





1. 서론
최근 서울말의 /ㅗ/와 /ㅜ/가 F1/F2 공간에서 포먼트만으로 구별이 어려울 만큼 근접해 있다는 연구가 다수 보고되었다. 이에 대해 처음으로 언급한 것은 Lee(1998)로 보이는데, Lee는 1970년대 전반 출생(추정)의 남녀 각 6명의 모음 공간에서 ㅗ/ㅜ의 거리가 이미 융합(merger)된 ㅔ/ㅐ 정도는 아니어도 상당히 근접해 있는 것을 확인하고 서울말이 6 모음체계로 변화하고 있다고 지적하였다. 비슷한 시기에 발표된 Jung(1997)은 ㅗ/ㅜ가 안정적이라고 기술하고 있으나 논문에 제시된 1940년대와 1970년대 출생으로 추정되는 당시의 50대(여성 추정)와 20대의 ㅗ/ㅜ는 중복될 정도로 근접한 상태이다.
ㅗ/ㅜ의 근접은 화자의 연령, 성별과 관계가 있는 것이 알려져 있다. 연령에 대해서 F1/F2 공간을 제시하고 있는 문헌을 정리하면 다음과 같다. 대략 1970년대 출생을 경계로 그 이전 출생자는 ㅗ/ㅜ의 거리가 다른 모음과 마찬가지로 충분히 떨어져 있고 ㅗ/ㅜ는 기본적으로 F1(제1포먼트)로 구별된다(Obata & Toyoshima, 1932; Kang, 1989; Han & Kim, 2014). 1970년대 출생 자는 문헌에 따라 상기와 같은 이전의 상태(ㅗ/ㅜ가 충분히 떨어져 있는 상태)를 보여주는 경우(Yang, 1996)와 ㅗ/ㅜ가 근접한 상태를 보여주는 경우가 있다(Jung, 1997; Lee, 1998; Seoug, 2004). 보다 아랫세대인 1980년 이후 출생자는 ㅗ/ㅜ가 근접한 상태만을 보여준다(Cho, 2003; Ahn, 2004; Moon, 2007; Kim et al., 2008; Oh, 2012).
성별에 관해서는 남성의 발화보다 여성의 발화에서 근접한 상태가 많이 관찰된다. 여성의 경우 근접한 상태가 나타나는 생년은 상기의 1970년대보다 이른 경향이 있어 위에서 언급한 Jung(1997)의 여성 화자는 1960년대 이전 출생자인데도 ㅗ/ㅜ가 매우 가깝다. 출생 연대가 1960년대 이전이어도 데이터의 수집 시기가 최근일수록 ㅗ/ㅜ의 근접 연령이 높아져서(Kang et al., 2010; Kim et al., 2013; Kim & Yoon, 2015; Byun, 2018; cf. Hong 1991)1, Kang et al.(2010)의 화자는 남녀 모두 1940년대 출생자임에도 불구하고 ㅗ/ㅜ가 1980년대 출생자만큼이나 가깝다. 데이터의 수집 시기에 따른 ㅗ/ㅜ의 포먼트 변화에 대해 Byun (2018)은 언어형성기 이후에도 언어공동체와 같은 방향으로 개인의 발음이 조금씩 변화하는 전생애 변화의 가능성을 제기하였다.
선행연구에서 확인된 ㅗ/ㅜ의 근접은 다음의 세 가지로 분류할 수 있다2. 근접 이전의 상태를 포함하여 모음 공간의 모식도를 그림 1에 제시하였다. [0]은 ㅗ/ㅜ의 포먼트가 변화하기 이전의 상태로 전설모음 ㅐ/ㅔ는 융합이 완료된 상태이다. 1970년대 이전 출생자의 발화에서 전형적으로 보인다. [1]~[3]은 ㅗ/ㅜ에 포먼트 변화가 일어난 후의 모음 공간이다. [1]은 /ㅗ/의 개구도가 작아지고(모음 공간에서 F1이 상승하고) /ㅜ/가 약간 앞으로 전진한 상태로 ㅗ/ㅜ는 F1과 F2로 구별된다(Cho, 2003; Ahn, 2004; Seong, 2004; Cha, 2007; Moon, 2007; Oh, 2012; Yoon & Kang, 2014). [2]는 [1]보다 /ㅗ/의 개구도가 더 작아졌으나 /ㅜ/의 이동이 없어 ㅗ/ㅜ가 중복될 만큼 근접한 경우이다(Jung, 1997; Lee, 1998; Seong, 2004; Kang & Han, 2013; Jang et al., 2015). [3]은 /ㅗ/가 더 상승하고 /ㅜ/가 앞으로 더 전진하여 ㅗ/ㅜ가 F2로 구별되고 있는 상태이다(Cho, 2003; Moon, 2007; Kim et al., 2008; Han et al., 2013; Kang & Kong, 2016; Lee et al., 2017). 직관적으로 [2]와 [3]은 [1]에서 변화가 더 진행된 상태임을 알 수 있다.

그림 1을 발화 스타일과 관련해서 보면 다음과 같다. [1]은 /ㅗ/의 상승으로 인해 거리가 가까워진 /ㅜ/가 충돌을 피하기 위해 앞으로 전진한 것으로 추측되며 주로 유의미어의 단어 리스트나 낭독체에서 많이 나타난다. [2]는 개별 발화에서는 ㅗ/ㅜ가 거의 중복되어 포먼트만으로는 구별이 어렵고 전설모음 ㅐ/ㅔ와 비교하면 융합 직전의 상태로 볼 수 있다. 주로 단독발화에서 관찰된다. 같은 문헌에 [1], [2]가 있을 경우 [1]은 남성, [2]는 여성의 발화에서 많이 나타난다. [3]은 ㅗ가 크게 상승하였으나 동시에 ㅜ가 앞으로 크게 전진하였기 때문에 ㅗ/ㅜ 사이에 충돌은 일어나지 않는다. 자연발화에서 많이 관찰된다. 보통 단독발화는 자연발화보다 더 정확히 발음되는 경향이 있어 단독발화에서 모음 간의 거리가 더 크게 나타날 것으로 예상되나 그림 1은 완전히 반대로 단독발화에서 많이 나타나는 [2]가 자연발화에서 많이 나타나는 [3]보다 ㅗ/ㅜ의 거리가 훨씬 가깝다.
윗세대에서 [0], [1], 아랫세대에서 [2], [3]이 관찰되는 것으로 보아 현재 서울말의 단모음은 선행 연구들이 지적하고 있는 것처럼 ㅗ/ㅜ로 인한 체계 변화가 일어나고 있는 것으로 추정된다. 그렇다면 변화의 방향은 [2] 또는 [3]으로 볼 수 있는데 만일 [2]가 되어 ㅗ/ㅜ의 근접이 더욱 진행된다면 ㅐ/ㅔ와 같은 융합이 ㅗ/ㅜ에도 일어나 새로운 6모음 체계가 될 것이고, [3]이 된다면 현재의 7모음 체계가 위치를 바꾸어 지속될 것이다. 다만 [2]는 안정된 체계를 유지할 수 있어 보이나 [3]은 고모음이 너무 많아 최적의 체계로 보기에는 부적합하며3 [3]이 된다고 해도 이후 안정된 체계를 유지하기 위해 또 다른 모음 변화가 일어날 것으로 예상된다.
ㅗ/ㅜ의 근접은 [0]에서 보듯이 전설모음 ㅐ/ㅔ의 융합으로 인해 일어난 체계의 불안정을 해소하기 위하여 일어난 것으로 추정된다. ㅗ/ㅜ의 근접이 ㅐ/ㅔ의 융합 이후에 본격화된 것이 그 증거이다4. 따라서 서울말의 모음 체계는 안정된 체계인 [2]를 향하고 있다고 보는 것이 타당할 것이다. 다만 이를 위해서는 ㅗ/ㅜ에 ㅐ/ㅔ와 같은 융합이 일어날 거라는 전제가 필요하나 현재 ㅗ/ㅜ의 구별에 ㅐ/ㅔ와 같은 혼란은 보이지 않는다. 필자는 ㅗ/ㅜ의 근접이 모음 체계의 안정성을 위해 일어난 변화이지만 최종적으로 [2]와 같은 모음 체계가 된다 해도 ㅗ/ㅜ에 ㅐ/ㅔ와 같은 융합은 일어나지 않을 것으로 예상한다. ㅐ/ㅔ와 같은 융합이란 생성, 지각 모두에서 변별 기능을 잃는 것을 말한다. 이유는 생성과 지각 모두에서 ㅗ/ㅜ가 구별되고 있기 때문이다. 구체적으로 보자.
낭독음성이나 자연발화의 코퍼스 음성을 분석하는 연구 방법은 최근의 연구 경향이다. 그러나 20세기 초의 출생자(1909년 출생, 여성)의 낭독음성을 분석한 Cha(2007)에서도 ㅗ/ㅜ가 [1]의 경향을 보이는 것을 고려하면 ㅗ/ㅜ가 [1], [3]과 같이 나타나는 것은 발화 스타일에 따른 차이일 뿐 체계의 안정을 전제로 한 모음 변화가 아닐 수 있다(cf. Lee, 2017)5. 같은 시기의 출생자인 Han & Kim(2014)의 화자(1894년생 남성), Obata & Toyoshima(1932)의 화자(1910년 전후 출생, 남녀)의 단독발화는 모음 공간에서 ㅗ/ㅜ가 충분히 거리를 유지하며 주로 F1만으로 구별되기 때문이다. 모음 음소 간에 차이가 있을 때는 어떤 형태로든 모음 간의 충돌을 피하려 하나 음소 간의 변별 기능을 상실한 ㅐ/ㅔ는 발화 스타일과 상관없이 모음 공간에서 중복하여 나타나므로 모음의 구별은 불가능하다. 안정된 발화인 단독발화에서 구별이 모호해도 ㅗ/ㅜ가 낭독발화나 자연발화에서 구별이 가능한 것은 ㅗ/ㅜ의 변별 기능이 유지되고 있다는 것을 시사한다.
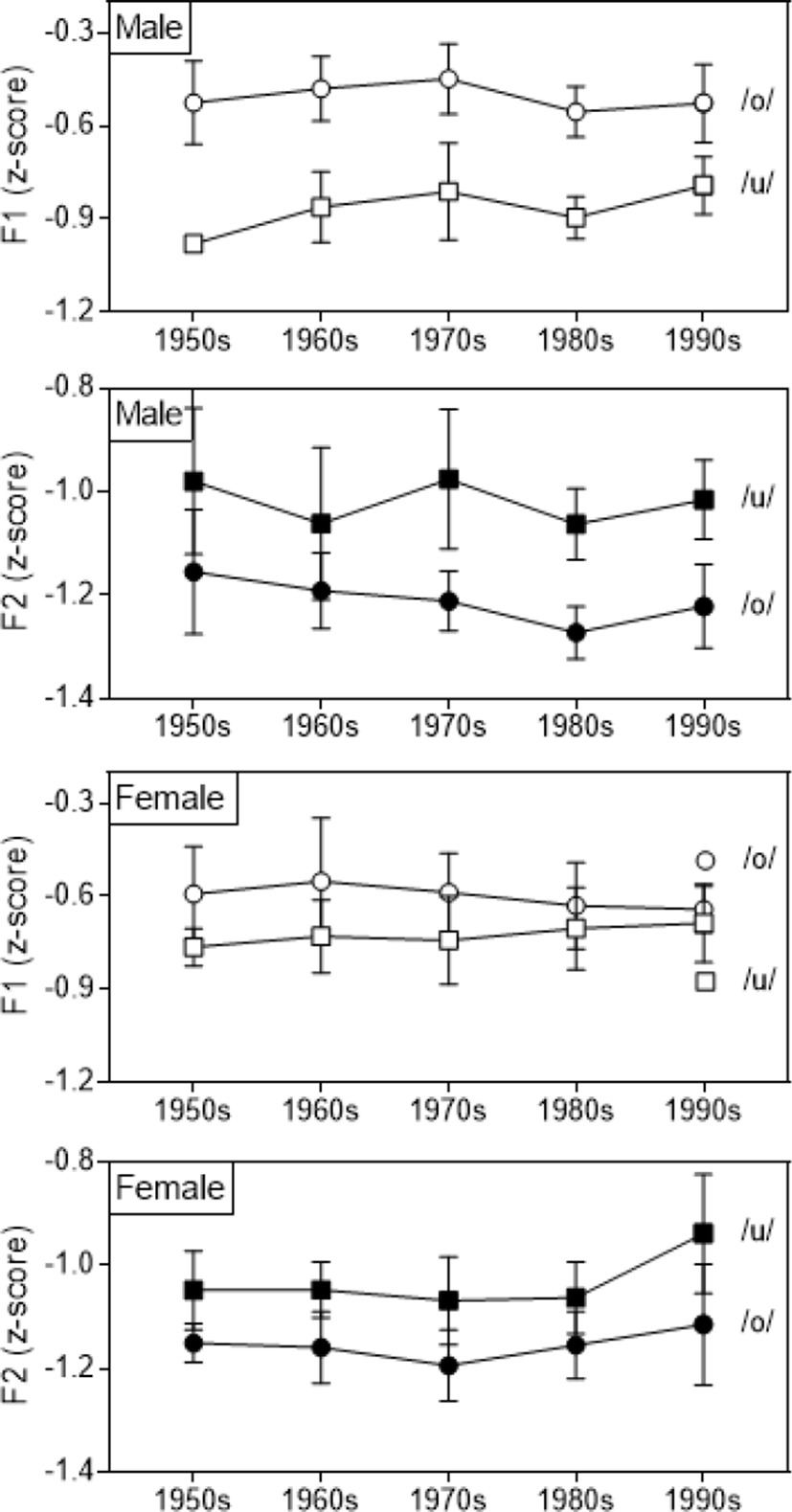
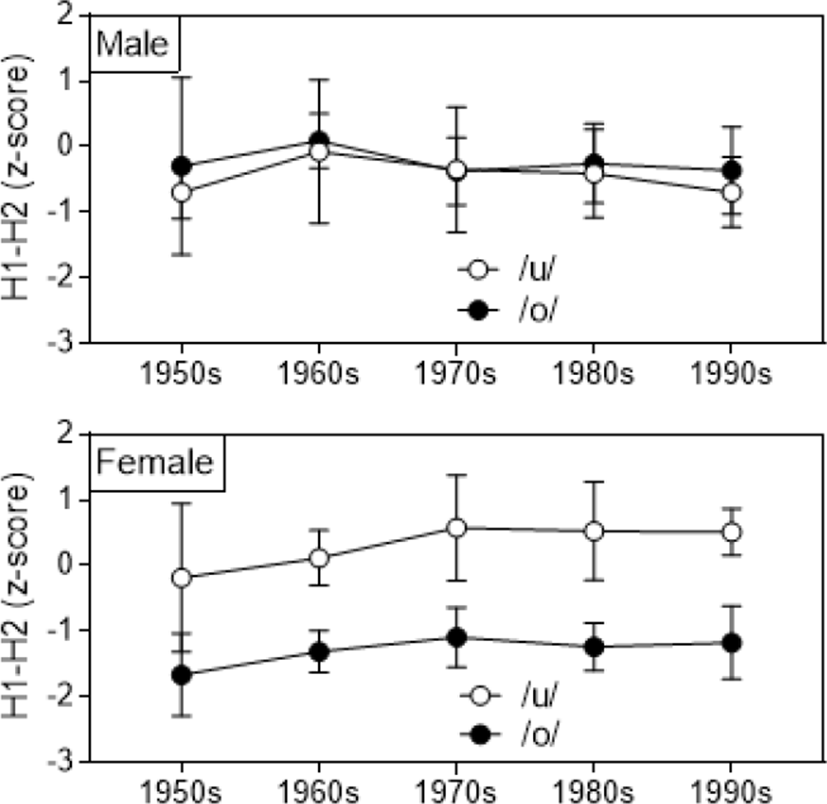
그렇다면 [2]의 상태에서 ㅗ/ㅜ는 어떻게 구별될까. Byun (2018)에 의하면 그림 2에서 보는 것처럼 남성의 발화는 포먼트만으로 구별되나(상단 2개), 여성의 발화는 포먼트만으로는 불충분하고(하단 2개) 그림 3에서 보는 것처럼 모음의 음질 차이로 ㅗ/ㅜ가 구별된다. 남성은 ㅗ/ㅜ 사이에 H1-H2의 차이가 없어 음질 차이가 ㅗ/ㅜ의 구별에 사용되지 않는 것을 알 수 있다. 모음의 구별에 사용되는 음향특성이 변화하는 예는 다른 언어에서도 관찰된다. 모음의 구별(tense vs. lax)에 포먼트 대신 모음의 음질이 관여하는 예는 영어의 방언에서 확인할 수 있고(Di Paolo & Faber, 1990), 음향특성이 모음의 음질 차이에서 포먼트 차이로 바뀌는 예는 중국어의 방언에서 찾아볼 수 있다(Kuang & Cui, 2018).
지각에 대해서는 [1], [3]은 차치하더라도 [2]처럼 거의 중복에 가까운 경우에도 지금까지 ㅗ/ㅜ에 ㅐ/ㅔ와 같은 혼동이 있다는 보고는 없다6. Hong(1991)은 ㅗ/ㅜ가 모음 공간에서 ㅐ/ㅔ와 마찬가지로 거의 구별이 없는 것을 발견하고 유의미어의 단어쌍을 이용하여 청취실험을 실시하였다. 결과는 ㅐ/ㅔ는 구별이 안 되나 ㅗ/ㅜ는 구별에 전혀 문제가 없어 모음 공간상의 ㅗ/ㅜ의 근접을 거짓 융합(false merger)으로 결론지었다. 자연음을 사용한 Igeta et al.(2014)은 ㅗ/ㅜ의 동정률은 거의 100%이나 적합성(goodness)에서는 두 모음 모두 91% 정도로 낮아진다고 보고하였다. 마찬가지로 자연음을 사용한 Chung et al.(1988)의 동정률은 /ㅗ/가 99%, /ㅜ/가 95%였다. 한편, 합성음을 이용한 Choi(2001, 2003), Choi et al.(1997)는 /ㅡ/이외의 단모음은 생성과 지각 모두 F1, F2만으로 충분히 설명이 가능하며7 지각공간이 생성공간보다 크게 나타나고 지각에 남녀 차이가 없는 것을 보고하였다. 또한 중심에서 벋어날수록 지각의 일치도가 낮아져 모음 지각이 범주적(categorical)이 아닌 등위적(graded)임을 확인하였다.
ㅗ/ㅜ의 지각에 F1, F2의 어느 것이 더 중요한 역할을 하는가에 대해서는 선행연구 사이에서도 차이가 있다. 합성음을 이용한 지각실험에서 Igeta & Arai(2019)는 F1의 영향이 크다는 결과를 얻었으나 Yoon et al.(2015)은 F2의 영향이 크다는 결과를 얻었다.
본고에서는 ㅗ/ㅜ가 모음 공간상에서 포먼트 차이가 거의 없는데도 불구하고 지각에 혼란이 없는 것과 관련하여 생성에서 확인된 모음의 음질(H1-H2) 차이가 지각에도 관여하고 있는지를 검토하였다. 만일 지각에서도 H1-H2가 사용되고 있다면 여성의 ㅗ/ㅜ를 생성과 지각 모두에서 H1-H2로 정연하게 설명할 수 있을 것이다. 결과를 먼저 말하면 ㅗ/ㅜ의 지각은 기본적으로 남녀 모두 포먼트에 의존하고 있으며 H1-H2는 포먼트로 구별이 어려운 경우에만 극히 제한적으로 사용되는 것을 확인하였다.
본고의 구성은 먼저 2.에서 지각실험의 자극음, 청자 등에 대해 설명하고 3.에서 실험 결과를 제시한다. 4.에서 ㅗ/ㅜ가 ㅐ/ㅔ와는 다른 형태로 융합할 가능성에 대해 논의하고 5.에서 마무리한다.
2. ㅗ/ㅜ의 지각실험
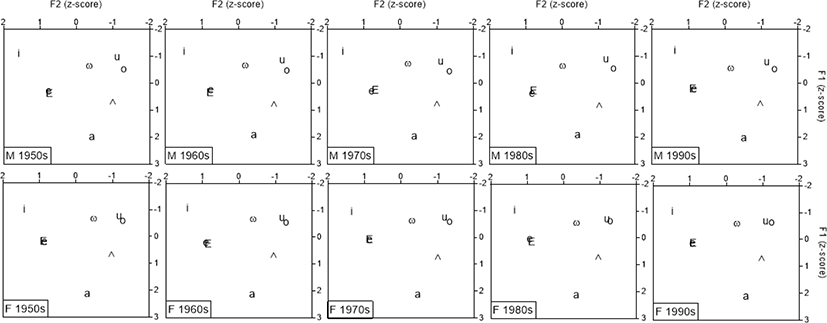
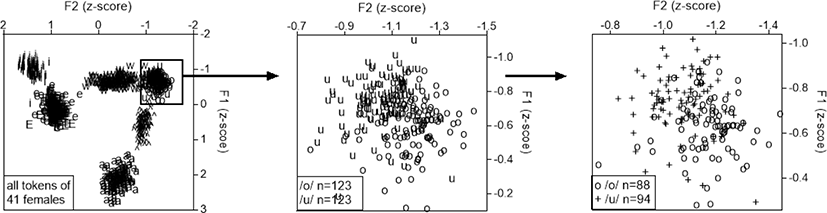
자극음은 Byun(2018)의 발화 음성을 이용하였다. 그림 4에서 보는 것처럼 남성의 발화는 ㅗ/ㅜ의 거리가 가까워도 분리되어 있으나 여성의 발화는 나이와 상관없이 ㅗ/ㅜ가 서로 중복될 정도로 근접해 있다. 그림 5(왼쪽)는 그림 4의 여성 화자 41명이 발화한 모음을 모두 표시한 것이다(41명×8모음×3회). 그림 5(왼쪽)에서 보듯이 ㅗ/ㅜ(사각형 부분)는 모음 사이가 가까워 다른 모음과 비교하면 하나의 모음처럼 보인다. 이미 융합한 ㅐ/ㅔ와 비교해도 큰 차이가 없다. 지각실험에 쓰인 자극음은 ㅗ/ㅜ의 전 246예(그림 5 중앙) 중에서 중복된 예를 일부 제외한 182예(그림 5 오른쪽)이다. 182예는 주변으로 갈수록 F1, F2만으로 구별이 가능한 경우도 있으나 중앙 부분에는 F1, F2만으로는 구별이 어려운 예가 많다. 그림 5(오른쪽)에서 F1, F2로 ㅗ/ㅜ의 구별이 가능하다고 해도 그림 5(왼쪽)의 다른 모음과의 거리를 비교하면 거의 중복된 상태이므로 청각적으로도 구별이 가능한지, 청각적으로 구별이 가능할 때 어떤 음향특성으로 지각이 행해지는지를 확인하고자 한다.
청자는 자극음의 화자와는 다른 집단인 대학생 35명(남자 10명, 여자 25명, 1993~2001년생)으로 태어나서 고등학교까지를 서울, 경기 지역에서 생활한 서울말 모어 화자(=청자)이다.
참가자는 실험 전에 내용 설명을 들었으며 실험 결과가 연구 목적으로 사용되며 공개되는 것에 서면 동의하였다. 실험에 앞서 참가자의 청력에 문제가 없는 것을 설문지를 통해 확인하였다.
지각실험은 2019년 4~5월에 대학교의 연구실에서 노이즈 캔슬 기능이 있는 헤드폰(SONY WH-1000XM3)을 이용하여 Praat상에서 실시하였다. 참가자는 헤드폰에서 나오는 소리를 듣고 컴퓨터 화면에 표시된 /으, 오, 우, 어/ 중에서 가장 가깝다고 생각하는 단어를 클릭하여 선택한다. 자극음은 최대 2번까지 다시 들을 수 있고 잘못 회답하였을 경우에는 다시 회답할 수 있도록 설정하였다.
본실험에 앞서 8문제로 된 연습문제를 실시하여 실험 방법에 익숙해지도록 하였다. 본실험은 총 200문제(자극음 182+더미18)로 40문제마다 실험 화면에 휴식을 취하도록 안내문을 넣었다. 다만 휴식을 강요하지는 않았다. 회답에 걸리는 시간도 특별히 정하지 않고 참가자의 재량에 맡겼다.
본고에서는 먼저 정답률(/ㅗ/를 /ㅗ/, /ㅜ/를 /ㅜ/로 바르게 지각한 동정률)에 따른 자극음의 음향특성에 주목하였다. 구체적으로는 전체 자극음의 음향특성, 정답률이 100%인 자극음의 음향특성, 정답률이 낮은 자극음의 음향특성, 모음 공간에서 F1, F2로 거의 구별이 불가능한 자극음의 음향특성에 대해서 살펴보았다(3.2). 분석할 음향변수는 F1, F2, H1-H2, F0의 4가지이다. 각 변수는 개인별로 z변환한 값을 사용하였다. F0는 Byun(2018)에서 ㅗ/ㅜ간의 차이가 다른 변수보다 상대적으로 작았지만 통계적으로 유의하였기 때문에 확인을 위해 포함하였다. 결과의 그래프 작성에 필요한 측정치는 Byun(2018)에서 빌려왔다. 이어서 위의 4가지 변수가 ㅗ/ㅜ 의 지각특성으로 쓰이는지, 각각의 변수의 상대적 영향력이 어느 정도인지를 살펴보았다(3.3).
4가지 변수가 생성과 지각에서 ㅗ/ㅜ의 구별에 어느 정도 영향을 미치는가를 보기 위해 4가지 음향변수를 독립 변인, ㅗ/ㅜ 또는 정답/오답을 종속 변인으로 하는 이항 로지스틱 회귀분석을 실시하였다. 통계분석에는 RStudio(ver. 1.3.959, RStudio Team 2020)의 lme4 패키지(ver. 1.1-21), glmer, glm함수를 사용하였다.
3. 결과
참가자 35명의 평균 정답률은 89%, 모음별로는 /ㅗ/(n=88)가 86%, /ㅜ/(n=94)가 91%였다. 본고의 결과는 자연음을 사용한 선행연구의 결과(91%~100%)보다 약간 낮다. 자극음을 해당 모음 ㅗ/ㅜ가 아닌 다른 모음으로 판정한 오답률을 보면 /ㅗ/는 /ㅜ/가 13%, /ㅡ/가 1%로 /ㅜ/가 많았고, /ㅜ/는 /ㅗ/가 3%, /ㅡ/가 6%로 /ㅡ/가 많았다(정답률+오답률=100%). 참고로 더미인 /ㅓ/(n=9)와 /ㅡ/(n=9)의 정답률은 각각 96%, 94%였다.
여기서는 지각의 정답률별로 자극음의 4가지 음향변수가 어느 정도 ㅗ/ㅜ의 구별에 관여하고 있는지를 살펴본다. 밀도분포를 그림 6~9에 제시하였다. 그림 6은 자극음 전체(n=182), 그림 7은 전체 자극음 중에서 정답률이 100%인 자극음(n=60), 그림 8은 정답률이 80% 미만(0%~77%)인 자극음(n=25, 평균 정답률 45%), 그림 9는 전체 자극음 중에서 정답률이 97% 이상이고 모음 공간에서 F1/F2가 중복되어 있는 자극음(n=48, 평균 정답률 99%)이다. 그림 6~9의 각 변수는 같은 변수끼리는 직접 비교할 수 있으나 다른 변수끼리는 x축의 눈금이 달라 직접 비교하는 것은 적절하지 않다. 예를 들어 그림 6의 F2는 그림 7~9의 F2와 직접 비교할 수 있지만 그림 6의 F2와 H1-H2는 후자의 x축의 눈금이 커서 실제로는 F2보다 H1-H2의 ㅗ/ㅜ간의 차이가 월등히 크다. 확인을 위해 그림 7~9에 대응하는 모음 공간을 그림 10에 제시하였다. 그림 6의 모음 공간은 그림 5(오른쪽)에서 확인할 수 있다.
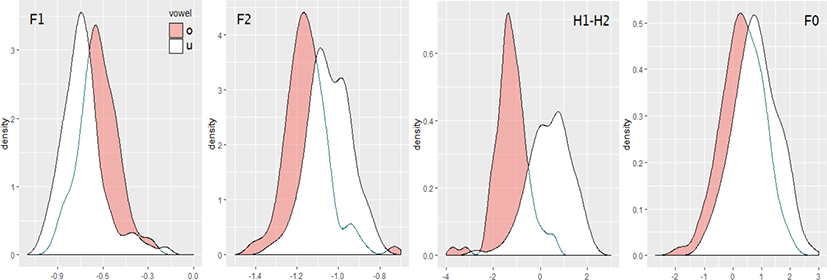
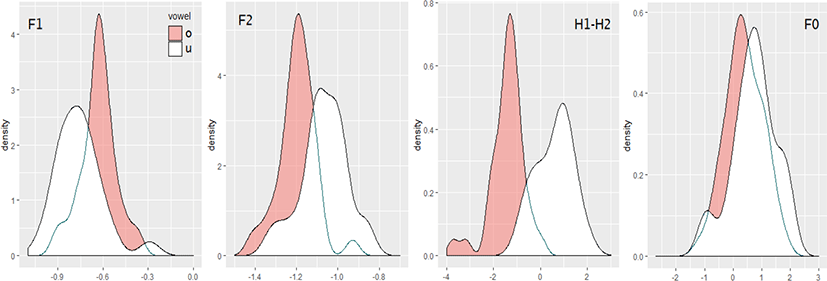
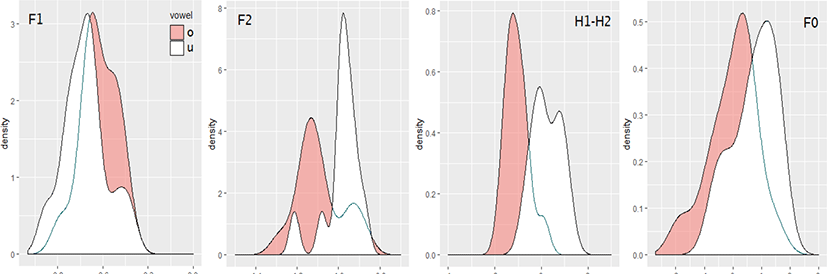
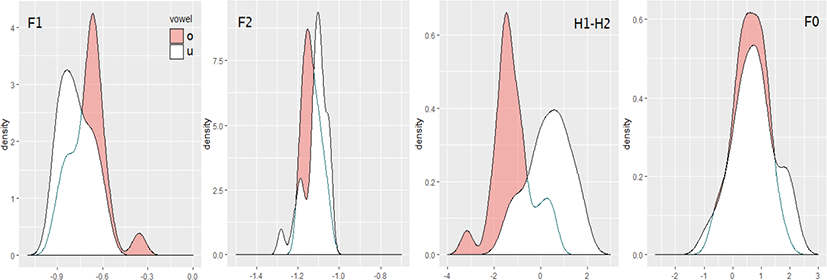
그림 6부터 보자. 어느 음향변수나 정도의 차이는 있으나 ㅗ/ㅜ가 상당히 중복되어 있다. 4가지 음향변수 중 어느 것이 ㅗ/ㅜ의 구별에 영향력이 큰가를 보기 위해 자극음 전체(n=182)에 대해 혼합효과 로지스틱 회귀분석을 실시하였다. 종속 변인은 ㅗ/ㅜ, 독립 변인은 4가지 음향변수이고 임의 효과(random effect)는 개별 화자이다. 회귀모델은 ㅗ/ㅜ만이 아니고 모음 전체를 설명할 수 있어야 한다. 그림 4에서 보는 것처럼 단모음 구별에 포먼트의 역할은 자명하므로 모델에 F1과 F2를 투입하는 것은 기본이다. 그러나 ㅗ/ㅜ는 포먼트만으로 설명이 안 되기 때문에 포먼트 이외의 음향변수를 찾는 것이므로 가능성이 제기된 H1-H2와 F0를 투입하여 최적의 모델을 선택한다. 모델의 평가에는 AIC(Akaike Information Criterion)와 BIC(Bayesian Information Criterion)를 이용하였다. AIC, BIC 모두 수치가 작을수록 적합한 모델로 평가된다. 모델의 선택에는 회귀모델의 예측 정확도를 나타내는 정판별률의 결과도 이용하였다.
표 1에 분석 결과를 제시하였다. 모델 (1)은 F1, F2만 투입, 모델 (2)는 F1, F2, F0을 투입, 모델 (3)은 F1, F2, H1-H2을 투입, 모델 (4)는 F1, F2, H1-H2, F0를 모두 투입한 것이다. 추정치의 절댓값이 클수록 ㅗ/ㅜ 구별에 대한 영향력이 커진다. (1)~(4)의 어느 모델도 F2가 F1보다 절댓값이 크므로 F2의 영향력이 더 큰 것을 알 수 있다. H1-H2와 F0는 포먼트에 비하면 상대적인 영향력은 작지만 두 변수 모두 통계적으로 유의하다. 다만 모델 (3)의 F2와 모델 (4)의 네 변수는 유의수준 10%에서 유의하다. 표 2의 AIC와 BIC를 보면 H1-H2가 투입된 모델의 평가가 좋고 정판별률도 F0와 차이가 크다. (3)과 (4) 중에서 어느 것을 최적 모델로 하느냐는 정판별률이 높고 5%에서 유의한 변수가 많으며 가장 결정적으로 변수의 수가 적은 (3)을 최적의 모델로 결정한다. 여기에서 하나 주의해야 할 것은 이 모델은 자극음(생성)을 분석한 것이므로 모델 (3)의 정판별률이 99%라는 것은 발화된 어떤 모음을 F1, F2, H1-H2의 3개의 변수로 설명하였을 때 /ㅗ/ 또는 /ㅜ/로 판별될 확률이 99%라는 뜻으로 ㅗ/ㅜ의 지각을 F1, F2, H1-H2로 99% 설명할 수 있다는 뜻이 아니다. 지각의 결과는 이미 확인한 것처럼 89%였다. 지각의 정답률에 대한 변수효과는 3.3에서 설명한다.
| AIC | BIC | 정판별률(%) | |
|---|---|---|---|
| (1) F1, F2 | 191.2 | 203.9 | 77 |
| (2) F1, F2, F0 | 170.6 | 186.5 | 80 |
| (3) F1, F2, H1-H2 | 108.0 | 123.9 | 99 |
| (4) F1, F2, H1-H2, F0 | 105.4 | 124.4 | 96 |
다음으로 그림 7을 살펴보자. 지각 정답률이 100%인 예이다. 그림 6과 비교하면 F1, F2의 피크가 분리되어 있고 H1-H2도 겹침의 정도가 덜 하다. 그림 10(왼쪽)의 모음 공간을 보면 포먼트만으로 상당수가 구별되며 포먼트만으로 구별이 어려운 것은 H1-H2로 구별이 가능하다. 그림 10(왼쪽)에서 /ㅗ/의 공간에 있는 +표시의 /ㅜ/, 반대로 /ㅜ/의 공간에 있는 ○표시의 /ㅗ/는 포먼트로는 해당 모음으로 판정하기 어렵지만 H1-H2값이 각각의 모음에 해당하여 청자가 바르게 판정한 것으로 보인다. H1-H2에 더하여 F0로도 구별되는 것도 있다. 이에 대한 통계분석은 계산 결과를 얻기는 하였으나 수치가 적당하지 않아 표 3에서 제외하였다. 최대우도 추정법을 이용하는 로지스틱 회귀분석은 완전하게 분리 또는 거의 완전하게 분리된 데이터에서는 바르게 계산되지 않는 경우가 있는데(Albert & Anderson, 1984; King & Ryan, 2002), /ㅗ/와 /ㅜ/가 완전히 분리(구별)되어 있는 것이 원인인 듯하다.
| 추정치 | 표준오차 | z값 | p값 | ||
|---|---|---|---|---|---|
| 그림 7 | - | ||||
| 그림 8 | 절편 | 15.422 | 10.389 | 1.484 | 0.1377 |
| F1 | –12.290 | 9.754 | –1.260 | 0.2076 | |
| F2 | 20.213 | 12.269 | 1.647 | 0.0995† | |
| H1-H2 | 6.287 | 3.327 | 1.890 | 0.0588† | |
| 그림 9 | 절편 | 7.183 | 10.298 | 0.698 | 0.4854 |
| F1 | –6.054 | 3.811 | –1.588 | 0.1121 | |
| F2 | 9.442 | 8.504 | 1.110 | 0.2668 | |
| H1-H2 | 1.991 | 0.544 | 3.656 | 0.0002*** | |
그림 8은 지각의 정답률이 80% 미만인 자극음(n=25)의 음향특성이다(25예의 평균 정답률은 45%). F1은 상당 부분이 중복되어 있다. F2는 ㅗ/ㅜ가 어느 정도 분리되어 있어 그림 10(중앙)에서 보면 일부는 구별이 가능해 보인다. 표 3에서도 F2가 가장 영향력이 있는 변수로 나왔다. 다만 구별 가능성이 있는 F2, H1-H2 모두 유의수준 10%에서만 유의하여 유효한 음향변수가 충분히 기능하지 못해 지각의 정답률이 낮게 나타난 것으로 보인다. 그림 8, 9의 통계분석은 자극음이 반복발화가 아니므로 임의 효과를 제외한 로지스틱 회귀분석을 실시하였다. 그림 8, 9 모두 F0가 유의하지 않았기 때문에 표 3에는 F0를 제외한 F1, F2, H1-H2를 투입한 분석 결과를 제시하였다.
그림 9는 정답률이 97% 이상이고 모음 공간에서 완전히 중복된 자극음(n=48)의 음향특성이다(48예의 평균 정답률은 99%). 그림 10(오른쪽)의 모음 공간에서 보면 F1, F2로는 구별이 어려워 보이는데도 정답률이 높은 것은 표 3에서 보는 것처럼 포먼트보다 상대적인 영향력은 작아도 H1-H2가 유의하게 작용했기 때문인 것으로 추정된다. F1, F2로 구별이 어려운 경우에도 H1-H2 차이로 ㅗ/ㅜ의 구별이 가능하다는 것을 보여주는 예이다.
자극음 전체(n=182)에 대해 어느 음향변수가 바르게 지각(/ㅗ/를 /ㅗ/, /ㅜ/를 /ㅜ/로 지각)되고 틀리게 지각(/ㅗ/를 /ㅗ/이외, /ㅜ/를 /ㅜ/이외로 지각)되는 것에 관여하는지 정답/오답을 종속 변인, 4가지 음향변수를 독립 변인, 청자와 자극음을 임의 변수로 하는 로지스틱 회귀분석을 실시하였다. 모음별로 나눈 결과를 표 4에 제시하였다. 생성(그림 3)에서 H1-H2의 사용에 남녀 차이가 있었으므로 지각에서도 남녀 차이가 있는지를 확인하기 위해 전체 결과와 함께 남녀를 나눈 결과를 함께 제시하였다.
표 4의 전체 결과를 보면 ㅗ/ㅜ 모두 F2의 영향력이 가장 크고 유의하다. 다시 말해 ㅗ/ㅜ의 지각은 거의 F2로 행해지고 있다고 할 수 있다. 합성음을 이용한 선행연구에서 ㅗ/ㅜ의 지각에 영향력이 큰 것은 F1인 경우와 F2인 경우가 있었으나 자연음을 이용한 본고에서는 ㅗ/ㅜ의 지각에 F2가 결정적인 역할을 하는 것으로 나타났다. 다만 본고에서 사용한 자극음은 F2의 영향력이 크나 자연음인 경우 다른 자극음에서는 ㅗ/ㅜ의 분포에 따라 F1의 영향력이 크게 나올 수도 있다. 여성의 발화에서 유의하게 작용하였던(표 3의 그림 9 결과) H1-H2는 지각에서는 이렇다 할 역할을 하지 않는 것으로 나타났다. /ㅗ/는 H1-H2가 10% 유의수준에서는 유의하나 이것은 남성의 결과에서 온 것이다. 결과를 남녀별로 좀 더 자세히 살펴보자.
표 4에서 보듯이 여성의 지각은 기본적으로 ㅗ/ㅜ 모두 F2에 의해 행해진다고 볼 수 있다. 남성도 다른 변수와 비교하면 F2가 가장 영향력이 있는 지각특성이라고 할 수 있다. 다만 추정치의 절댓값이 여성보다 작아 F2에의 의존은 여성보다 상대적으로 작다. 본 데이터의 경우 추정치의 부호는 플러스일 때 정답의 확률, 마이너스일 때 오답의 확률이 커지는 것을 의미한다. /ㅗ/의 경우 F2의 추정치가 남녀 모두 마이너스이므로 F2값이 커질수록 오답, 즉 /ㅗ/이외의 모음으로 지각할 확률이 커진다. 3.1에서 제시한 것처럼 /ㅗ/의 오답으로는 /ㅜ/가 거의 모두이므로 F2가 클수록 /ㅜ/가 될 확률이 높아진다. /ㅜ/의 경우도 F2의 추정치가 마이너스이므로 F2값이 클수록 오답으로 지각할 확률이 커지지만 /ㅜ/의 오답은 /ㅡ/가 많았기 때문에 /ㅡ/로 지각될 가능성이 높아진다. F1의 추정치는 /ㅗ/의 경우 남녀 모두 플러스이므로 F1값이 클수록 정답인 /ㅗ/로 지각할 확률이 커진다. /ㅜ/의 F1은 남녀의 부호가 반대로 남성은 마이너스이므로 F1값이 클수록 오답인 /ㅗ/로 지각될 가능성이 커진다(F1값이 커지면 개구도가 커지므로 /ㅡ/로 지각될 가능성은 적다). 여성은 F1의 추정치가 플러스이므로 F1값이 클수록 /ㅜ/로 지각할 확률이 커지는데 그러면 F1값이 클수록 /ㅗ/로 나타나는 생성의 결과와 모순된다. 다만 추정치의 절댓값이 상당히 작기 때문에 F1의 영향력은 매우 작다(H1-H2, F0보다도 작다). H1-H2의 추정치는 남녀 모두 /ㅗ/에서 마이너스, /ㅜ/에서 플러스로, H1-H2값이 클수록 /ㅜ/의 확률이 높아진다. 이것은 여성의 발화에서 /ㅜ/의 H1-H2값이 크게 나타나고 /ㅗ/의 H1-H2값이 작게 나타나는 생성의 결과와 일치한다. 다만 남녀 모두 H1-H2의 영향력은 상당히 작아, 지각에서 H1-H2는 거의 사용되지 않는다고 봐야 할 것이다. F0는 생성에서 고모음인 /ㅜ/가 고모음이 아닌 /ㅗ/보다 높게 나타나는데 /ㅗ/의 결과는 남녀 모두 /ㅗ/, /ㅜ/의 결과는 여성의 F0가 클수록 /ㅗ/로 지각될 확률이 커져 생성에서의 음향특성과 맞지 않는다. 남성의 /ㅜ/는 F0가 클수록 /ㅜ/로 지각될 확률이 커지므로 생성의 결과와 일치하나 추정치 자체가 매우 작아 영향력이 거의 없고 유의하지도 않다. 따라서 ㅗ/ㅜ의 지각에 있어 F0효과가 있다고는 보기 어려울 것 같다.
4. 논의
생성과 마찬가지로 지각에서도 포먼트는 모음 구별에 중요한 역할을 한다. 자연음을 사용한 본고의 자극음은 F2가 결정적인 역할을 하는 것으로 나왔는데 이것은 주어진 자극음에 따른 것으로 F1의 차이가 큰 자극음을 사용할 경우에는 F1이 결정적인 역할을 하게 될 것이다. 핵심은 모음 지각에 포먼트가 결정적인 역할을 한다는 것이다. 이에 대해서는 남녀 모두 같은 결과이다.
본고의 결과를 정리하면 표 5와 같다. 지각은 본고의 결과이고 생성은 그림 2, 3에서 가져온 것이다(생성에서 여성의 F1과 F2는 같은 △표시이지만 실제로는 F2 효과가 더 크다. 다만 남성의 포먼트 효과보다는 작다). 표 5에서 보는 것처럼 생성에 있어 ㅗ/ㅜ의 일차적 음향특성은 남성은 포먼트, 여성은 H1-H2로 볼 수 있다. 본고의 목적은 특히 여성의 경우 생성에서 쓰이는 H1-H2가 지각에서도 쓰이고 있을 것으로 예상하고 그 정도를 확인하고자 하는 것이었으나 결과는 예상과 달리 남녀를 불문하고 지각에서 H1-H2는 기능하고 있지 않았다. 다만 이것은 H1-H2가 지각에 전혀 관여하지 않는다는 것은 아니다. 그림 7, 9에서 본 것처럼 포먼트로 구별이 어려운 경우에는 분명히 H1-H2가 기능하고 있기 때문이다(그림 7과 그림 10(왼쪽), 그림 9와 그림 10(오른쪽)). 다만 포먼트에 비하면 그 정도가 미미하여(182예 중 몇몇 예에 불과) 표 5에 반영될 만큼의 영향력을 갖고 있지 않다고 보는 것이 적절할 것이다.
| 음향 변수 | 지각 perception | 생성 production | ||
|---|---|---|---|---|
| 남성 male | 여성 female | 남성 male | 여성 female | |
| F1 | X | X | ○ | △ |
| F2 | ○ | ○ | ○ | △ |
| H1-H2 | X | X | X | ○ |
본고의 결과가 ㅗ/ㅜ의 융합과 어떤 관련이 있는지 생각해 본다. 모음 공간상의 ㅗ/ㅜ의 접근은 앞으로도 계속 진행될 것으로 예상된다. 남성의 발화에서는 아직 ㅗ/ㅜ가 충분히 떨어져 있지만 그림 2에서 보는 것처럼 아랫세대일수록 ㅗ/ㅜ의 F1의 거리가 조금씩 좁아지고 있고 이것이 더욱 진행되면 여성의 발화의 F1과 같은 상태가 될 것이다(현재 남녀 간에는 50년 이상의 차이가 있다). 동시에 F2에서도 변화가 일어날 것이다. 현재 남성의 발화에서 F2에는 변화가 없는 것으로 보이나 여성의 발화와 같은 절차를 밟는다면 F1이 어느 정도 가까워진 후에 F2가 그 뒤를 따를 것으로 예상된다. 그와 동시에 또는 그에 앞서 H1-H2의 차이가 나타나기 시작할 것으로 보인다. 다시 말해 포먼트의 구별이 완전히 없어지기 전에 포먼트를 대신할 파라미터의 준비가 행해질 것으로 예상된다. 이런 변화가 일어날 것이라고 보는 이유는 현재 관찰되는 ㅗ/ㅜ의 접근이 개별적인 현상이 아니고 모음 전체의 안정을 꾀하기 위한 체계 변화의 일환으로 여겨지기 때문이다.
공시적인 음변이가 통시적인 음변화로 이어질 경우 변화의 발단이 청자에게 있다고 본다면(Ohala, 1981, 2012) 청자가 들은 음을 어떻게 해석하여 다시 생성하느냐8 하는 문제 이전에 청자가 들을 '음(의 음향특성)'이 존재해야 한다. 음변화가 지각에서 먼저 시작하여 생성을 거쳐 최종적인 변화로 이어진다고 보는 견해는 최근의 연구(Beddor, 2009, 2012; Harrington, 2012; Kuang & Cui, 2018)에서도 찾아볼 수 있는데 생성과 지각의 관계는 이미 기저에 있는 음향특성을 청자가(잘못 듣던 제대로 듣던) 듣는 것을 먼저로 본다. 기존에 있는 음향변수가 강화(enhancement)되어 주된 변수로 대두되는 경우와는 달리 지금까지 없었던 완전히 새로운 특성이 사용되는 경우에는 혁신 화자(innovative- speaker)인 누군가에 의해 발화될 필요가 있다. 본고에서 다룬 ㅗ/ㅜ의 구별에 H1-H2가 쓰인 발화는 포먼트만으로 구별해 왔던 종래의 발화와는 완전히 다른 발성법이라고 할 수 있다9. 혁신 화자가 누구였는지는 특정할 수 없으나 여성 화자들은 이미 1950년대 출생자도 H1-H2 차이로 ㅗ/ㅜ를 발화하고 있다. 이 H1-H2 차이로 ㅗ/ㅜ를 구별하는 혁신 청자(innovative-listener)가 있는 것은 그림 10의 왼쪽과 오른쪽에서 이미 확인하였다. 동정률이 거의 100%이어도 포먼트만으로는 설명이 안되고 H1-H2가 있어야만 설명이 가능하기 때문이다. 다만 지각특성으로써 H1-H2의 역할을 포먼트와 비교하면 표 4에서 본 것처럼 그 영향력이 극히 미미하여 변별기능이 충분히 발달되어 있다고는 보기 어려운 상황이다. 기저에 있는 H1-H2가 강화되어 지각특성으로 발달한다면 그 순서는 여성의 지각에서 먼저 확립될 것으로 예상된다. 생성에서 이미 사용되고 있기 때문이다. 위에서 언급한 것처럼 음변화가 청자의 지각에서부터 시작된다면 그 다음으로는 남성의 지각에서 H1-H2가 확립된 후에 남성의 생성으로 H1-H2의 사용이 넓혀질 것으로 예상된다. 물론 그렇지 않은 경우도 있을 수도 있다. 청자가 H1-H2를 인식하지 못하여 지각특성으로 발달하지 못하고 그대로 묻혀버린다면 포먼트의 융합이 진행되고 있는 현상황에서 ㅗ/ㅜ의 구별은 불가능하게 되고 최종적으로는 ㅐ/ㅔ와 같은 융합의 길을 걷게 될 것이다.
우리는 지금도 '호도'인지 '호두'인지 헷갈릴 때가 있다. 이것은 발음의 문제가 아니라 철자의 문제라고 하는 이도 있겠지만 비어두에서의 ㅗ/ㅜ의 혼동(주로 /ㅗ/를 /ㅜ/로 혼동)은 Kwak(1980)에 의하면 18세기 중엽 이후부터 시작된 변이현상이다. 20세기에 들어와서는 어두에서 보이기도 하나(돈 → 둔, Lee, 1971), 학교 교육이 보편화되고 사전이나 맞춤법 개정이 있을 때마다 혼동이 심한 어형을 정리하고 표준발음으로 규정해 왔기 때문에(Chae 1999, 2000) 규범의식이 작용하면 어형과 그에 따른 철자의 혼란을 바로 잡을 수 있다. 그러나 지각적으로 차이가 모호해지고 언어변화에 직결하는 어두에서 /ㅗ/를 /ㅜ/로 발음하는 일이 잦아진다면 ㅐ/ㅔ와 같은 융합이 일어날 가능성도 배제할 수 없다. ㅐ/ㅔ가 비어두에서 시작하여 어두에서 구별이 없어지고 학교 교육으로 인해 철자의 구별이 철저히 지켜지는데도 불구하고 융합된 것을 보면 규범의식으로 언어변화를 저지할 수 없다는 것을 알 수 있다.
그렇다면 ㅗ/ㅜ가 ㅐ/ㅔ와 같은 길을 밟을 것인가. 서론에서도 말했지만 필자는 ㅗ/ㅜ가 포먼트에 의한 구별이 없어진다고 해도 H1-H2에 의해 구별이 유지될 것으로 예상한다. 그 이유는 모음 ㅗ/ㅜ의 특이성이다. Kwak(1999)은 모음조화 붕괴의 한 요인으로 여겨지는 근대국어 초기에 널리 보이는 비어두에서의 /ㅗ/ → /ㅜ/의 변화(예를 들면 '나모' → '나무')는 첫음절의 양성모음 /ㅏ/의 조화력이 약해져 일어난 현상이며 이것은 '옛 체계에 바탕을 둔 모음조화보다 새로운 체계에 바탕을 두고 나타난 "ㅗ>ㅜ"가 더 강력한 힘을 가졌기' 때문으로 설명하고 있다. Kwak(2003)은 ㅐ/ㅔ의 융합, /ㅓ/음가의 변화를 포함한 현대 서울말(중부 방언)의 모음 체계가 개구도를 줄이려는 일반적인 경향과 좀 더 유표적(marked)인 모음이 제거되는 일반적인 원리에 따라 변화하고 있다고 보고 있다. 그리고 언어 일반에서 /i, a, u/가 가장 보편적이고 그 다음이 /e, o/가 추가된 5모음인 것을 고려한다면 현 7모음에서 가장 변화 가능성이 높은 것은 /ㅡ/와 /ㅓ/이며 보다 유표적인 /ㅓ/가 변화한 6모음 체계로 변화할 것이라고 예상하였다. 다만 그림 4와 그림 5(왼쪽)에서 보듯이 모음 공간상에서 /ㅓ/의 위치는 상당히 확고하며 다른 모음의 영향을 받을 가능성은 적어 보인다10. /ㅡ/는 /ㅜ/와 위치가 가까워 위태로워 보이기는 하나 ㅗ/ㅜ 정도는 아니다.
본고는 서울말의 모음체계가 모음 공간상에서 현재의 7모음 체계에서 6모음 체계로 변화할 것으로 예상하나 실제로는 /ㅗ/와 /ㅜ/가 각각의 음소로 구별되는 7모음 체계가 유지될 것으로 내다본다. ㅗ/ㅜ의 설명을 위해서는 모음의 음질 차이를 고려할 필요가 있어 종래의 모음 간 거리에 기반을 둔 포먼트를 이용한 모음 체계만으로는 설명이 어려워지겠지만 위에서 언급한 것처럼 개별 음소로써 /ㅗ/와 /ㅜ/를 선호하는 언어의 보편적 입장에서 보면 다른 모음과 구별 방법을 달리 하더라도 두 모음이 유지될 가능성이 크다고 본다.
5. 결론
본고에서는 F1, F2를 변수로 하는 모음 공간에서 ㅗ/ㅜ의 접근으로 인한 융합의 가능성에도 불구하고 지각적으로 ㅗ/ㅜ 사이에 혼동이 보이지 않는 것과 관련하여 여성의 발화에서 확인된 ㅗ/ㅜ의 H1-H2 차이가 지각에서도 기능하고 있을 것으로 예상하고 검증를 위해 지각실험을 실시하였다. 그러나 지각에서 H1-H2가 ㅗ/ㅜ의 구별에 유의하게 관여하고 있다는 증거를 얻지 못하였다.
지각 정답률이 100%인 자극음에서 포먼트로 구별이 어려운 경우에 H1-H2 차이가 유의하게 작용하는 것은 H1-H2가 지각에 관여한다는 것을 시사한다. 다만 ㅗ/ㅜ의 구별에 미치는 변수 간의 영향력은 포먼트가 압도적으로 커서 ㅗ/ㅜ 전체로 봤을 때 지각특성으로써의 H1-H2의 역할은 극히 미미하다. 이에 대해서는 H1-H2가 지각특성으로 아직 충분히 발달되지 않았을 가능성에 대해서 논하였다.
앞으로의 과제가 되겠지만 H1-H2가 지각에서 쓰이고 있는 것을 확인하는 방법의 하나로 동일 화자=청자를 대상으로 한 조사를 생각해 볼 수 있다. 생성에서 H1-H2를 사용하는 이가 지각에서도 H1-H2를 사용할 가능성을 조사하는 것이다. 이를 위해서는 본고와는 다른 실험 디자인이 필요할 것이다.