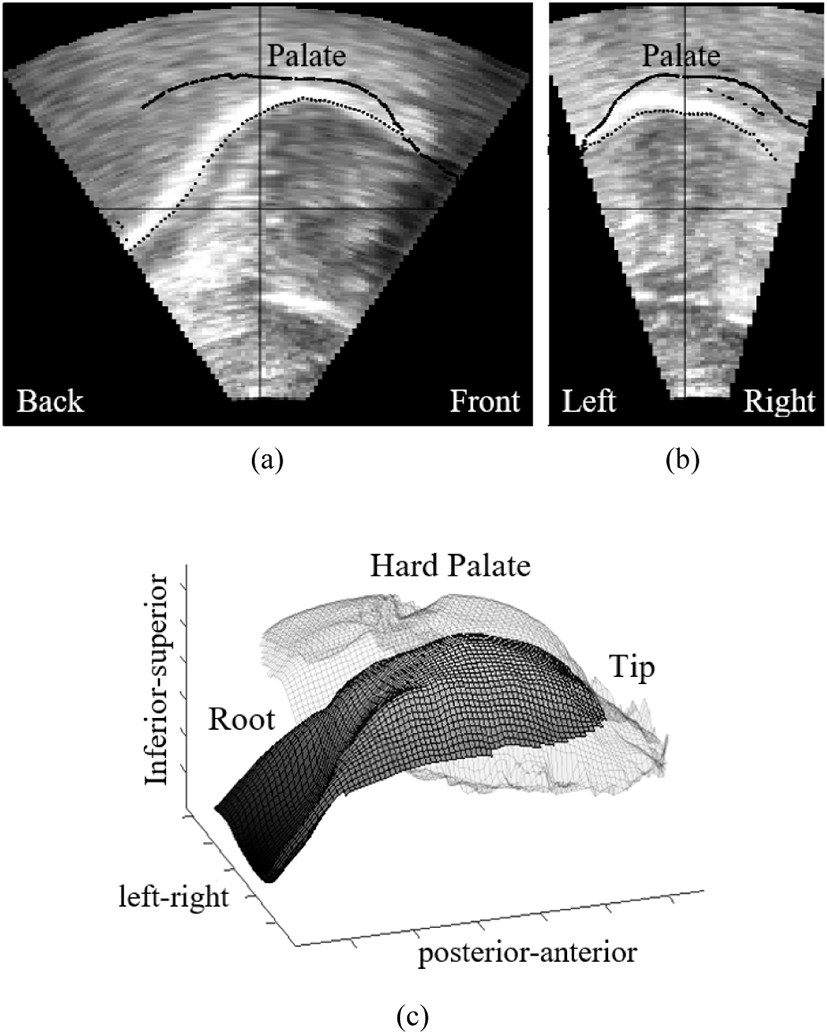
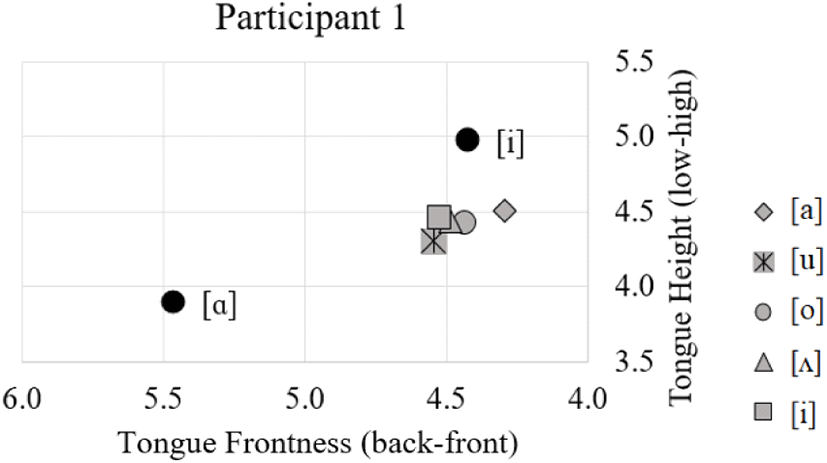
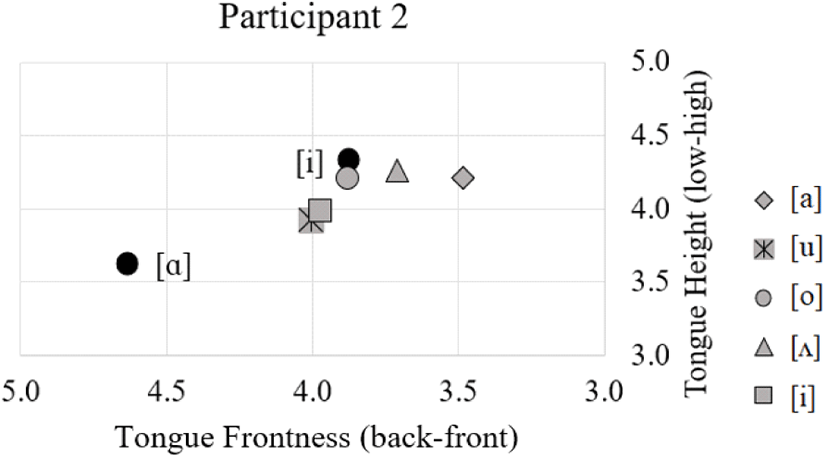
The tongue gestures of these participants are very similar across different vowel contexts with little variation in tongue height predictable from vowel context. Figure 7 and 8 display the anatomical distance measures for tongue body height (y-axis) and tongue root frontness (x-axis) for participants 1 and 2. The results indicate that during the lateral (gray dots), the tongue is in a position more similar to the high front vowel [i] (black dot) than the low back vowel [α]. The close proximity of these lateral tokens (within 6 mm in every case) and the lack of a clear pattern based on vowel context indicate that there is little within-speaker or vowel-dependent variation.
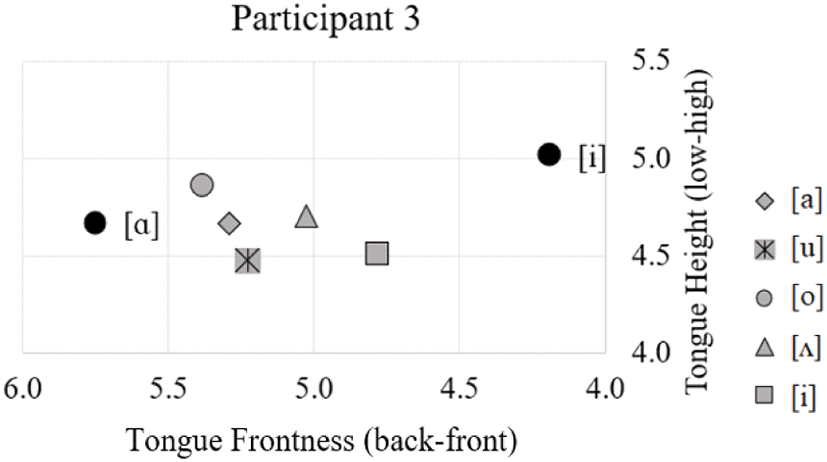
In contrast with participant 1 and 2, the third participant (P3)’s [l] production was produced with an apico-dental occlusion, a mid tongue body position and no grooving (Figure 9). The occlusion is symmetrical and relatively small in comparison to that of the first participants. The preceding vowel does impact the height of the tongue body, but only slightly as indicated in Figure 10. For the target sound (gray dots), the tongue is in a position between the high front vowel [i] and the low back vowel [α] (black dots).
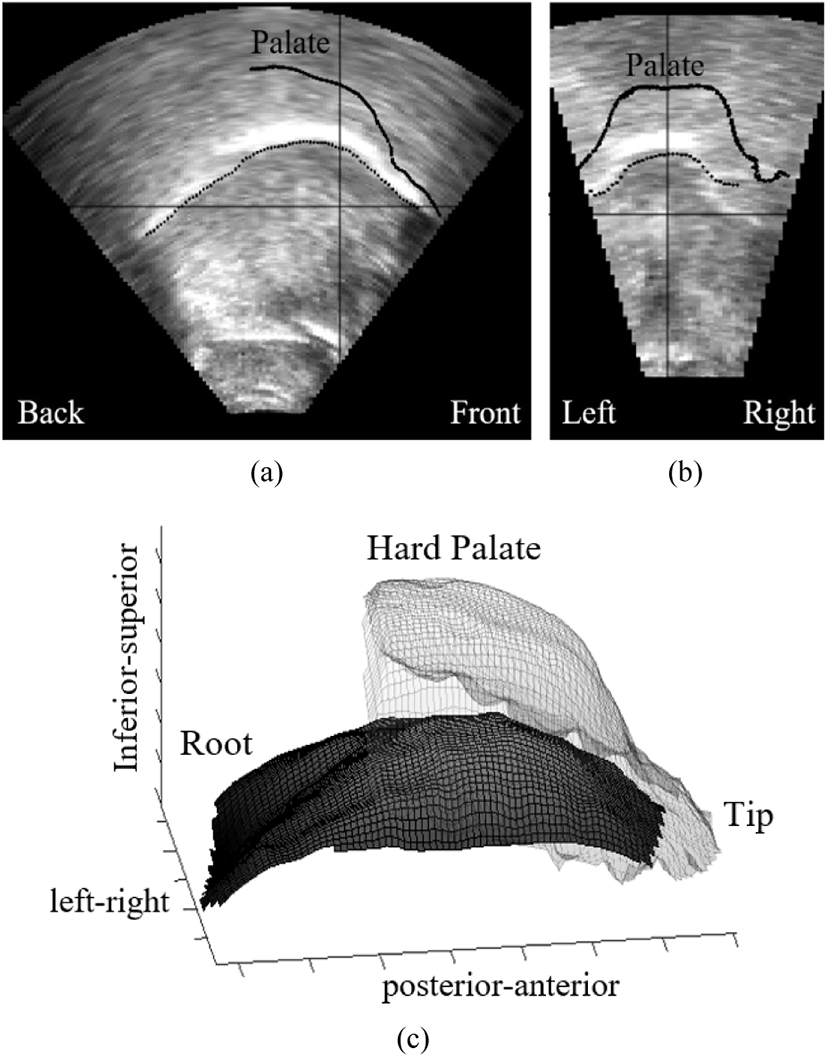
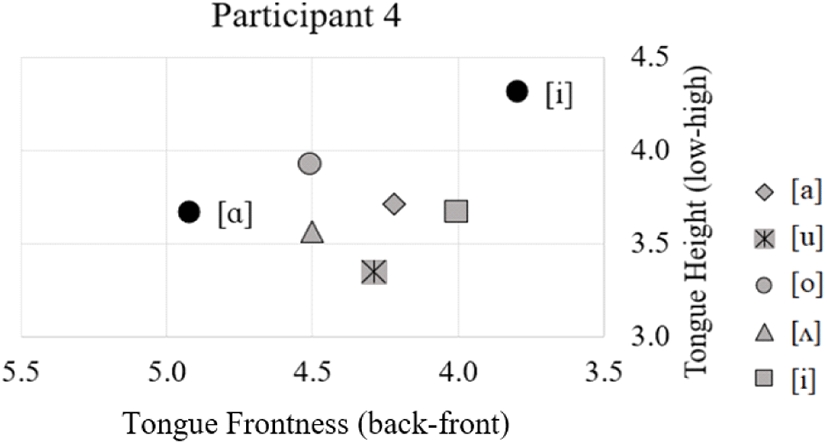
The most remarkable tongue shape came from the fourth participant (P4); this participant produced the [l] with a retroflex articulation, curling the tip of the tongue posteriorly so that the sublaminal surface comes in contact with the palate. The tongue body is in a mid position and the tongue root is not advanced. However, this particular articulation seems to be highly dependent on the preceding vowel. Retroflex articulation was found in the context of the vowels /u, Λ, o, α/ (Figure 11), but in the context of the front vowel /i/ (Figure 12) this speaker produced a long occlusion between the tongue blade and alveolar region from the incisors to the most posterior molars on both sides, and a higher tongue body. Additionally, the tongue root is more advanced in the /i/ vowel context in comparison to the others. Figures 11 and 12 display example tokens in the context of the vowels [α] and [i] in two intersecting two-dimensional planes (a, b) and a composite three-dimensional image (c). The distance measures for tongue body height (y-axis) and tongue root frontness (x-axis) are presented in Figure 13.
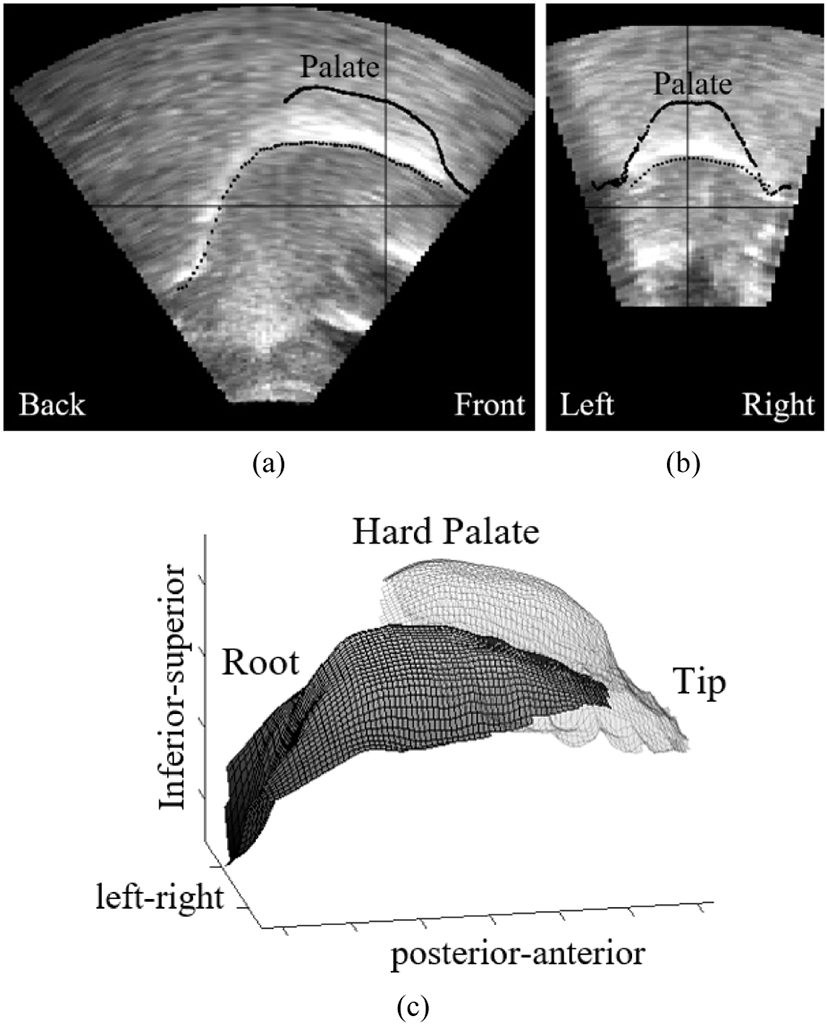
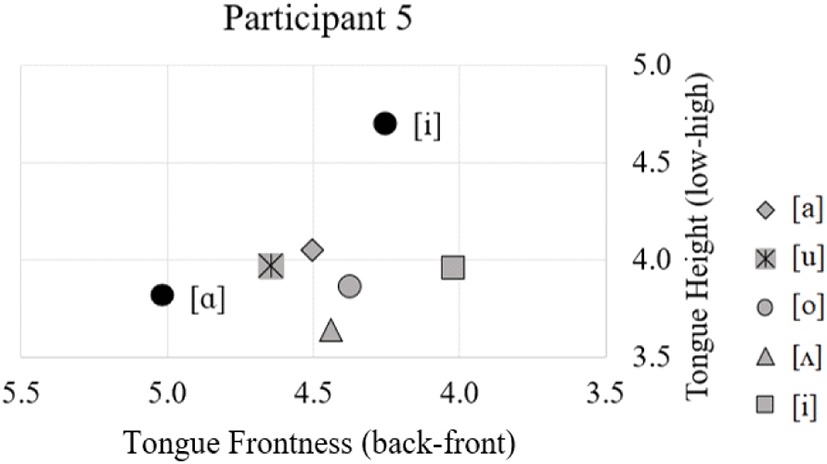
Similar to participant 1 and 2, the fifth participant (P5) produced [l] with an asymmetrical occlusion, this time on the right side, but the asymmetry was much stronger than the first two. This occlusion extends from the right incisors to the most anterior molar. This leaves an opening between the left side of the tongue and the left alveolar ridge (Figure 14). There is more within-speaker and vowel-dependent variation for this participant compared to participants 1 and 2 as indicated in Figure 15. This participant differs from participants 1 and 2 in terms of the tongue body height and tongue root frontness. The tongue body is neutral for all vowels but it is slightly higher after /i/. The tongue root is more advanced after /i/ than it is for the other vowels.
4. Discussion
The results from this study revealed a large amount of individual variation on the articulation of Korean lateral [l] that has not been reported previously. According to previous articulatory research on Korean liquids (Gick et al., 2006; Lee et al., 2015; Oh, 2002; Oh & Gick, 2002), a tongue tip occlusion and tongue body raising were described as the general characteristics of Korean lateral [l]. However, the results of this study show that there is no single pattern that is consistent across speakers. This does not imply that the variety of articulatory realizations of [l] are perceptually distinct among Korean listeners. Indeed, it is well known that articulatory variation need not be perceptually salient, as demonstrated, for example, by Lawson et al. (2011) for Scottish English postvocalic rhotics.
Even though all participants in this study showed an anterior occlusion for the word-final Korean lateral, the place of articulation and the size of the occlusion varied across speakers. That is, for the place of articulation, four different places were observed (i.e. apico-dental, lamino-postalveolar, lamino-alveolar, and retroflex). For the size of the occlusion, two participants had a small central occlusion, whereas the other three showed a large occlusion that extends from the incisors to the molars. The large occlusions were articulated asymmetrically. Previous literature on Korean laterals did not mention the asymmetry of the tongue movement due to methodological limitations, but with 3D imaging methods, our data reveals that asymmetry is present in Korean laterals produced by some speakers.
In addition, different from the previous literature, our data show that the tongue body raising and tongue root fronting gestures may not be necessary for the articulation of Korean lateral. Although two of the participants showed the tongue body raising and tongue root fronting (grooving) movements as discussed in the previous literature, those movements were not observed from the other three participants. Instead, they exhibited a neutral tongue body and tongue root position. The variation shown in the tongue body and tongue root gestures seems to be closely tied to the tongue tip gesture. A dental occlusion requires that the entire tongue advances in order for the tongue tip to reach the teeth. Retroflex occlusions also require that the tongue body moves forward so that the tongue tip can curl back. As a consequence, the tongue body cannot raise to the same degree as in the other places of articulation. Therefore, the tongue body position and tongue root advancement are largely dependent on the location of the coronal occlusion.
The tongue body raising and tongue root fronting gestures also seem to have an interdependent tendency. The results of this study reveal that the participants who had tongue body raising also exhibited some tongue root fronting gesture and grooving. This shows that a forward movement of the tongue root tends to be accompanied by a raising movement of the tongue body, thus having a facilitative effect on tongue body raising, as asserted by Archangeli & Pulleyblank (1994) and Cavar et al. (2017). Hall & Hall (1980) and Halle & Stevens (1969) also report similar results and maintain that tongue body raising is enhanced by tongue root advancement, whereas tongue body lowering is enhanced by tongue root retraction.
The vowel context seems to be another cause of articulatory variation, and it particularly has an influence on the retroflex articulation. The data of this study revealed that a retroflex articulation is not allowed in the context of the vowel /i/, while it was consistently observed in the other vowel contexts. Previously, physiological explanations have been proposed to account for this phenomenon. For the front vowel /i/, the tongue blade is fronted and the tongue body is raised. This tongue shape is inherently less compatible with a retroflex articulation because it reduces the size of the front cavity (Hamann, 2003). Several studies such as Dixit (1990), Dixit & Flege (1991), and Simonsen et al. (2000) also reported similar results, illustrating the articulatory variation of retroflex segments according to the adjacent vowel. According to them, retroflex consonants were articulated far more back in the /α/ or /u/ vowel context (e.g. alveolar or post-alveolar area) than in the /i/ context (e.g. dental area).
However, other than the retroflex articulation, the articulation of Korean lateral [l] does not seem to be greatly affected by preceding vowels in any predictable way when the measurements were recorded at the midpoint of the tokens. Although the initial portion of the lateral might be affected by the preceding vowels because of the coarticulation effect, the tongue gestures may be less affected by the vowels as the articulation of the lateral proceeds.
Since the Korean lateral has no contrasting rhotic sound to cause perceptual confusion, based on Dispersion Theory (Flemming, 1995, 2017; Liljencrants & Lindblom, 1972; Lindblom, 1990; etc.) we hypothesized that the Korean lateral [l] might occupy a large articulatory and acoustic space allowing greater variation. This is consistent with previous studies that examined vowel-dependent acoustic variability, but it is not predicted from prior articulatory studies of Korean laterals. Using a novel 3D/4D ultrasound methodology to image the tongue surface in three dimensions at specific instances in time, this study revealed substantial between-speaker articulatory variation, but relatively small and unpredictable vowel-dependent variation.
Laterals in general are often characterized by high articulatory and acoustic variation (Charles & Lulich, 2018; Ladefoged & Maddieson, 1996; Proctor, 2011), however the effects on perception is not well understood. Therefore, future research should investigate the role and scope of variation in the production and perception of lateral sounds in Korean and other languages.