





1. 서론
인간의 언어는 언어마다 독특한 억양과 리듬을 갖고 있으며 이러한 운율적 특징은 단어나 문장의 발화 길이와 밀접한 관련을 맺고 있다. James(1940)는 언어마다 고유한 리듬이 있음을 증명하였고 Pike(1945)와 Abercrombie(1967)는 음성 언어를 크게 강세 박자 언어와 음절 박자 언어로 구별하였다. 이후 Ladefoged (1975)는 이 분류에 모라 박자 언어를 추가시켜 언어의 리듬을 크게 세 분류로 구분했다.
영어는 강세 박자 언어로 문장 내의 강세를 갖는 부분(강세 음절)이 일정한 시간 간격을 두고 문장 리듬을 형성한다. 반면 한국어는 음절 박자 언어에 속하는 언어로서 강세 음절이 아닌 매 음절이 일정한 시간 간격을 이루게 된다. 아울러 영어와 같은 강세 박자 언어에서 한 문장의 각 구조 단위에서는 일반적으로 내용어(content word)가 기능어(function word) 대비 어구 강세를 받게 되어 이러한 강세를 바탕으로 하는 리듬 패턴이 문장 또는 어구 단위에서 생성된다.
강세를 이루는 가장 중요한 세 가지 음성적 요소로는 음장, 높이, 크기를 들 수 있다. 하지만 이들 중 어느 것이 언어의 인지나 발화에 있어서 가장 핵심적인 역할을 하는지에 관해서는 연구자마다 그 견해가 상이하다. Klatt(1976)에 따르면 음장이 단모음과 장모음 사이의 차이를 인지하는 과정과 더불어 강세를 받는 모음과 강세를 받지 않는 혹은 약화된 모음 사이의 차이를 인지하는데 가장 중요하다고 주장한다. 같은 맥락으로 화자들의 발화 양상에 주목한 Avery & Ehrlich(1992)에 따르면 음의 길이가 강세에 가장 큰 영향을 미치는 요소라고 주장하였는데, 이와는 대조적으로 Gimson & Ramsaran(1989)은 음의 높이, Dalton & Seidlhofer(1994)는 음의 크기가 강세를 판단하는 요인임을 주장하였다.
영어에서의 단어는 크게 내용어와 기능어로 구분시켜 정립될 수 있는데 Carroll(1964)에 따르면 명사, 동사, 형용사, 그리고 대부분의 부사는 내용어로 범주화되며 이 내용어들은 문장에서의 핵심적인 의미를 전달하게 된다고 설명한다. 반면 관사, 전치사, 접속사, 조동사 그리고 대명사 등은 기능어로 구분되어 이 품사들의 경우 문장 내에서 의미 전달이 아닌 문장을 구성하기 위한 문법적 역할을 수행한다고 알려져 있다.
Umeda(1975)는 미국 영어에서 모음의 리듬 변이를 조절하는 요소로 위치 조건, 분절음 조건과 더불어 기능어-내용어 사이의 구분을 제시하였다. 따라서 영어의 운율 구현 측면에서 의미를 전달하는 내용어가 구강세(phrasal stress)의 핵심 부분을 차지하게 되고, 문장 구성을 위한 문법적 역할을 하는 기능어의 경우는 통상적으로 강세를 갖지 않게 되거나 내용어의 강세보다는 약화된 강세를 띠게 된다. 이러한 특질로 인하여 영어의 내용어 모음들은 기능어보다 상대적으로 더 길게, 더 높고 큰 소리로 발화된다. 이를 반영하여 영어를 모국어로 사용하는 원어민들은 강세 모음과 비강세 모음 발음 시 발화 길이의 상대적 차이를 두고 발화하는 양상을 보이는데 한 개의 음절로 이루어진 내용어 명사와 기능어인 관사(이 경우도 한 개의 음절로 구성됨)로 이루어진 명사구(Noun Phrase, NP)의 경우 1 음절어 명사 모음은 관사 모음에 비해 더 길고, 더 크게, 또한 더 높은 소리로 발화한다. 예를 들어 영어의 명사구 “the bus”의 경우 내용어에 해당하는 명사 “bus”에서의 모음 [ʌ]는 기능어인 관사 “the”의 모음 [ə]보다 길게 발화되고 더 높고 더 큰 소리로 발음된다. 이 때문에 같은 모음이라 할지라도 내용어로서 강세를 받는 모음인지 혹은 기능어 안에서 강세를 받지 않는 모음인지에 따라서 모음 길이에 있어 차이가 나타나게 되며 이는 영어 발화에 있어서 중요한 운율적 특징이 된다고 정리할 수 있다.
한편 한국어는 영어와 다르게 강세 박자 언어가 아니라 음절 박자 언어에 속하므로 한국어 화자는 비강세 모음을 적절하게 구현하지 못한다. Avery & Ehrlich(1992)는 음절 박자 언어를 모국어로 하는 영어학습자들은 영어 비강세 모음을 약화된 모음(reduced vowels)이 아닌 완전 모음(full vowels)으로 발화하는 경향이 있다고 주장한다. 따라서 영어에서 강세로 인하여 나타나게 되는 내용어와 기능어 사이의 모음 발화 길이의 차이가 영어에 비하여 상대적으로 한국어에서는 두드러지게 나타나지 않으며 이러한 이유로 한국인 화자들은 영어 단어나 문장을 발화할 때 모음 길이 차이를 인지하여 발화하는 데 어려움을 보일 것이라고 예상할 수 있다.
관련하여 한국인과 일본인 화자들의 영어 모음 발화시 나타나는 특성을 조사한 Lee et al.(2006)의 연구에 따르면 한국어와 영어를 구사하는 한국인 이중 언어 화자들은 영어 단어나 문장 발화시 비강세 모음을 원어민보다 더 길게 발음하여 궁극적으로 강세 모음과 비강세 모음 사이의 발화 길이 차이가 원어민에게서의 차이보다 작다는 것을 보고하였고, 원어민의 경우 강세 모음을 비강세 모음보다 평균적으로 2배 더 길게 발화하는 반면에 한국어-영어 이중 언어 한국인 화자의 경우 강세 모음을 더 길게는 발음하였으나 비강세 모음보다 2배만큼 길게 발화하지는 않음을 보고하였다. 더불어 한국인 이중 언어 구사자들은 일본어와 영어를 구사하는 일본인 이중 언어 화자들보다 비강세 영어 모음을 더 길게 발음하는 경향을 주지하였는데 이는 McAllister et al.(2002)의 연구를 지지하는 것으로서 L2의 특정한 음성학적 특질이 L1에도 존재한다면 화자가 L2를 구사할 때 더 정확히 원어민과 유사하게 발화할 수 있음을 암시한다. 이 연구에서는 일본어의 경우 같은 음소라 할지라도 음소 간의 발화 길이 차이가 존재하며 이것이 영어에서처럼 의미 있는 음운적 자질이 되기 때문에 영어 단어에서 강세 모음과 비강세 모음을 한국인 화자들보다 더 정확하게 구분하여 발화하거나 영어 원어민 화자와 비슷한 길이로 발화할 수 있게 된다는 것으로 해석하였다. 이와는 다르게 한국어의 경우 같은 음소 간 강세로 인한 발화 길이 차이가 미미하고, 그 차이가 음운적 자질이 되지 않기 때문에 한국인 화자들은 영어 강세 모음과 비강세 모음의 발화 길이의 차이를 일본인 화자들보다 더 적게 두어 발화하는 것으로 이해될 수 있다.
영어의 모음 약화에 대하여 세부적으로 연구한 Yoo(2014)의 연구에서는 기능어를 다시 2개의 하위 범주로 나누어 상대적으로 강세를 받는 모음이 있는 기능어(F: stressed)와 상대적으로 강세를 받지 않는 모음이 있는 기능어(F: unstressed)로 구분 짓고, 이 기능어 간 발화 길이의 차이에 대하여 논의하였다. 연구에 따르면 영어 원어민 화자의 경우 같은 기능어 집단에 속하는 단어일지라도 그 단어가 약한 강세를 갖는 기능어인지, 강세를 갖지 않는 기능어인지에 따라 화자들이 이 기능어 단어 간 발화 길이의 차이를 보였다고 주장한다. 또한 한국인 화자들도 영어 원어민 화자들이 보인 결과와 유사한 양상을 보였음을 보였다.
본 연구는 강세 음절과 비강세 음절 사이의 음장 차이에 집중하여 한국인 영어 학습자들(초등학생)이 강세를 갖는 내용어 모음과 일반적으로 강세를 갖지 않는 기능어 모음 간의 상대적 음장 차이를 언어 학습자의 능숙도와 관련지어 살펴보고자 한다.
발화자의 L1 전이(L1 transfer)를 전제로 한다면 한국인 영어학습자들은 영어 문장을 발화할 때 문장 어구 내의 강세에 대한 인식이 영어 원어민 화자보다 미비할 것으로 예측되며 또한 이러한 특징이 그들의 발화에도 반영될 것으로 예상되는데 이러한 현상은 영어 문장 내 어구 발화에서 단어를 발화할 때 강세를 갖는 단어와 강세를 갖지 않는 단어 사이에 확연한 차이를 두고 발화하는 데 어려움을 겪을 것이며 영어 문장 내에서 강세를 갖는 단어와 강세를 갖지 않는 단어 사이의 발화 길이의 차이가 원어민보다 현격히 작을 것으로 가정할 수 있다.
정리하자면, 본 연구는 한국인 영어학습자들을 대상으로 발화된 영어 문장에서 관사와 1음절 명사로 이루어진 명사구의 모음 길이 분석을 통해 강세를 갖지 않는 관사 내의 모음과 강세를 갖는 1음절 명사 내의 모음 길이의 차이가 화자의 영어 능숙도와 어떠한 상관관계를 맺고 있는지 알아보고자 한다.
2. 연구 방법 및 절차
본 연구에서는 2004년 수집된 한국인의 영어 발음 음성코퍼스(Korean-Spoken English Corpus, K-SEC) 자료와 이 자료 중 초등학생의 K-SEC 음성 자료를 바탕으로 Park(2018)에 의해 유창성 평가를 거쳐 구축된 한국인의 영어 발음 ‘평가’ 음성코퍼스(Rated Korean-Spoken English Corpus, Rated K-SEC)를 활용하였다. 본디 K-SEC은 한국인에 의해 발화된 영어를 디지털 자료화한 것으로 지역(각 도 단위), 연령(초등, 중등, 대학생 및 일반성인으로의 3구분) 및 성별에 따른 한국인의 L2 영어 음성을 대용량으로 녹음하여 구축한 음성코퍼스이다. 또한 여기에는 영어 원어민 화자의 발화가 포함되어 영어를 모국어로 사용하는 화자와 한국인 화자 간의 영어 발화 양상을 비교하기에 용이하다.
Rated K-SEC은 기존의 K-SEC 데이터에서 초등학생들이 발화한 문장만을 구분, 선별하여 총 3,069개에 달하는 발화 문장을 5인의 평가자(한국인 평가자 3인, 원어민 평가자 2인)가 문장의 유창성을 기준으로 평가한 후 평가 등급별로 발화 자료를 구분해 놓은 음성코퍼스이다. 평가에서 등급은 1–5점으로 책정되었으며, 평가는 Genie Corpus Rubric(Rhee, 2017)을 기준으로 ETRI(한국전자통신연구원)의 도움을 받아 ETRI 온라인 평가시스템이 사용되었다. 각 발화 문장에 대해 평가자들은 평가 오리엔테이션을 갖고 캘리브레이션을 위한 예비 평가 후 총체적(holistic) 평가와 분석적(analytic) 평가를 모두 행하였으며, 분석적 평가에서 그 기준은 ‘발화속도와 휴지’, ‘단어와 문장의 강세 및 리듬’, ‘억양’, 그리고 ‘분절적 자질’ 평가로 구성되었다(평가자 간 신뢰도는 유목 내 상관계수 산출 결과 총체적 평가에서는 0.84, 분석적 평가에서는 0.96으로 평가자 간 강한 상관관계를 나타내었다).
본 연구에서는 총체적(holistic) 평가 결과를 바탕으로 관찰 대상인 “관사-1음절 명사”(예를 들어 the cap)로 구성된 명사구를 포함한 879개의 문장을 추렸으며(879개의 분석대상 명사구에는 원어민이 발화한 20개 포함), 이 문장들 안에 있는 관사와 1음절 명사로 이루어진 명사구 음성을 별도로 추출, Praat(ver. 6.0.18)를 통해서 추출된 음성의 관사 모음과 명사 모음의 발화 길이를 각각 측정하였다. 분석의 대상이 된 명사구의 종류 수는 총 10개이고 기능어인 관사 모음의 경우 강세를 받지 않는 모음 [ə]를 측정하였고, 내용어 1음절 명사 모음의 경우 이완모음([ɪ, ɛ, æ, ʌ, ɔ])들의 길이를 측정하였다. 관사와 1음절 명사로 이루어진 명사구가 나타나는 Rated K-SEC 문장의 예는 다음과 같다.
위의 표 1은 관사와 1음절 명사로 구성된 측정 대상 명사구를 각 명사의 모음 높이에 따라 분류하여 명시한 것이다. 본 연구는 분석대상 명사구를 포함한 총 879개의 문장을 4개의 등급(Novice, Intermediate-Low, Intermediate-High, Advanced (& Native speakers))으로 구분하였다. 이 등급은 평가자 5명이 제시한 평가의 평균값을 바탕으로 1–1.9는 의 점수를 받은 문장은 Novice, 2–2.9를 받은 문장은 Intermediate-Low, 3–3.9는 Intermediate-High, 4–5는 Advanced 그룹으로 구분하였고, 원어민 초등 발화자 2명의 문장 발화 자료를 포함하여 원어민 그룹이 발화한 문장과 112명의 한국인 초등학생이 발화한 문장을 함께 비교하였으며 오류 발화나 자연스럽지 못한 발화(지나치게 느리게 발화한 경우) 자료는 제외하였다. 각 능숙도 그룹에 속하는 발화 문장 개수는 다음과 같다(표 2).
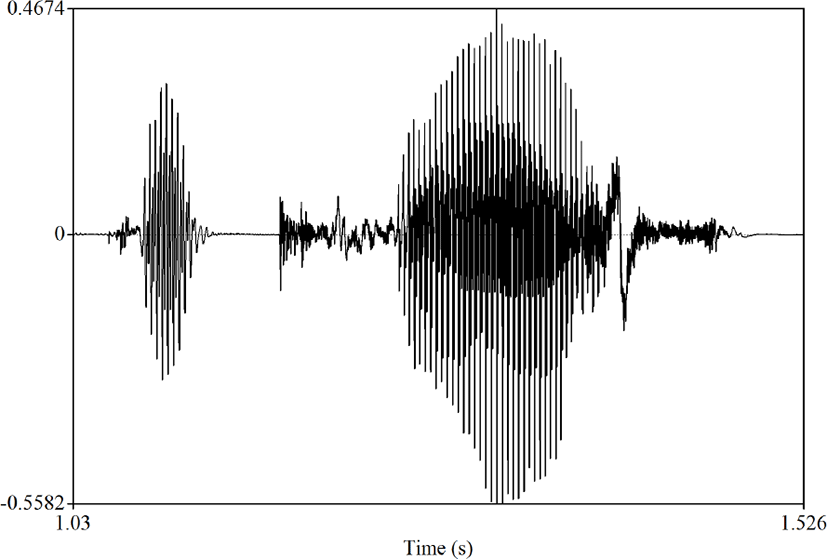
한 개의 음절로 구성된 내용어와 기능어 모음의 상대적인 길이 차이를 분석하기 위해 음성 분석 프로그램인 Praat를 사용하였으며 스펙트로그램과 파형을 근거로 모음의 길이를 측정하였다. 아래 그림 1은 분석의 대상이 된 명사구 중 하나인 “the class”의 파형을 나타낸 것으로, 본 연구에서는 측정 시의 오차를 줄이기 위해 스펙트로그램의 F2값과 모음 소리가 시작되는 규칙 파형에 기준을 두고 자료를 분석하였다. 더불어 통계 분석을 위해 SPSS 25.0 이 활용되었다.
3. 연구 결과 및 분석
아래 표 3은 영어 능숙도에 따라 나눠진 각 그룹의 발화에서 관사와 1음절의 명사로 이루어진 명사구 안에서 각 모음의 평균 발화 길이를 수치화한 것이다. 이를 통해 관사 모음의 평균 발화 길이, 명사 모음의 평균 발화 길이를 알 수 있으며, 관사 모음 발화 길이 대비 명사 모음 발화 길이의 비율 또한 확인할 수 있다.
그림 2는 관사 내 모음의 평균 발화 길이, 명사 내 모음의 평균 발화 길이를 그래프로 나타낸 것이며 그림 3은 관사 모음 발화 길이 대비 명사 모음 발화 길이의 비율을 시각적으로 그래프화 한 자료이다.
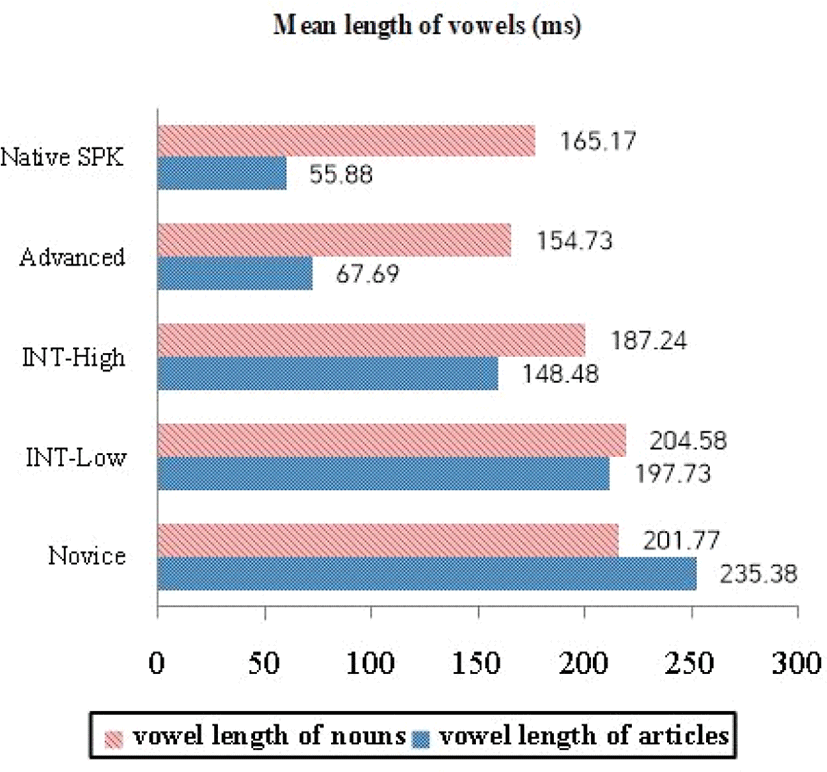
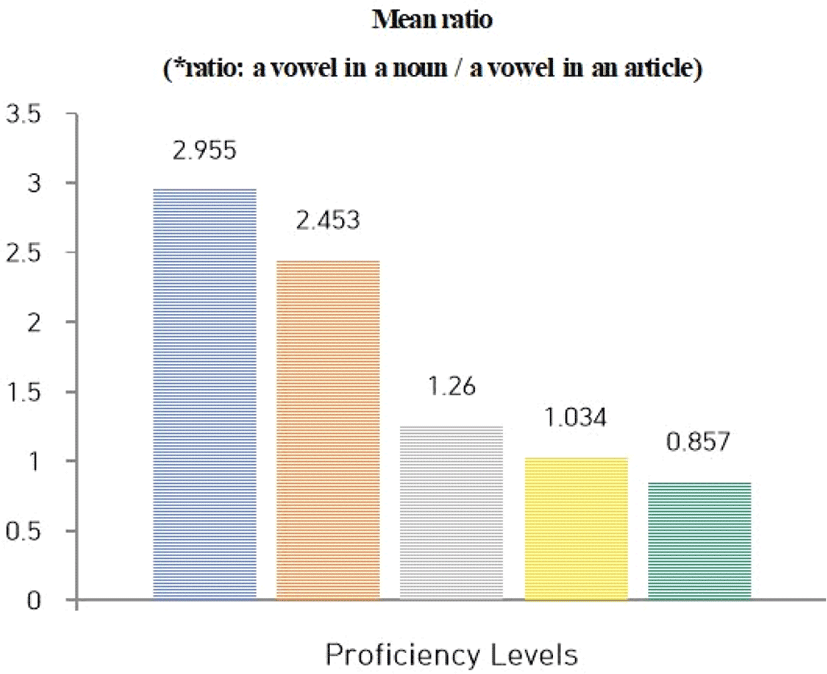
먼저 그림 2에서는 원어민(초등학생) 화자의 경우 관사 모음을 평균 55.88 ms 길이로 발화하고 명사 모음은 평균 165.17 ms로 발화한 것을 확인할 수 있다. 종합적으로 원어민의 경우 명사 모음을 관사 모음보다 2.955배 더 길게 발화한 것을 볼 수 있다(그림 3).
한편 능숙도 최상위(ADV)의 그룹으로 분류된 한국인 화자들의 문장 내 명사구에서의 관사 모음은 평균 67.69 ms의 길이로 발화되었으며 1음절 명사 모음은 평균 154.73 ms의 길이로 발화되어 명사 모음이 관사 모음 발화 길이 대비 평균 2.453배 더 길게 발화된 것을 볼 수 있다. 이 그룹의 문장들은 특별히 다른 그룹과 비교했을 때 내용어인 명사 모음을 기능어인 관사 모음 대비 가장 긴 발화 길이의 차이를 두고 발음된 점을 주목할 필요가 있다.
중상위(INT-High) 그룹 평가를 받은 문장들 명사구에서의 관사 모음은 평균 148.48 ms로 발화되었고, 명사 모음은 187.24 ms의 길이로 발화되었다. 관사 모음 대비 명사 모음 발화 길이의 비율은 1.26으로 이 능숙도 그룹에 속하는 문장들의 명사구 안의 명사 모음은 관사 모음보다 1.26배 더 길게 발화되었다.
중하위(INT-Low) 능숙도 그룹의 경우 평균적으로 관사 모음이 197.73 ms, 명사 모음은 204.58 ms로 발화되어 명사 모음이 관사 모음 대비 1.034배 더 길게 발화되었다(즉, 거의 같은 길이로 발화되었다). 중상위 그룹과 중하위 그룹의 문장 내 명사구에서 명사 모음은 관사 모음보다 길게 발화되어 능숙도 최상위 그룹 문장들이 보인 경향성(명사 모음이 관사 모음보다 길게 발화되는 현상)을 유지하지만 이 비율 값은 능숙도 하위 그룹으로 내려갈수록 작아지게 되는데, 중하위 평가를 받은 문장들에서 명사구 내 모음 길이 비율 값이 1에 가까운 1.034로 명사 모음과 관사 모음이 거의 비슷한 길이로 발화된 것을 확인할 수 있다.
이와는 대조적으로 영어 능숙도 최하위(NOV) 그룹 평가를 받은 문장들에서의 명사구 내 모음 길이 비율 값은 여타 다른 상위 3개 그룹에서와는 달리 오히려 기능어인 관사 모음이 내용어인 명사 모음보다 더 길게 발화된 것으로 나타났다. 이들 문장에서 관사 모음은 평균 235.38 ms, 명사 모음은 평균 201.77 ms의 길이로 발화되었다. 따라서 관사 모음 발화 길이 대비 명사 모음 발화 길이의 비율이 0.857로 계산되는데, 이 비율 값이 1보다 작으므로 능숙도 최하위 평가를 받은 한국인 영어학습자들의 발화에서는 명사구 내 관사 모음은 명사 모음보다 오히려 더 길게 발화된 것으로 나타난다.
일원변량분석 결과(표 4)에서1, 종속변수를 관사 모음 발화 길이 대비 명사 모음 발화 길이의 비율 값으로, 독립변수를 영어 능숙도로 설정하였을 시 각 그룹이 보이는 관사 모음 발화 길이 대비 명사 모음 발화 길이의 비율 값의 그룹 간 차이가 유의미한 것으로 나타났다(F(3, 849)=31.303, p<.001).
능숙도 그룹에 대한 사후 검정 결과(표 5) 최상위 그룹(ADV)에서는 명사구 내 관사 모음 발화 길이 대비 명사 모음 발화 길이의 비율 값이 능숙도 중상위 그룹(INT-High)과 중하위 그룹(INT-Low) 그리고 최하위 그룹(NOV)에서보다 유의하게 더 높음을 알 수 있다(p<.001). 중상위 그룹(INT-High)의 경우, 중하위 그룹(INT-Low)보다 관사 모음 길이 대비 명사 모음 길이 비율 값이 유의하게 높았으며(p<.001), 최하위 그룹 평가(NOV)를 받은 문장들의 명사구와의 비교에서도 그 비율 값이 유의미하게 높게 나타났다(p<.05). 그러나 중하위(INT-Low) 그룹과 최하위(NOV) 평가를 받은 그룹 사이에서는 비율 값의 차이가 유의미하지 않았다.
4. 결론
본 논문은 영어를 제2외국어로 구사하는 한국인 초등학생이 발화한 영어 문장을 대상으로 관사와 1음절의 명사로 구성된 명사구 안에서 관사와 명사의 모음 길이 차이를 확인하고 이것이 한국인 영어학습자의 영어 능숙도와 어떠한 상관관계를 보이는지를 밝히고자 하였다. 분석 결과, 최하위 영어 능숙도 평가를 받은 그룹을 제외한 나머지 상위 세 개 그룹에서의 문장 내 명사구에서는 명사 모음이 관사 모음보다 더 길게 발화되었음을 확인하였으며, 명사구 내 관사 모음 길이 대비 명사 모음 길이의 비율은 영어 능숙도와 양의 상관관계를 갖는다는 점을 확인할 수 있었다. 즉 앞서 본 연구의 가설에서 제시한 것처럼 한국인 영어학습자들의 경우 그들의 영어 능숙도가 높을수록 내용어의 강세를 갖는 모음과 기능어의 강세를 갖지 않는 모음 사이에 더 확연한 모음 길이 차이를 두고 발음한다고 정리될 수 있다. 이러한 결과는 한국인(초등학생) 영어학습자들의 경우 영어 단어를 발화함에 있어서 한국어에는 나타나지 않거나 혹은 미비하게 나타나는 단어 내의 강세를 구분하고 발화하는데 어려움을 겪을 것이나 영어 능숙도가 높아질수록 이를 뚜렷하게 구분하고 발화하여 원어민 화자와 유사하게 발화할 것이라는 본 연구의 가설을 지지하는 것으로서 L2에 존재하는 음성학적 특징이 L1에 없다면 L2 학습자가 L2를 구사할 때 원어민과 유사하게 발화하기가 어렵다는 종래 McAllister et al.(2002)의 연구를 뒷받침할 수 있는 근거가 된다.
다수의 선행 연구는 발음 교육에 있어서의 초분절음(suprasegmentals) 지도의 중요성을 제시하였다(Morley, 1987, 1991; McNerney & Mendelsohn, 1992). 특히 Derwing et al.(1998)의 연구에서는 초분절음 중심의 교육이 자연스러운 발화에 핵심적인 역할을 수행함을 보고하였다. 따라서 본 연구는 이전의 선행 연구와 더불어 앞서 논의한 연구 결과를 통해 한국인 학습자의 영어 교육에 있어서 그들에게 분절음뿐만 아니라 강세와 같은 초분절음의 중요성을 인식시키고 교육해야 할 것을 강조하는 바이다. 특히 문장 내에서 내용어와 같이 강세를 갖는 단어나 기능어와 같이 강세를 갖지 않거나 약화된 강세를 갖는 단어를 발화할 때 두 단어 사이 발화 길이에 분명한 차이를 두고 발음해야 할 필요성과, 청취에 있어서도 이러한 강세의 차이가 어떠한 식으로 구현되는지 학습자에게 인식시켜야 할 필요성이 있다.
끝으로 연구에서 활용된 코퍼스가 한국인 초등학생의 발화로 한정되었다는 점에 있어서 본 연구의 결과를 다른 연령층의 발화 양상에 일반화시키기 위해서는 추가적인 후속 연구가 필요하다. 특히 추후 연구에서는 피험자를 20대 이상의 성인으로 확대하여 비교연구를 진행하는 것도 흥미로운 연구 주제가 될 것으로 생각한다. 또한 그들의 영어학습 기간을 또 다른 독립변수로 설정하여 실험을 진행한다면 더욱 유의미한 연구 결과를 도출해 낼 수 있을 것이다.
더불어 본 연구의 대상이 되었던 화자들의 영어 능숙도를 평가함에 있어서 해당 코퍼스 자료를 통한 문장 능숙도 평가가 그들의 실제 영어 능숙도를 대표할 수 있을지에 관한 추가적인 분석이 필요하며 아울러 강세를 구성하는 요소인 음장 외에도 소리의 높이와 크기 역시 학습자의 영어 능숙도와 어떠한 상관관계가 있는지에 대한 가능성은 후속 과제의 일부로 남겨둔다.