Phonetics
한국어 음소 최소대립쌍의 계량언어학적 연구: 초성 자음을 중심으로
정지은
1
,
*
A quantitative study on the minimal pair of Korean phonemes: Focused on syllable-initial consonants
Jieun Jung
1
,
*
Author Information & Copyright ▼
1Department of Korean Language and Literature, Hankuk University of Foreign Studies, Seoul, Korea
© Copyright 2019 Korean Society of Speech Sciences. This is an Open-Access article distributed under the terms of the
Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/4.0/) which permits
unrestricted non-commercial use, distribution, and reproduction in any
medium, provided the original work is properly cited.
Received: Feb 02, 2019; Revised: Mar 16, 2019; Accepted: Mar 18, 2019
Published Online: Mar 31, 2019
국문초록
이 연구의 목적은 한국어 음소의 최소대립쌍 출현 양상에 대해 계량언어학적으로 알아보는 것이다. 최소대립쌍은 한 언어에서 음소의 체계를 세우는 데 중요한 역할을 하고, 기능부담량의 측정에도 중요한 척도가 됨에도 불구하고 아직까지 한국어 음소의 최소대립쌍에 대한 전면적인 연구가 이루어지지 않았다. 이를 위해 『우리말샘』의 표제어 325,715개의 발음을 대상으로 초성 위치에서의 자음 최소대립쌍의 개수를 절대수치와 상대수치로 산출하고, 최소대립쌍을 이루는 두 단어의 품사 관계에 대해서 분석했다. 『우리말샘』을 연구의 대상으로 삼은 이유는 최소대립쌍 분석은 기본적으로 사전을 통해서 이루어져야 한다고 판단했고, 한국어 사전 중 규모가 가장 크기 때문이다. 연구 결과는 다음과 같다. 첫째, 최소대립쌍은 총 153가지, 337,135개였다. 개수가 많은 음소 쌍(/ㅅ-ㅈ/, /ㄱ-ㅅ/, /ㄱ-ㅈ/, /ㄱ-ㅂ/, /ㄱ-ㅎ/)은 평음의 비중이 높고, 개수가 적은 음소 쌍(/ㅃ-ㅋ/, /ㄹ-ㅃ/, /ㅉ-ㅋ/, /ㄸ-ㅋ/, /ㅆ-ㅋ/)은 경음의 비중이 높았다. 최소대립쌍 형성에 많은 역할을 담당하는 음소를 개별 음소 단위에서 살펴보면 /ㄱ, ㅅ, ㅈ, ㅂ, ㅊ/ 순으로 높게 나타났는데, 경구개음의 비율이 높게 나타난 것이 특징적이었다. 삼지적 상관속을 이루는 장애음의 최소대립쌍 관계에도 조음 위치와 조음 방법에 따라 차이가 나타났다. 최소대립쌍의 절대수치와 상대수치의 상관계수는 0.937로 높은 상관관계를 보였다. 둘째, 최소대립쌍을 이루는 두 단어의 품사는 ‘명사-명사’의 최소대립쌍이 70.25%로 가장 많았고, 그다음으로 ‘동사-동사’ 쌍이 14.77%로 나타나 이 두 유형이 전체 85% 이상을 차지했다. 초성 최소대립쌍의 품사 일치율은 87.91%로 나타나 최소대립쌍은 의미 형태적으로도 비슷한 범주로 묶일 수 있음을 확인할 수 있었다. 이 연구의 결과는 한국어 음소와 관련된 기초 자료로서 국어학, 언어 병리학, 언어 교육, 언어 습득, 음성 공학 등의 다양한 응용 분야에서 유용하게 활용될 수 있을 것이다.
Abstract
The paper investigates the minimal pair of Korean phonemes quantitatively. To achieve this goal, I calculated the number of consonant minimal pairs in the syllable-initial position as both raw counts and relative counts, and analyzed the part of speech relations of the two words in the minimal pair. 『Urimalsaem』 was chosen as the object of this study because it was judged that the minimal pair analysis should be done through a dictionary and it is the largest among Korean dictionaries. The results of the study are summarized as follows. First, there were 153 types of minimal pairs out of 337,135 examples. The ranking of phoneme pairs from highest to lowest was ‘ㅅ-ㅈ, ㄱ-ㅅ, ㄱ-ㅈ, ㄱ-ㅂ, ㄱ-ㅎ, ..., ㅆ-ㅋ, ㄸ-ㅋ, ㅉ-ㅋ, ㄹ-ㅃ, ㅃ-ㅋ’. The phonemes that played a major role in the formation of the minimal pair were /ㄱ, ㅅ, ㅈ, ㅂ, ㅊ/, in that order, which showed a high proportion of palatals. The correlation between the raw count of minimal pairs and the relative count of minimal pairs was found to be quite high r=0.937. Second, 87.91% of the minimal pairs shared the part of speech (same syntactic category). The most frequently observed type has been ‘noun-noun’ pair (70.25%), and ‘vowel-vowel’ pair (14.77%) was the next ranking. It can be indicated that the minimal pair could be grouped into similar categories in terms of semantics. The results of this study can be useful for various research in Korean linguistics, speech-language pathology, language education, language acquisition, speech synthesis, and artificial intelligence-machine learning as basic data related to Korean phonemes.
Keywords: 최소대립쌍; 사전; 발음; 초성; 자음; 품사; 기능부담량
Keywords: minimal pair; dictionary; syllable-initial; consonant; part of speech; functional load
1. 서론
이 연구의 목적은 한국어 음소의 최소대립쌍 출현 양상에 대해 계량언어학적으로 알아보는 것이다. 최소대립쌍(minimal pair)1은 현대 음운론 연구에서 가장 기본적인 개념 중 하나로, 동일한 위치에 놓인 하나의 소리만 다르고 나머지 소리는 모두 같은데도 불구하고 서로 구별되는 두 개의 단어를 묶어 최소대립쌍이라고 부른다(Lee, 2010:119). 최소대립쌍은 한 언어에서 음소의 체계를 세우는 데 중요한 역할을 하고, 기능부담량(functional load)2의 측정에도 중요한 척도가 됨에도 불구하고 아직까지 한국어 음소의 최소대립쌍에 대해 전면적이고 다각적으로 살핀 연구는 찾아보기 어렵다. 최소대립쌍의 분석은 기본적으로 사전을 통해서 이루어져야 한다(Jin, 1996:169; Kim & Kang, 1997:6; Kim et al., 2014:118; Lee et al., 1987:120). 하지만 사전의 분석은 방대한 작업이기 때문에 현실적인 어려움으로 인해 연구가 이루어지기 쉽지 않았다.
한국어 음소의 최소대립쌍을 분석한 종합적인 연구는 없지만 부분적으로 살펴본 논의로는 Jin(1996), Kim et al.(2014), Lee et al.(1987) 이 있다3. Lee et al.(1987)은 한국정신문화연구원에서 간행한 『한국어표준발음사전』에 등재된 92,691개 표제어의 발음을 대상으로 음소 및 음소열의 출현 빈도, 최소대립쌍을 분석했다. 이 연구는 최초로 한국어 음소의 최소대립쌍에 대한 분석을 시도한 점에서는 의의가 있으나 ‘아람’과 ‘사람’의 관계도 최소대립쌍으로 인정한 것에서 볼 수 있듯이 공백소와 음소도 하나의 쌍으로 보고 분석한 것, 최소대립쌍의 개수 결과에 대한 해석 없이 결과만 평면적으로 나열한 것이 한계라고 할 수 있다. Jin(1996)은 한국방송공사가 펴낸 『한국어발음대사전』의 65,291개 표제어의 발음을 대상으로 모음 최소대립쌍의 수를 세어 모음과 모음 간에 나타나는 대립의 정도를 통해 기능부담량을 밝히고, /ㅔ/와 /ㅐ/ 모음이 합류되는 것을 기능부담량의 관점에서 살폈다. 이 연구는 음운 변화의 양상을 최소대립쌍과 기능부담량의 관점에서 해석하고자 한 점에서는 의의가 있으나 이러한 연구 목적과 관련된 특정 음소의 대립쌍만을 분석하여 전반적인 모음 대립의 양상을 확인할 수 없다는 것이 한계라고 할 수 있다. Kim et al.(2014)은 음성학 관련 연구자를 위하여 최소대립쌍 검색 도구를 개발하여 제안한 연구이다. 이 연구에서 제안한 도구를 사용하면 Shin(2010)의 발음사전(『연세한국어사전』)에 수록된 표제어 47,401개에 대한 최소대립쌍 검색이 가능하다고 했다. 이 검색 도구는 단어와 음소 검색뿐만 아니라 어종, 품사에 대한 세부적인 검색도 가능하다고 했지만 실제로 찾아서 사용할 수가 없어서 그 효율성은 확인이 불가능했다.
이상의 선행 연구에서 확인할 수 있듯이 방대한 사전 자료를 중심으로 한국어 음소의 최소대립쌍을 계량적으로 분석한 사례가 거의 없다고 볼 수 있다. 따라서 이 연구에서는 『우리말샘』의 표제어를 대상으로 초성 위치 자음의 최소대립쌍과 관련된 정보를 계량적으로 추출해 보고자 한다.
최소대립쌍의 개수는 절대수치와 상대수치로 측정할 수 있고, 상대수치는 두 가지 방법으로 계산이 가능하다. 첫 번째 방법은 최소대립쌍의 절대수치를 전체 단어의 수로 나누는 것이고, 두 번째 방법은 최소대립쌍의 절대수치를 최소대립쌍을 이루는 두 음소를 포함하는 단어의 개수로 나누는 것이다. 코퍼스 내에서 빈도가 낮은 음소는 최소대립쌍의 개수도 적을 가능성이 높다. 그러나 두 번째 방법으로 산출한 상대수치는 음소의 빈도까지 고려하여 상대적인 비교가 가능하다는 이점이 있다4. 따라서 본 연구에서는 최소대립쌍의 개수를 절대수치와 두 번째 방법의 상대수치로 산출하고 그 두 수치 간의 상관관계도 살펴보겠다.
Kim et al.(2014:120)은 최소대립쌍은 동일 위치에 놓인 하나의 음소만 다르고 나머지 음소는 모두 같기 때문에 두 단어는 인지적으로 비슷한 범주로 묶일 가능성이 높고, 따라서 동일한 품사 내에 최소대립쌍이 존재할 가능성이 품사 범주를 넘어서 존재할 가능성보다 더 높다고 했다. Brown(1988, 1991), Catford (1987), Derwing & Munro(2015), Levies & Cortes(2008)Munro & Derwing(2006) 등은 영어 발음 교육의 우선순위를 매길 때 최소대립쌍의 개수가 중요한 기준이 된다고 했다. 예를 들어 /e/-/æ/나 /p/-/b/의 경우 만들 수 있는 최소대립쌍의 개수가 많고 사용 빈도가 높기 때문에 우선적으로 교육해야 하고, 반대로 /u:/-/ʊ/나 /ʃ/-/ʒ/와 같은 음소 쌍은 사용 빈도도 낮을 뿐만 아니라 원어민도 혼용해서 쓰는 경우가 있기 때문에 발음 교육에서 크게 중요하지 않다고 주장했다. 그리고 최소대립쌍을 이루는 두 단어의 품사가 같으면 기능부담량이 높고 다르면 기능부담량이 낮기 때문에 최소대립쌍을 기준으로 기능부담량을 설정하고 발음 교육에 적용할 때는 품사와의 관련성도 고려해야 한다고 했다5. 따라서 본 연구에서는 최소대립쌍과 품사와의 관계도 살펴보겠다.
최소대립쌍 관련 정보를 다양한 측면에서 분석하는 것은 한국어 음소 체계의 특성을 밝히는 데 중요한 단서가 될 수 있을 것이고, 한국어학뿐만 아니라 한국어 교육학, 언어 병리학, 음성 공학 분야에서 활용할 수 있는 기초 자료로 제공될 수 있을 것이다. 이에 이 연구에서는 다음과 같은 연구 문제를 중심으로 살펴보고자 한다.
2. 연구 방법
이 연구의 분석 대상이 된 사전은 『우리말샘』 이었다. 이 사전을 분석의 바탕 자료로 삼은 이유는 이 사전이 첫째, 어휘의 규모가 역대 최대인 사전이고, 둘째, 표제어의 표준 발음의 표기가 확대된 사전이며, 셋째, 저작권이 개방된 사전이기 때문이다6.
『우리말샘』의 표제어 수는 약 1,000,000여 개였는데 표제어 중 잘못된 형태, 지역어(방언), 북한어, 옛말, 자모형을 걸러낸 후, 품사 정보와 원어 정보가 없는 표제어도 제외했다. 품사가 두 개 이상인 표제어는 두 개의 표제어로 분리하고, 발음이 두 개 이상인 표제어는 표제어별로 한 개씩의 대표 발음을 정했다. 이러한 자료 구성 원칙에 따라 선정된 표제어의 수는 총 458,365개였다7. 각 표제어별로 발음, 품사, 원어 정보를 부여한 후 이 네 정보가 모두 같은 동음이의어는 하나만 남겼다8. 이런 작업을 거쳐 발음사전을 완성했고 총 325,717개였다. 완성된 자료는 Python(파이썬)으로 분석 프로그램을 설계하여 최소대립쌍의 개수를 분석했다.
표 1은 최소대립쌍 분석을 위해 구축한 발음 사전의 예이다.
표 1. | Table 1.
발음 사전의 예시 | Example of pronunciation dictionary
| ID |
표제어 |
발음형 |
음절형 |
음소형 |
품사 |
원어 |
| 000001 |
가방 |
가방 |
가두방말 |
ㄱ초ㅏ중J종
ㅂ초ㅏ중O종 |
명사 |
고유어 |
| 000002 |
가방 |
가방 |
가두방말 |
ㄱ초ㅏ중J종
ㅂ초ㅏ중O종 |
명사 |
한자어 |
| 000003 |
가오리 |
가오리 |
가두오중리말 |
ㄱ초ㅏ중J종
C초ㅗ중J종
ㄹ초ㅣ중J종 |
명사 |
고유어 |
| 000004 |
가장 |
가장 |
가두장말 |
ㄱ초ㅏ중J종
ㅈ초ㅏ중O종 |
명사 |
한자어 |
| 000005 |
가장 |
가장 |
가두장말 |
ㄱ초ㅏ중J종
ㅈ초ㅏ중O종 |
부사 |
고유어 |
| 000006 |
간략하다 |
갈랴카다 |
갈두랴중카중다말 |
ㄱ초ㅏ중ㄹ종
ㄹ초ㅑ중J종
ㅋ초ㅏ중J종
ㄷ초ㅏ중J종 |
형용사 |
혼종어 |
| 000007 |
강가 |
강까 |
강두까말 |
ㄱ초ㅏ중O종
ㄲ초ㅏ중J종 |
명사 |
한자어 |
| 000008 |
꽁지 |
꽁지 |
꽁두지말 |
ㄲ초ㅗ중O종
ㅈ초ㅣ중J종 |
명사 |
고유어 |
| … |
… |
… |
… |
… |
… |
… |
| 325717 |
힁하다 |
힝하다 |
힝두하중다말 |
ㅎ초ㅣ중O종
ㅎ초ㅏ중J종
ㄷ초ㅏ중J종 |
형용사 |
고유어 |
Download Excel Table
먼저 표제어마다 아이디, 품사 정보, 원어 정보를 부여했다. 발음형은 음절 단위로 분리하여 개별 음절에서 어두, 어중, 어말 정보를 확인했고, 음절형을 음소 단위로 분리하여 초성, 중성, 종성 정보를 확인했다.
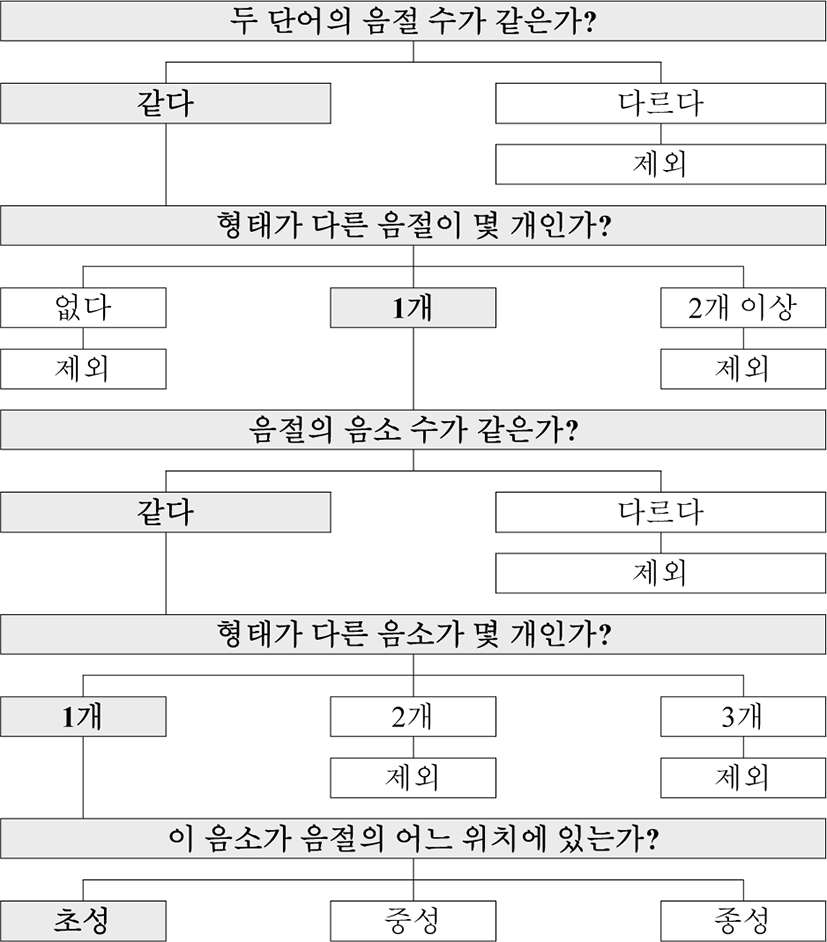
그림 1은 최소대립쌍을 분석하는 방법에 대한 절차를 단계별로 정리하여 보인 것이다.
하나의 표제어에 대해서 위와 같은 방법으로 최소대립쌍을 찾았다. 예를 들어 기준 단어가 아이디 000001 ‘가방’인 경우이다. ‘가방’과 ‘가방’ 이외의 325,716개의 단어를 각각 비교했다. 음절 수가 같은지, 음절 수가 같다면 형태가 다른 음절이 몇 개인지, 형태가 다른 음절이 1개라면 음절을 구성하는 음소의 수가 같은지, 음소의 수가 같다면 형태가 다른 음소가 몇 개인지, 형태가 다른 음소가 1개라면 이 단어가 ‘가방’의 최소대립쌍이 되는 것이다. 이에 해당하는 단어의 예로는 ‘사방, 고방, 가상, 가봉, 가반’ 등이 있을 수 있는데 ‘가방’과 비교하여 형태가 다른 음소가 음절 내 초성, 중성, 종성 중 어느 위치에 있는지를 확인했고, 음소 쌍별 최소대립쌍의 개수(절대수치)를 산출했다.
표 2는 분석 대상 자료를 품사별로 나누어 빈도와 비율을 보인 것이다.
표 2. | Table 2.
품사별 구성 | Distribution in the classified the part of speech
|
|
빈도 |
비율(%) |
| 명사 |
249,109 |
76.48 |
| 대명사 |
334 |
0.10 |
| 수사 |
169 |
0.05 |
| 동사 |
49,210 |
15.11 |
| 형용사 |
12,084 |
3.71 |
| 관형사 |
3,237 |
0.99 |
| 부사 |
10,801 |
3.32 |
| 조사 |
151 |
0.05 |
| 감탄사 |
622 |
0.19 |
| 계 |
325,717 |
100.0 |
Download Excel Table
가장 높은 비율을 차지한 품사는 76.48%를 보인 명사였고, 가장 낮은 비율을 차지한 품사는 0.05%를 보인 조사였다. 동사가 형용사에 비해 4.07배 높은 빈도를 보인다는 것과 부사가 관형사에 비하여 3.34배 높은 빈도를 보인다는 것이 특징적이다. 9개의 품사 중 5개인 대명사, 수사, 관형사, 조사, 감탄사의 비율은 1% 미만이고, 명사와 동사 두 품사의 비율의 합은 91.59%를 차지하고 있었다.
3. 연구 결과
초성의 위치에서 대립 가능한 음소의 쌍은 산술적으로 153(=18×17×½)개이다. 분석 결과 모든 음소 쌍에서 최소대립쌍이 존재했고 그 개수는 총 337,135개였다.
3.1. 최소대립쌍의 개수 분석
표 3은 초성 위치의 최소대립쌍의 절대수치를 나타낸 분포표이고, 표 4는 상대수치를 나타낸 분포표이다. 본 절에서의 상대수치는 1장에서 살펴본 상대수치 계산의 두 방법 중 두 번째 방법으로 산출한 수치로, 최소대립쌍의 절대수치를 최소대립쌍을 구성하는 개별 음소가 하나라도 포함된 단어들의 수로 나누어 산출한 값이다.
표 3. | Table 3.
최소대립쌍의 절대수치 | Raw count of minimal pairs
|
|
ㄱ |
ㄲ |
ㄴ |
ㄷ |
ㄸ |
ㄹ |
ㅁ |
ㅂ |
ㅃ |
ㅅ |
ㅆ |
ㅈ |
ㅉ |
ㅊ |
ㅋ |
ㅌ |
ㅍ |
ㅎ |
| ㄱ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㄲ |
1,524 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㄴ |
6,052 |
364 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㄷ |
5,777 |
403 |
3,552 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㄸ |
673 |
576 |
305 |
919 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㄹ |
3,082 |
318 |
1,652 |
930 |
411 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㅁ |
8,140 |
499 |
4,401 |
3,804 |
498 |
1,861 |
|
|
|
|
|
|
|
|
|
|
|
|
| ㅂ |
9,064 |
547 |
3,961 |
4,518 |
583 |
1,851 |
6,917 |
|
|
|
|
|
|
|
|
|
|
|
| ㅃ |
383 |
626 |
218 |
250 |
422 |
114 |
350 |
1,381 |
|
|
|
|
|
|
|
|
|
|
| ㅅ |
10,023 |
671 |
4,588 |
5,415 |
561 |
1,504 |
6,685 |
7,466 |
434 |
|
|
|
|
|
|
|
|
|
| ㅆ |
928 |
871 |
253 |
360 |
849 |
525 |
595 |
796 |
736 |
993 |
|
|
|
|
|
|
|
|
| ㅈ |
9,978 |
659 |
4,209 |
5,328 |
724 |
1,557 |
5,792 |
7,068 |
384 |
12,931 |
613 |
|
|
|
|
|
|
|
| ㅉ |
760 |
889 |
243 |
505 |
951 |
508 |
589 |
649 |
654 |
611 |
1,714 |
1,171 |
|
|
|
|
|
|
| ㅊ |
7,084 |
744 |
3,054 |
3,581 |
935 |
1,291 |
4,283 |
5,289 |
600 |
8,294 |
1,281 |
8,632 |
1,476 |
|
|
|
|
|
| ㅋ |
1,225 |
343 |
475 |
362 |
121 |
586 |
539 |
603 |
89 |
505 |
176 |
497 |
121 |
423 |
|
|
|
|
| ㅌ |
3,558 |
367 |
2,173 |
2,863 |
747 |
640 |
2,149 |
2,563 |
277 |
2,987 |
450 |
3,025 |
527 |
2,641 |
311 |
|
|
|
| ㅍ |
4,228 |
558 |
2,027 |
1,990 |
482 |
1,036 |
3,175 |
2,934 |
459 |
2,911 |
524 |
2,820 |
528 |
2,275 |
640 |
1,307 |
|
|
| ㅎ |
8,826 |
562 |
4,034 |
3,760 |
419 |
1,543 |
4,632 |
4,810 |
290 |
5,530 |
403 |
5,374 |
397 |
3,774 |
2,043 |
2,471 |
2,820 |
|
|
|
81,305 |
10,521 |
41,561 |
44,317 |
10,176 |
19,409 |
54,909 |
61,000 |
7,667 |
72,109 |
12,067 |
70,762 |
12,293 |
55,657 |
9,059 |
29,056 |
30,714 |
51,688 |
Download Excel Table
표 4. | Table 4.
최소대립쌍의 상대수치 | Relative count of minimal pairs
|
|
ㄱ |
ㄲ |
ㄴ |
ㄷ |
ㄸ |
ㄹ |
ㅁ |
ㅂ |
ㅃ |
ㅅ |
ㅆ |
ㅈ |
ㅉ |
ㅊ |
ㅋ |
ㅌ |
ㅍ |
ㅎ |
| ㄱ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㄲ |
0.012 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㄴ |
0.042 |
0.005 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㄷ |
0.032 |
0.004 |
0.027 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㄸ |
0.006 |
0.014 |
0.005 |
0.009 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㄹ |
0.022 |
0.005 |
0.019 |
0.007 |
0.007 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| ㅁ |
0.054 |
0.006 |
0.046 |
0.027 |
0.007 |
0.020 |
|
|
|
|
|
|
|
|
|
|
|
|
| ㅂ |
0.058 |
0.007 |
0.039 |
0.032 |
0.008 |
0.018 |
0.062 |
|
|
|
|
|
|
|
|
|
|
|
| ㅃ |
0.003 |
0.016 |
0.004 |
0.002 |
0.014 |
0.002 |
0.005 |
0.019 |
|
|
|
|
|
|
|
|
|
|
| ㅅ |
0.058 |
0.006 |
0.036 |
0.033 |
0.005 |
0.012 |
0.050 |
0.054 |
0.004 |
|
|
|
|
|
|
|
|
|
| ㅆ |
0.007 |
0.018 |
0.004 |
0.003 |
0.021 |
0.008 |
0.008 |
0.010 |
0.020 |
0.009 |
|
|
|
|
|
|
|
|
| ㅈ |
0.057 |
0.006 |
0.033 |
0.032 |
0.007 |
0.012 |
0.042 |
0.050 |
0.004 |
0.080 |
0.005 |
|
|
|
|
|
|
|
| ㅉ |
0.006 |
0.018 |
0.004 |
0.004 |
0.024 |
0.008 |
0.008 |
0.008 |
0.018 |
0.006 |
0.036 |
0.010 |
|
|
|
|
|
|
| ㅊ |
0.049 |
0.011 |
0.034 |
0.027 |
0.015 |
0.014 |
0.044 |
0.051 |
0.010 |
0.065 |
0.019 |
0.066 |
0.021 |
|
|
|
|
|
| ㅋ |
0.010 |
0.009 |
0.008 |
0.004 |
0.004 |
0.010 |
0.008 |
0.008 |
0.003 |
0.005 |
0.005 |
0.005 |
0.003 |
0.007 |
|
|
|
|
| ㅌ |
0.029 |
0.008 |
0.034 |
0.026 |
0.021 |
0.010 |
0.029 |
0.033 |
0.009 |
0.028 |
0.011 |
0.028 |
0.012 |
0.040 |
0.010 |
|
|
|
| ㅍ |
0.033 |
0.011 |
0.029 |
0.017 |
0.011 |
0.015 |
0.040 |
0.034 |
0.012 |
0.026 |
0.011 |
0.025 |
0.011 |
0.032 |
0.016 |
0.029 |
|
|
| ㅎ |
0.052 |
0.005 |
0.034 |
0.027 |
0.004 |
0.013 |
0.036 |
0.037 |
0.003 |
0.036 |
0.004 |
0.034 |
0.004 |
0.031 |
0.022 |
0.026 |
0.027 |
|
Download Excel Table
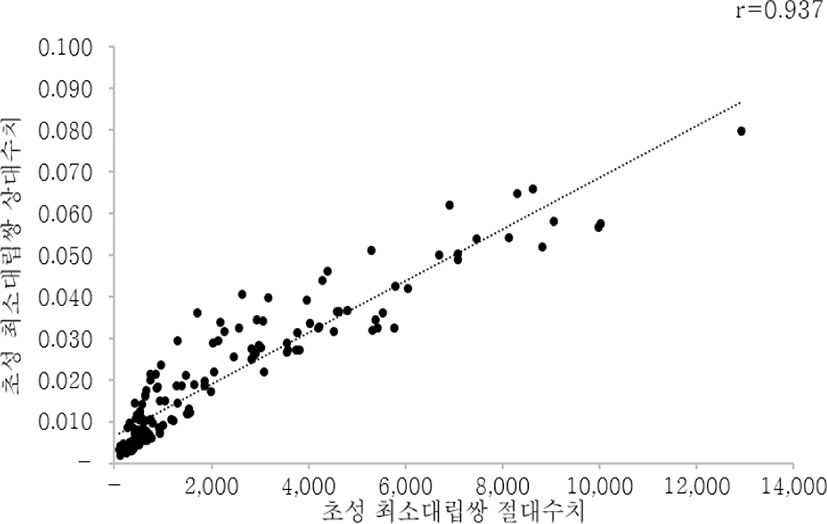
그림 2는 초성 최소대립쌍의 절대수치와 상대수치의 상관관계를 나타낸 것이다.
그림 2. | Figure 2.
초성 최소대립쌍의 절대수치와 상대수치의 상관관계 | Correlation between raw counts and relative counts
Download Original Figure
초성 최소대립쌍의 절대수치와 상대수치의 상관관계는 0.937로 높은 편이었다. 절대수치와 상대수치에 대한 잔차를 구한 결과 잔차의 값이 큰 음소 쌍은 /ㅆ-ㅉ/, /ㅊ-ㅌ/, /ㅌ-ㅍ/, /ㄴ-ㅌ/, /ㅁ-ㅍ/고, 반대로 잔차의 값이 작은 음소 쌍은 /ㄷ-ㅈ/, /ㄱ-ㅎ/, /ㄱ-ㄷ/, /ㄱ-ㅅ/, /ㄱ-ㅈ/였다.
표 5는 절대수치가 높은 쌍과 낮은 쌍을 15개씩(상하위 10%) 정리한 것이다. 전체 음소 쌍별 초성 최소대립쌍의 개수는 부록 1에 제시하였다.
표 5. | Table 5.
고빈도/저빈도 최소대립쌍(상·하위 10%) | Most and least frequently minimal pairs(top 10% and bottom 10%)
| 순위 |
초성 쌍 |
개수 |
비율(%) |
누적비율(%) |
| 1 |
ㅅ-ㅈ |
12,930 |
3.84 |
3.84 |
| 2 |
ㄱ-ㅅ |
10,023 |
2.97 |
6.81 |
| 3 |
ㄱ-ㅈ |
9,978 |
2.96 |
9.77 |
| 4 |
ㄱ-ㅂ |
9,063 |
2.69 |
12.46 |
| 5 |
ㄱ-ㅎ |
8,825 |
2.62 |
15.08 |
| 6 |
ㅈ-ㅊ |
8,631 |
2.56 |
17.64 |
| 7 |
ㅅ-ㅊ |
8,293 |
2.46 |
20.10 |
| 8 |
ㄱ-ㅁ |
8,138 |
2.41 |
22.51 |
| 9 |
ㅂ-ㅅ |
7,464 |
2.21 |
24.72 |
| 10 |
ㄱ-ㅊ |
7,084 |
2.10 |
26.83 |
| 11 |
ㅂ-ㅈ |
7,066 |
2.10 |
28.92 |
| 12 |
ㅁ-ㅂ |
6,915 |
2.05 |
30.97 |
| 13 |
ㅁ-ㅅ |
6,683 |
1.98 |
32.95 |
| 14 |
ㄱ-ㄴ |
6,053 |
1.80 |
34.75 |
| 15 |
ㅁ-ㅈ |
5,791 |
1.72 |
36.47 |
| : |
: |
: |
: |
: |
| 139 |
ㄲ-ㅋ |
343 |
0.10 |
99.08 |
| 140 |
ㄲ-ㄹ |
318 |
0.09 |
99.18 |
| 141 |
ㅋ-ㅌ |
311 |
0.09 |
99.27 |
| 142 |
ㄴ-ㄸ |
305 |
0.09 |
99.36 |
| 143 |
ㅃ-ㅎ |
290 |
0.09 |
99.45 |
| 144 |
ㅃ-ㅌ |
277 |
0.08 |
99.53 |
| 145 |
ㄴ-ㅆ |
254 |
0.08 |
99.60 |
| 146 |
ㄷ-ㅃ |
250 |
0.07 |
99.68 |
| 147 |
ㄴ-ㅉ |
243 |
0.07 |
99.75 |
| 148 |
ㄴ-ㅃ |
218 |
0.06 |
99.82 |
| 149 |
ㅆ-ㅋ |
176 |
0.05 |
99.87 |
| 150 |
ㄸ-ㅋ |
121 |
0.04 |
99.90 |
| 151 |
ㅉ-ㅋ |
121 |
0.04 |
99.94 |
| 152 |
ㄹ-ㅃ |
114 |
0.03 |
99.97 |
| 153 |
ㅃ-ㅋ |
89 |
0.03 |
100.0 |
| 계 |
337,135 |
100.0 |
100.0 |
Download Excel Table
초성에서 최소대립쌍을 가장 많이 이룬 음소 쌍은 /ㅅ-ㅈ/로 그 개수와 비율은 12,930개와 3.84%였고, 이어서 /ㄱ-ㅅ/ 쌍이 10,023개(2.97%)로 그 뒤를 따라 많았다. 반면에 가장 적은 음소 쌍은 /ㅃ-ㅋ/였는데, 그 개수와 비율은 89개와 0.03%로 /ㅃ/와 /ㅋ/가 초성 위치에서 대립하여 최소대립쌍을 이루는 경우는 매우 적었다.
상위 15개의 쌍은 전체 출현 최소대립쌍의 36.47%를 차지한 반면 하위 15개의 쌍은 1%도 되지 않아 출현 비율의 차이가 매우 컸다. 상위 15개 최소대립쌍은 ‘장애음과 장애음’의 쌍이 10개, ‘비음과 장애음’의 쌍이 5개였다. /ㄱ/는 15개 중 7개, /ㅅ/와 /ㅈ/는 15개 중 5개의 최소대립쌍에 나타났는데 상위 음소 쌍은 평음의 비중이 높았다. /ㅊ/도 3개의 최소대립쌍에 나타났는데 상위 최소대립쌍에 나타난 격음은 /ㅊ/가 유일했다. 한편 하위 최소대립쌍은 ‘장애음과 장애음’의 쌍이 9개, ‘비음/유음과 경음’의 쌍이 6개였다. /ㅃ/와 /ㅋ/는 15개 중 6개의 최소대립쌍에 나타났는데 하위 음소 쌍은 경음의 비중이 높았다. 그 뒤를 이어 /ㄴ/도 4개의 최소대립쌍에 나타났다.
상하위 음소 쌍을 통해 최소대립쌍을 이루는 데 가장 많이 사용되는 음소는 /ㄱ/고, 반대로 가장 덜 사용되는 음소는 /ㅃ/와 /ㅋ/일 것이라고 예상할 수 있다. 정확한 확인을 위하여 음소별 최소대립쌍 빈도를 분석한 결과는 표 6과 같다.
표 6. | Table 6.
음소별 최소대립쌍 빈도 분포 | Frequency distribution of minimal pairs by phoneme
| 순위 |
음소 |
빈도 |
비율(%) |
누적비율(%) |
| 1 |
ㄱ |
81,301 |
12.06 |
12.06 |
| 2 |
ㅅ |
72,103 |
10.69 |
22.75 |
| 3 |
ㅈ |
70,755 |
10.49 |
33.25 |
| 4 |
ㅂ |
60,988 |
9.05 |
42.29 |
| 5 |
ㅊ |
55,650 |
8.25 |
50.55 |
| 6 |
ㅁ |
54,906 |
8.14 |
58.69 |
| 7 |
ㅎ |
51,683 |
7.67 |
66.36 |
| 8 |
ㄷ |
44,315 |
6.57 |
72.93 |
| 9 |
ㄴ |
41,561 |
6.16 |
79.09 |
| 10 |
ㅍ |
30,713 |
4.56 |
83.65 |
| 11 |
ㅌ |
29,046 |
4.31 |
87.96 |
| 12 |
ㄹ |
19,411 |
2.88 |
90.84 |
| 13 |
ㅉ |
12,294 |
1.82 |
92.66 |
| 14 |
ㅆ |
12,066 |
1.79 |
94.45 |
| 15 |
ㄲ |
10,524 |
1.56 |
96.01 |
| 16 |
ㄸ |
10,171 |
1.51 |
97.52 |
| 17 |
ㅋ |
9,059 |
1.34 |
98.86 |
| 18 |
ㅃ |
7,668 |
1.14 |
100.0 |
| 계 |
674,270 |
100.0 |
100.0 |
Download Excel Table
가장 높은 빈도를 보인 음소는 /ㄱ/로 12.06%를 나타냈고, 이어서 /ㅅ, ㅈ, ㅂ, ㅊ/의 순서로 높게 나타났다. 반면에 가장 낮은 빈도를 보인 음소는 /ㅃ/로 1.14%에 불과했다. 표 5의 상위 15개에 포함된 음소 쌍의 음소가 표 6에서도 높은 빈도를 보였고, 표 5의 하위 15개에 포함된 음소 쌍의 음소는 표 6에서도 낮은 빈도를 보였다. 1위부터 9위까지는 /ㅊ/와 /ㅎ/를 제외하면 모두 평음과 비음이며, 10위부터 18위까지는 /ㄹ/를 제외하면 모두 경음과 격음이었다. 장애음 중에는 경음과 격음보다 평음이, 공명음 중에는 유음보다 비음이 최소대립쌍을 많이 만든다는 것을 알 수 있는데, /ㅊ/는 격음임에도 불구하고 8.25%로 높은 것이 특징적이다. /ㅉ/도 경음 중에서는 가장 높은 빈도를 나타냈다9.
초성마다 최소대립쌍을 가장 많이 만드는 음소도 다르게 나타났는데 결과는 표 7에 제시하였다.
표 7. | Table 7.
음소별 최고빈도 최소대립쌍 | Most frequently minimal pairs by phoneme
| 구분 |
음소 쌍 |
개수 |
비율(%) |
| 장애음 |
평음 |
ㄱ-ㅅ |
10,023 |
12.33 |
| ㄷ-ㄱ |
5,777 |
13.04 |
| ㅂ-ㄱ |
9,063 |
14.86 |
| ㅅ-ㅈ |
12,930 |
17.93 |
| ㅈ-ㅅ |
12,930 |
18.27 |
| 경음 |
ㄲ-ㄱ |
1,524 |
14.48 |
| ㄸ-ㅉ |
951 |
9.35 |
| ㅃ-ㅂ |
1,381 |
18.01 |
| ㅆ-ㅉ |
1,714 |
14.21 |
| ㅉ-ㅆ |
1,714 |
13.94 |
| 격음 |
ㅊ-ㅈ |
8,631 |
15.51 |
| ㅋ-ㅎ |
2,043 |
22.55 |
| ㅌ-ㄱ |
3,558 |
12.25 |
| ㅍ-ㄱ |
4,228 |
13.77 |
| 후음 |
ㅎ-ㄱ |
8,825 |
17.08 |
| 공명음 |
ㄴ-ㄱ |
6,053 |
14.56 |
| ㄹ-ㄱ |
3,081 |
15.87 |
| ㅁ-ㄱ |
8,138 |
14.82 |
Download Excel Table
평음은 최소대립쌍이 가장 많은 음소는 모두 조음 위치 또는 조음 방법에는 차이가 있으나 발성 유형이 같은 평음이었다. 경음의 경우 /ㄲ/와 /ㅃ/는 조음 위치와 방법은 동일하나 발성 유형이 다른 평음과 가장 많은 대립 쌍을 만들었고, /ㄸ/, /ㅉ/, /ㅆ/는 조음 위치와 방법은 다르나 발성 유형이 같은 경음과 가장 많은 대립 쌍을 만들었다. 격음은 일정하지가 않았는데 /ㅊ/는 조음 위치와 조음 방법을 공유하는 /ㅈ/와, /ㅋ/는 유기성 자질을 공유하는 /ㅎ/와, /ㅌ/, /ㅍ/는 /ㄱ/와 가장 많은 대립 쌍을 만들었다. 그렇지만 대체로 조음 위치나 발성 방법을 공유하는 음소와 최소대립쌍을 만드는 빈도가 높은 것으로 보인다. 반면에 공명음은 모두 /ㄱ/와 가장 많은 최소대립쌍을 만들었다.
장애음의 최소대립쌍만 따로 조금 더 구체적으로 살펴보겠다. 표 8은 삼지적 상관속을 이루는 장애음 내의 최소대립쌍을 정리하여 나타낸 것이다.
표 8. | Table 8.
양순음, 치경음, 경구개음, 연구개음의 최소대립쌍 | Minimal pairs of bilabials, alveolars, palatals, and velars
| 구분 |
음소 쌍 |
개수 |
비율(%) |
계 |
| 양순음 |
ㅂ-ㅃ |
1,381 |
28.93 |
4,774 |
| ㅂ-ㅍ |
2,934 |
61.46 |
| ㅃ-ㅍ |
459 |
9.61 |
| 치경음 |
ㄷ-ㄸ |
919 |
20.29 |
4,529 |
| ㄷ-ㅌ |
2,863 |
63.21 |
| ㄸ-ㅌ |
747 |
16.49 |
| ㅅ-ㅆ |
993 |
100.0 |
993 |
| 경구개음 |
ㅈ-ㅉ |
1,171 |
10.38 |
11,279 |
| ㅈ-ㅊ |
8,632 |
76.53 |
| ㅉ-ㅊ |
1,476 |
13.09 |
| 연구개음 |
ㄱ-ㄲ |
1,524 |
49.29 |
3,092 |
| ㄱ-ㅋ |
1,225 |
39.62 |
| ㄲ-ㅋ |
343 |
11.09 |
Download Excel Table
그림 3부터 그림 6까지는 삼지적 상관속을 이루는 장애음의 최소대립쌍 관계를 그림으로 나타낸 것이다10.
삼지적 상관속을 이루는 장애음의 최소대립쌍은 조음 위치와 조음 방법에 따라 차이를 보이고 있다. 연구개음 /ㄱ-ㄲ-ㅋ/는 ‘평음-경음’ 쌍의 비율이 가장 높고, ‘경음-격음’ 쌍의 비율이 가장 낮았다. 경구개음 /ㅈ-ㅉ-ㅊ/는 ‘평음-격음’ 쌍의 비율이 가장 높고, ‘평음-경음’ 쌍의 비율이 가장 낮았는데 연구개음의 양상과 매우 다르게 나타났다. 치경음 /ㄷ-ㄸ-ㅌ/과 양순음 /ㅂ-ㅃ-ㅍ/은 모두 ‘평음-격음’ 쌍의 비율이 가장 높고, ‘경음-격음’ 쌍의 비율이 가장 낮았다.
많은 연구에서 한국어를 배우는 외국인 학습자들은 ‘평음-경음-격음’의 구분이 있는 파열음, 파찰음의 발음 습득에 어려움이 있다고 한다. 모국어의 영향에 따라 차이가 있을 수 있겠지만 /ㄱ, ㄷ, ㅂ, ㅈ/의 ‘평음-경음-격음’ 쌍에 대한 습득 난이도는 같지 않을 것이다. 음소 쌍별로 만들 수 있는 최소대립쌍의 수는 차이를 보이므로 음소 쌍마다 기능부담량이 다를 것이라고 할 수 있다. 최소대립쌍의 개수를 기반으로 기능부담량을 설정하여 발음 교육의 우선순위를 매긴다면 표 9와 같을 것이다.
표 9. | Table 9.
최소대립쌍 개수 기반 기능부담량 | Functional load based on the raw count of minimal pairs
|
|
음소 쌍 |
최소대립쌍 개수 |
| High |
/ㅈ-ㅊ/ |
8,631 |
| ↓ |
/ㅂ-ㅍ/ |
2,934 |
| /ㄷ-ㅌ/ |
2,863 |
| /ㄱ-ㄲ/ |
1,524 |
| /ㅉ-ㅊ/ |
1,475 |
| /ㅂ-ㅃ/ |
1,381 |
| /ㄱ-ㅋ/ |
1,225 |
| /ㅈ-ㅉ/ |
1,171 |
| /ㅅ-ㅆ/ |
993 |
| /ㄷ-ㄸ/ |
919 |
| /ㄸ-ㅌ/ |
747 |
| /ㅃ-ㅍ/ |
459 |
| Low |
/ㄲ-ㅋ/ |
343 |
Download Excel Table
한국어 장애음의 경우 /ㅈ-ㅊ/ 쌍은 최소대립쌍의 수가 가장 많으므로 우선적으로 교육해야 하고, 반대로 /ㄲ-ㅋ/ 쌍은 최소대립쌍의 수가 적으므로 발음을 교육할 때 크게 중요하지 않다고 주장할 수도 있을 것이다.
3.2. 최소대립쌍의 품사 분석
이 절에서는 초성 위치에서 자음이 대립하는 최소대립쌍의 품사에 대해 살펴본다. 표 10은 두 단어의 품사 관계를 나타낸 분포표이다.
표 10. | Table 10.
최소대립쌍 단어의 품사 관계 | Syntactic category of words in the pairs
|
|
명사 |
대명사 |
수사 |
동사 |
형용사 |
관형사 |
부사 |
조사 |
감탄사 |
| 명사 |
236,851
(70.25%) |
|
|
|
|
|
|
|
|
| 대명사 |
2,446
(0.73%) |
46
(0.01%) |
|
|
|
|
|
|
|
| 수사 |
751
(0.22%) |
26
(0.01%) |
12
(0.00%) |
|
|
|
|
|
|
| 동사 |
1,221
(0.36%) |
8
(0.00%) |
1
(0.00%) |
49,778
(14.77%) |
|
|
|
|
|
| 형용사 |
358
(0.11%) |
- |
1
(0.00%) |
17,399
(5.16%) |
4,621
(1.37%) |
|
|
|
|
| 관형사 |
2,760
(0.82%) |
62
(0.02%) |
62
(0.02%) |
2
(0.00%) |
- |
532
(0.16%) |
|
|
|
| 부사 |
11,999
(3.56%) |
162
(0.05%) |
96
(0.03%) |
90
(0.03%) |
30
(0.01%) |
271
(0.08%) |
4,429
(1.31%) |
|
|
| 조사 |
808
(0.24%) |
40
(0.01%) |
25
(0.01%) |
36
(0.01%) |
6
(0.00%) |
58
(0.02%) |
77
(0.02%) |
23
(0.01%) |
|
| 감탄사 |
1,545
(0.46%) |
63
(0.02%) |
31
(0.01%) |
14
(0.00%) |
3
(0.00%) |
88
(0.03%) |
170
(0.05%) |
43
(0.01%) |
91
(0.03%) |
Download Excel Table
초성 최소대립쌍 단어의 품사 관계를 보면 ‘명사-명사’ 쌍이 70.25%로 가장 많고, 그다음으로 ‘동사-동사’ 쌍이 14.77%로 나타나 이 두 품사 쌍이 전체의 85% 이상을 차지했다. 전체 45개의 품사 쌍 중 39개는 1%도 되지 않았는데 그 중 ‘대명사-형용사’와 ‘형용사-관형사’의 품사 관계를 보이는 최소대립쌍은 한 쌍도 없었다. 용언인 동사와 형용사는 용언 내에서 최소대립쌍을 이루는 비율이 높고, 용언을 제외한 다른 모든 품사는 명사 또는 부사와의 쌍이 많은 것이 특징적이다. 즉, 용언은 특정 품사와 최소대립쌍을 이루는 비율이 높은 반면에 부사는 모든 품사와 자유롭게 최소대립쌍을 이룬다고 할 수 있다.
표 11은 음소 쌍별 최소대립쌍 중 품사가 같은 단어 쌍의 개수를 조사하여 두 단어의 품사 일치 정도를 계산한 후, 일치율이 높은 상위 10%와 일치율이 낮은 하위 10%에 해당하는 음소 쌍을 제시한 것이다. 전체 초성 최소대립쌍의 품사 일치율은 부록 2에 제시하였다. 초성 최소대립쌍 337,135개 중 296,356개가 두 단어의 품사가 같았고 그 결과 품사 일치율은 87.91%로 상당히 높은 편이었다. 품사 일치율이 가장 높은 음소 쌍은 /ㄲ-ㅋ/(93.88%)고, 가장 낮은 음소 쌍은 /ㅉ-ㅋ/(68.60%)였다. 품사 일치율이 높은 음소 쌍은 대체로 경음과 격음으로 구성되어 있었는데 최소대립쌍의 품사 일치율은 음소 쌍의 음성적 유사성과 연관이 있다고 볼 수 있겠다.
표 11. | Table 11.
음소 쌍별 최소대립쌍 품사 일치 비율(상하위 10%) | Percentage of same part of speech(top 10% and bottom 10%)
| 순위 |
초성 쌍 |
품사 일치율 |
순위 |
초성 쌍 |
품사 일치율 |
| 1 |
ㄲ-ㅋ |
93.88 |
139 |
ㄷ-ㅋ |
77.35 |
| 2 |
ㄲ-ㅃ |
93.77 |
140 |
ㅆ-ㅋ |
76.70 |
| 3 |
ㄲ-ㅉ |
93.48 |
141 |
ㅁ-ㅃ |
76.57 |
| 4 |
ㅃ-ㅉ |
93.43 |
142 |
ㅃ-ㅋ |
76.40 |
| 5 |
ㅃ-ㅆ |
92.93 |
143 |
ㄸ-ㅎ |
76.13 |
| 6 |
ㄲ-ㅆ |
92.65 |
144 |
ㅈ-ㅋ |
76.06 |
| 7 |
ㄲ-ㅍ |
92.11 |
145 |
ㅋ-ㅎ |
75.92 |
| 8 |
ㅊ-ㅍ |
92.00 |
146 |
ㅃ-ㅅ |
75.81 |
| 9 |
ㄸ-ㅌ |
91.97 |
147 |
ㄱ-ㅃ |
75.46 |
| 10 |
ㅆ-ㅊ |
91.49 |
148 |
ㄷ-ㅉ |
75.25 |
| 11 |
ㅆ-ㅉ |
91.48 |
149 |
ㄷ-ㅃ |
74.80 |
| 12 |
ㅆ-ㅌ |
91.33 |
150 |
ㄴ-ㅃ |
74.77 |
| 13 |
ㅌ-ㅍ |
91.28 |
151 |
ㄹ-ㅃ |
73.68 |
| 14 |
ㄴ-ㅊ |
91.03 |
152 |
ㅃ-ㅈ |
72.14 |
| 15 |
ㄲ-ㅌ |
90.74 |
153 |
ㅉ-ㅋ |
68.60 |
Download Excel Table
4. 결론
이 연구에서는 『우리말샘』의 표제어 발음을 대상으로 초성 위치에서 한국어 자음의 최소대립쌍 출현 빈도를 조사하고, 최소대립쌍을 이루는 두 단어의 품사 관계에 대해서 분석했다. 연구 결과를 요약하면 다음과 같다.
첫째, 분석 대상이 된 325,717개의 표제어에서 관찰된 초성 자음 대립의 최소대립쌍은 총 337,135개였다. 음소 쌍별 최소대립쌍의 개수는 ‘ㅅ-ㅈ, ㄱ-ㅅ, ㄱ-ㅈ, ㄱ-ㅂ, ㄱ-ㅎ, ..., ㅃ-ㅋ, ㄹ-ㅃ, ㅉ-ㅋ, ㄸ-ㅋ, ㅆ-ㅋ’ 순으로 나타났다. 고빈도 음소 쌍은 평음의 비중이 높고, 저빈도 음소 쌍은 경음의 비중이 높았다. 음소별로 최소대립쌍을 많이 이루는 빈도를 분석한 결과 ‘ㄱ, ㅅ, ㅈ, ㅂ, ㅊ, ㅁ, ㅎ, ㄷ, ㄴ, ㅍ, ㅌ, ㄹ, ㅉ, ㅆ, ㄲ, ㄸ, ㅋ, ㅃ’ 순으로 나타났다. 장애음 중에는 경음과 격음보다 평음이, 공명음 중에는 유음보다 비음이 최소대립쌍을 많이 만든다는 것을 확인할 수 있는데, 경구개음의 비율이 높게 나타난 것도 특징적이었다.
최소대립쌍의 절대수치와 상대수치의 상관관계를 살펴본 결과 r=0.937의 높은 상관계수를 나타냈다. 절대수치와 상대수치에 대한 잔차를 구한 결과 잔차의 값이 큰 음소 쌍은 /ㅆ-ㅉ/, /ㅊ-ㅌ/, /ㅌ-ㅍ/, /ㄴ-ㅌ/, /ㅁ-ㅍ/였는데 이 쌍들은 음소 빈도에 비해 최소대립쌍의 개수가 상대적으로 많다고 할 수 있다. 반대로 잔차의 값이 작은 음소 쌍은 /ㄷ-ㅈ/, /ㄱ-ㅎ/, /ㄱ-ㄷ/, /ㄱ-ㅅ/, /ㄱ-ㅈ/였다.
한편, 삼지적 상관속을 이루는 장애음의 최소대립쌍 관계에도 차이가 나타났다. 경구개 파열음은 ‘평음(ㄱ)-경음(ㄲ)’ 쌍의 비율이 가장 높고, ‘경음(ㄲ)-격음(ㅋ)’ 쌍의 비율이 가장 낮았다. 반면에 파찰음은 ‘평음(ㅈ)-격음(ㅊ)’ 쌍의 비율이 가장 높고, ‘평음(ㅈ)-경음(ㅉ)’ 쌍의 비율이 가장 낮았다. 한편, 치경 파열음과 양순 파열음은 모두 ‘평음(ㄷ/ㅂ)-격음(ㅌ/ㅍ)’ 쌍의 비율이 가장 높고, ‘경음(ㄸ/ㅃ)-격음(ㅌ/ㅍ)’ 쌍의 비율이 가장 낮았다.
둘째, 최소대립쌍을 이루는 두 단어 쌍의 품사 정보 분포를 살펴본 결과 두 단어의 품사가 같은 비율은 87.91%로 나타나 최소대립쌍은 인지적으로 비슷한 범주로 묶일 가능성이 높다는 것을 확인할 수 있었다. 품사 일치율이 가장 높은 음소 쌍은 /ㄲ-ㅋ/, 가장 낮은 음소 쌍은 /ㅉ-ㅋ/ 쌍이었다. 이 결과는 이후 발음 교육을 위한 한국어 음소의 기능부담량 설정에도 활용할 수 있을 것이다.
이 연구는 사전 표제어의 발음형을 대상으로 기존 연구에서 다루지 못한 최소대립쌍의 양상을 밝혔다는 의의가 있다. 다만 모음과 종성 위치의 자음의 최소대립쌍을 다루지 못했고, 단어 구조를 반영한 어두, 어중, 어말 위치에서의 대립 관계도 다루지 못했다. 추후 이에 대해서도 연구를 진행하여 한국어 음소의 전체적인 대립 체계를 종합적으로 정리해 나가고자 한다. 이 연구의 결과는 한국어 음소와 관련된 기초 자료로서 발음 교육, 언어 병리학, 음성 공학 등의 다양한 응용 분야에서 유용하게 활용될 수 있을 것이다.