





1. Introduction
In language acquisition, many studies have discussed that there are cross-linguistic influences between the first language (L1) and second language (L2) across the worlds’ languages. When adult language learners acquire L2, their L1 sound system affects the acquisition of the L2 sound system (L1→L2) and their L2 sound system can also affect L1 pronunciations (L2→L1) (Antoniou et al., 2011; Chang, 2012; Flege, 1995, 2002; Flege & Liu, 2001; Fowler et al., 2008; Grosjean, 1982; Sancier & Fowler, 1997).
Early studies focused on the influence of L1 on L2. L1-influenced L2 deviant forms are often called “foreign accent”, “interference”, or “transfer.” These forms are known to be hard to fix because the linguistic structures of L1 for adult learners are fossilized. While the L1 may cause some interference in adult acquisition of an L2, the L1 itself may not be affected (Guion et al., 2000).
The influences of L2 on L1 have received a lot of attention in recent studies (Chang, 2012; Herd et al., 2015; Pavlenko, 2000). Even when L2 learning takes place postpuberty, the second language phonology may affect that of the first language (Flege, 1987, 1995; Flege & Eefting, 1987; Major, 1992). In particular, Flege’s (1995: 239) Speech Learning Model (SLM) says, “phonetic categories established in childhood for L1 sounds evolve over the life span to reflect the properties of all L1 or L2 phones identified as a realization of each category.” His model suggests that the L1 system does not become static and invariable, but instead remains dynamic and ever-changing. Research indicates that acquiring an L2 can alter the L1 sound system called “phonetic drift”, phonological restructuring in the L1 during L2 acquisition. The term was first appeared in Sapir (1921) and recently discussed in Chang (2012).
Voice onset time (VOT) - an interval between the stop burst and the onset of vocal fold vibration - has long been used as a crucial acoustic cue to evaluate cross-linguistic influences between L1 and L2 (Fowler et al., 2008; Lisker & Abramson, 1964). Speakers’ native VOT can be affected by their L2 from non-native VOT, and vice versa. If there are some VOT changes in the L1 stop system as a result of acquiring L2, we may call it VOT drift, L2-influenced L1 change on VOT, corresponding to phonetic drift.
Speech production research on adult second-language learners has yielded mixed results regarding VOT drift (Chang, 2012; Guion et al., 2000; Herd et al., 2015; Kim, 2011, 2019). Early studies assumed that L2 experience could only influence once a high level of L2 proficiency had been reached (Flege, 1995; Fowler et al., 2008; Kim, 2011; Sancier & Fowler, 1997). These studies have been limited to advanced learners or bilinguals. Recently, Chang (2012) examined native English speakers enrolled in a six-week intensive Korean course in South Korea and reported significant changes in the VOT of participants’ English voiced stops. His results showed that the effect of L2 on L1 can be found by even brief experience. He suggested that VOT drift occurs early in language instruction but that it might stabilize during later stages of acquisition. More recently, Herd et al. (2015) also reported significant changes in the VOT of participants’ Spanish voiced stops even in L1-dominant environments. However, based on their findings of the speech productions of adult Quichua-Spanish bilinguals’ production of their L1 and L2 sentences, Guion et al. (2000) claimed that L2 learners’ L1 use influences their L2 production but not their L1 production. Furthermore, Kim (2019) reported that, for adult Korean learners of English with even long L2 exposure, VOT drift was not apparent in the stop system of L1 Korean. Therefore, it is not clear whether there is truly VOT drift.
Since Flege (1987), the length of residence in America (LOR) has been used as a good index for the amount of L2 input and a predictor of L2 acquisition for both children and adults. A number of studies have supported an effect of LOR on L2 performance: as LOR increases, L2 learners make more progress (Flege, 1987; Flege & Liu, 2001; Pavlenki, 2000; Purcell & Suter, 1980; Riney & Flege, 1998). Less attention has been given to VOT drift during adult speakers’ L2 learning as their LOR increases.
Since Lisker & Abramson (1964), VOT is an important acoustic correlate of voiceless/voiced contrast across languages. In languages like English, voiced stops /b, d, g/ are realized with either negative or positive VOTs and voiceless stops /p, t, k/ with long positive VOTs, or aspiration. In English, VOT is sufficient to be a primary cue to distinguish voiced from voiceless stops. In Korean, however, VOT does not serve well to separate the stop categories that are all voiceless. Early studies found that there was a VOT overlap between lax and tense stops (Han & Weitzman 1970; Kim, 1965; Lisker and& Abramson, 1964). Recent studies, however, reported VOT merger between lax and aspirated stops (Kang, 2014; Kim 2014, 2017, 2019; Oh, 2011, Silva, 2006, and among others). Instead of VOT, fundamental frequency (f0 or tone) has arisen as an important cue to distinguish lax from aspirated stops (Kim et al., 2002). The role of f0 has been confirmed from many phonetic findings (Cho, 1996; Kim, 2004; Lee et al., 2013; Silva, 2006).
Taken VOT and f0 into consideration together, Korean stops are being considered to be in the process of a sound change. It is referred to as a tonogenetic-like sound change or tonogenesis (Kang, 2014; Kim, 2000). For example, for the words ‘달’ /dal/ ‘moon’ and ‘탈’ /thal/ ‘daughter’, their VOT differences in ‘ㄷ’ and ‘ㅌ’ are getting decreased whereas their vocalic f0 differences are getting increased. This results in a tonal difference, L vs. H (i.e., ‘달’ [thàl] and ‘탈’ [thál]). Concerning tonogenesis in Korean, however, many issues still remain controversial. Since it is not the main concern of the present study, further discussion is skipped (see Kim & Duanmu, 2004).
The VOT shift for Korean stops is not static but varies according to various socio-phonetic factors such as age, gender, dialect, and L2 proficiency (Choi, 2002; Kim, 2011; Labov, 1994; Oh, 2011; Silva, 2006). With respect to age, younger speakers tend to show more VOT merger than older ones. Concerning gender, women tend to show more merger than men. Regarding dialects, Seoul speakers tend to show more merger than others. With respect to L2 proficiency, more proficient speakers tend show more merger than less proficient ones. Considering the factors together, young female Seoul speakers are the most active propagators in the sound change of the Korean stop system. However, even the above-mentioned factors controlled, there seems to be huge inter- and intra-speaker variations in VOT, suggesting that the Korean stops are not stable but still fluctuating (Kim, 2017). What still remains unclear is what the main cause of a sound change can be.
No one knows all the causes of linguistic change. Some sound changes result from assimilation, a fundamentally physiological process of ease of articulation (Labov, 2001; Ohala, 1993, 2012). Others, like the Great Vowel Shift and Tonogenesis, are more difficult to explain (Matisoff, 1973). One inquiry arises: can L2 as a source of language contact be the main cause of a sound change in the Korean stop system? Two research questions are: 1) Do Korean adult learners of L2 English produce L1 Korean stops differently in terms of LOR?; 2) Is there any relationship between L1 change and L2 acquisition? This experiment is designed to answer the questions by comparing three different groups in terms of LOR.
2. Method
In order to determine if the amount of experience with L2 English results in VOT drift in L1 Korean, Korean-speaking adult learners of English participated in this study. Thirty-nine participants were recruited in Korea or America and divided them into three groups in term of LOR: no LOR (0 year), short LOR (under 1.5 years), and long LOR (over 3 years) (cf. Flege & Liu, 2001). All participants were born in Seoul, Korea. They used the standard dialect of Korean as their native language and learned English as a foreign language (EFL). They mostly consisted students at a university. The mean age of participants was 27.6 years.
The no LOR group, employed as a control group, consisted of thirteen participants (N=13; 6 men and 7 women) who had never been abroad and had not received any formal education in English-speaking countries. Their mean age was 25.4 (range 18−32). They were recruited at a university in Seoul, Korea. They all went through the Korean school system up to high school in Korea. They had learned EFL since elementary or middle school. They were evaluated as pure monolinguals or novice learners in L2 English. The short LOR group consisted of thirteen participants (N=13; 5 men and 8 women) and recruited in the western part of the US. The mean age was 32.5 (range 20.6−37.2). They had resided in America for less than 1.5 years. They used Korean on a daily basis and used English an average of 3 hours per day. The long LOR group consisted of thirteen participants (N=13, 6 men and 7 women) who had resided for more than three to ten years. They were also recruited in the western part of the US. They had Korean as their native language, went through either the Korean school system and/or the English school system in Korea or the US, and used both Korean and English on a daily basis at necessary. The mean self-estimated percentage daily use of English was 78%. Their US arrival was between the age of 16 and 21 years. The mean age was 23.7 (range 20.5−33.6). All participants were compensated $10 or 10,000 won per hour for their participation. No speaker had any history of speech pathology or phonetic training.
For a comparative purpose, the same stimuli as in Kim (2019) were used. Eighteen monosyllabic words (3 stops×3 places×2 syllable types) were constructed from a balanced list of the three stop types (lax, aspirated, and tense) and the three places of articulations (labial, alveolar, and velar) followed by a vowel /a/ context. The syllable type was either CV or CVC where the final coda was an unreleased stop [t] or [k]. All words were real words in Korean.
VOT was measured from the release burst of a stop to the onset of periodicity in the waveform (Lisker & Abramson, 1964). The onset of voicing (=vowel onset) was defined as the first and periodic pulse of a vocalic waveform that show features typical of a vowel. The onset of the voicing energy in the second formant shown in a time-locked spectrogram was used to help determine voicing onset in conjunction with the waveform.
Participants completed a brief language background questionnaire and were shortly interviewed. They were recorded by reading a word list four times in the carrier sentence [igǝ ______ hasɛjo] “Say this ______” where the words were located in phrase-initial position. In the position, the target words were expected to be fully stressed and emphasized. Speech materials were presented in Hangul, the writing system of Korean.
Recordings were done in either Korea or America. In Korea, recordings were done in a quiet office directly into a Samsung SENS NT900XC4C-A78 laptop computer using a Safa voice recorder (model SR-M190N). In the US, recordings were made in a sound-attenuated booth in the Phonetics Lab using a Shure (model SM 10A) head-mounted microphone. Recordings were saved on a flash card using a Marantz digital recorder (PMD 670) at a sampling rate of 44.1 kHz. Each speaker was asked to read the words on the monitor in a natural intonation. The monitor connected to the computer was inside the lab but the computer itself was outside the lab to minimize background noise. The words were automatically popped up at a 3-second interval. This makes speech rate controlled by using the frame sentence and limiting the speakers’ production time of sentences to a fixed 3 sec. A total of 2,808 tokens (18 words×39 speakers×4 repetitions) excluding 312 filler words were obtained for analysis. All utterances were analysed using Praat 6.0.37, a speech analysis program (Boersma & Weenink, 2018).
The acoustic data obtained were statistically tested using repeated measures analysis of variance (RM ANOVA) in the context of a univariate context of a general linear model (SPSS/PASW, 2018). The main goal of the present study was to examine whether there was any main effect of LOR (i.e., group), stop (i.e., aspirated, lax, and tense), place (i.e., labial, alveolar, and velar), gender (i.e., male vs. female), and individual speakers on VOT, and whether there was any interaction effect between factors. Repeated measures ANOVA includes both “between” subjects effects (LOR group and gender) and “within” subject effects (i.e., stop and place). Their main and interaction effects were statistically analyzed at a 0.05 significant level. Post hoc tests were also run to answer the following questions: (i) whether any differences in pairs among three groups and stops were significant and (ii) whether any differences in stop pairs among individual speakers were significant. For statistical analysis, effects of LOR, stop, place, and gender on VOT in the production of Korean stops were mainly focused because of most central interest in this paper.
3. Results
Figure 1 represents the group-normative results by stop and group. There seems to be little effect of LOR on VOT because the bar graphs averaged across each group are very similar for stop production.
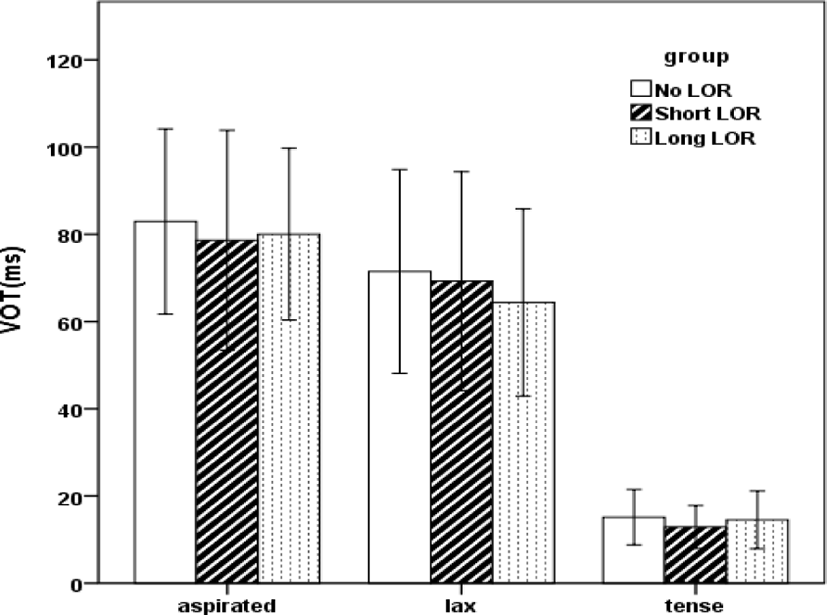
Unlike what was shown in Figure 1, the statistic results of univariate repeated measures (RM) ANOVA showed a main effect of LOR on VOT [F(2, 2799)=9.437, p<0.001] and also an interaction between stop and LOR on VOT [F(4, 2788)=3.799, p=.004]. Post hoc Tukey HSD multiple comparisons revealed that differences in the No-Short LOR and No-Long LOR pairs were statistically significant (p<.001) but differences in the Short-Long LOR pairs was not (NE<LE=HE). The mean VOT values of each stop by the group showes a huge overlap VOTs in the range between aspirated and lax stops, as presented in Table 1. For each stop, the group differences on VOT are not very big.
In order to determine if Korean stops varied with LOR, one-way ANOVAs were run on the VOT of each stop with group (i.e., LOR) as a between-subject factor. If there are significant differences among the groups, we can expect that speakers’ production of L1 stops can be influenced by the amount of L2 exposure (i.e., VOT drift). For the aspirated stop, no group differences were statistically significant (p>0.05). However, the groups differed significantly in their production of the lax stop [F(2, 933)=7.631, p=.001] and the tense stop [F(2, 933)=11.870, p=.001]. Post hoc Tukey HSD determined that, for the lax stop, differences in the No-Long and Short-Long LOR pairs were statistically significant (p<.005) and for the tense stop, differences in the No-Short LOR and Short-Long LOR pairs were statistically significant (p<.005). Pairwise comparisons revealed that the group differences were not consistent.
The mean VOT differences between the groups are very small for each stop; from Table 1, 1 to 2 ms difference for both the tense and aspirated stop and 3 to 7 ms difference for the lax stop. The mean VOT difference between the aspirated and the lax stop was approximately 11 ms for the no LOR group, 10 ms for the short LOR group, and 16 ms for the long LOR group. The results indicate that, regardless of LOR, Korean stops are undergoing a VOT merger between the two stops.
The current findings suggest that VOT in L1 Korean stops is not influenced by L2 English. That is, there is little VOT drift (L2-influenced L1 change on VOT) in Korean stops. It is important to note that, although there are some significant outcomes in statistics, they are not always linguistically important. As clearly seen in Figure 1 along with Table 1, regardless of different LOR, Korean adult learners of L2 English produced the three stops in a similar way. Thus, we can say that effect of LOR on VOT can be marginal in the production of L1 Korean stops.
Unlike the effect of LOR on VOT, effects of stop, place, and gender on VOT were robust. The effects held well for all groups, as reported in previous studies. For the group-normative data, the results of univariate repeated measures (RM) ANOVA showed a main effect of stop on VOT [F(2, 2,754)=4,026.250, p<.0001] in that mean VOT values were longest (80.5 ms) for the aspirated, longer (68.4 ms) for the lax, and shortest (14.2 ms) for the tense stop (tense<lax<aspirated). There was an interaction between stop and place and also an interaction between stop and gender on VOT (p<0.01). Figure 2 illustrates mean VOTs of the three phonation types averaged across a total of 2,808 tokens together across the groups.
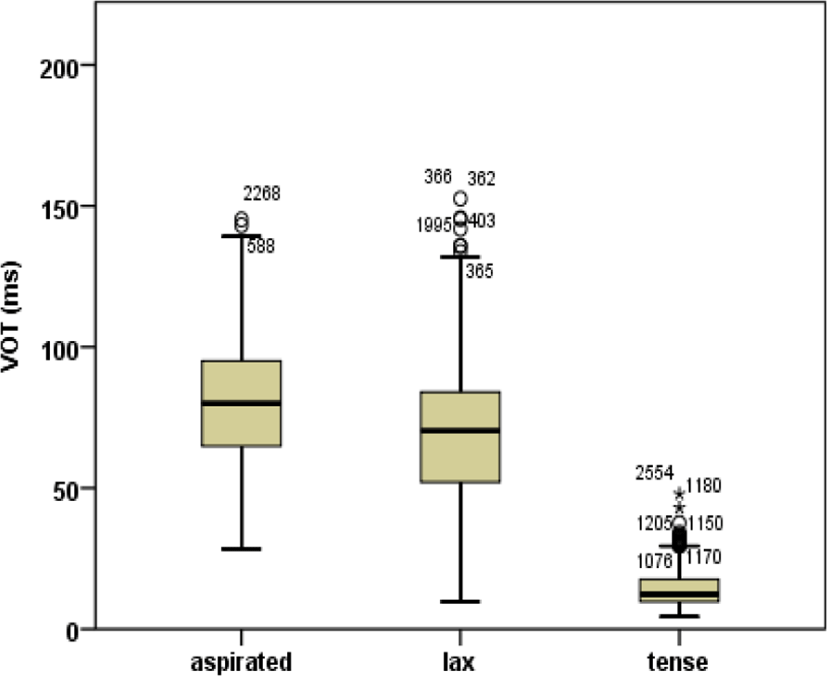
Unlike what was shown in Figure 2, post hoc Tukey HSD comparisons revealed that differences in each pair among the three stop types were statistically significant (p<.001). The statistical outcomes averaged across 2,808 tokens suggest that VOT can still distinguish aspirated from lax stops. However, the range between lax (9-153 ms) and aspirated (28-145 ms) stops were overwhelmingly overlapped, as can be clearly seen in Figure 2. The mean VOT difference between the aspirated and lax stop was only about 13 ms. This corresponds to recent findings of Kang (2014), Kim (2014, 2017, 2019) and Silva (2006) but does not correspond to early findings as in Lisker & Abramson (1964). Compared with Lisker & Abramson’s study where the VOT difference between the aspirated and lax stop was about 73 ms, the difference in this study is incomparably short (13 ms). The findings of the present study strongly support the aspirated-lax merger on VOT as evidence of sound change.
Figure 3 illustrated mean VOTs of the three stops in terms of the three places of articulation.
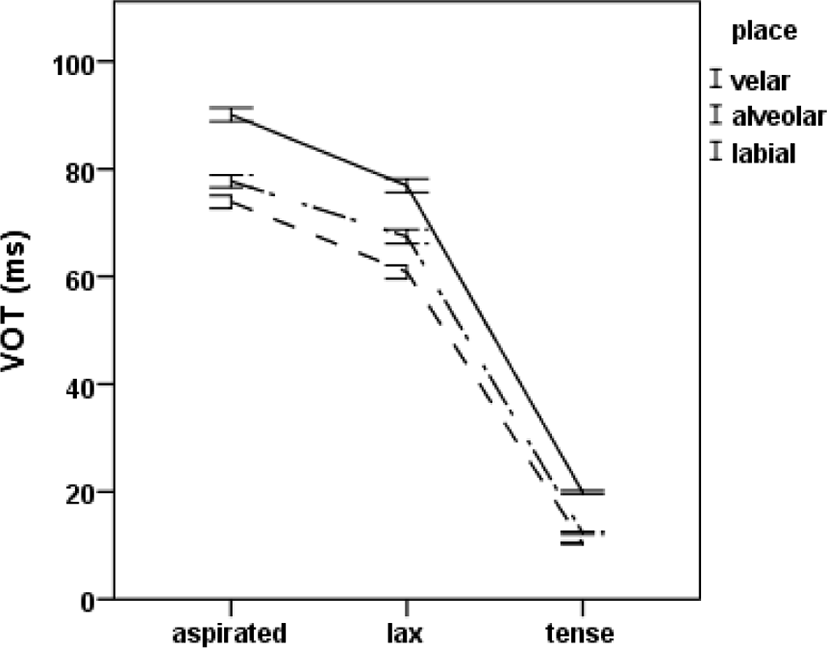
As expected, there was a main effect of place of articulation on VOT [F(2, 2,754)=162.634, p<.0001] in that mean VOTs were shortest (48.4 ms) for labials, longer (52.5 ms) for alveolars, and longest (62.3 ms) for velars (labials<alveolars<velars). This corresponds to previous findings (Lisker & Abramson, 1964 and many others). Pairwise comparisons revealed that differences in each pair among the three places were statistically significant (p<.001). The effect of place of articulation on VOT held well for each stop, as can be seen in Figure 3. There was an interaction between stop and place of articulation [F(4, 2754)=4.832, p=.001].
As can be seen in Figure 4, there was an effect of gender on VOT [F(1, 2754)=25.615, p<.0001] in that mean VOTs for aspirated stops were significantly longer for male speakers (86 ms) than female speakers (76 ms). There was also an interaction between stop and gender [F(2, 2754)=30.453, p<.0001]. The VOT values of stop, place, and gender are presented in Table 2.
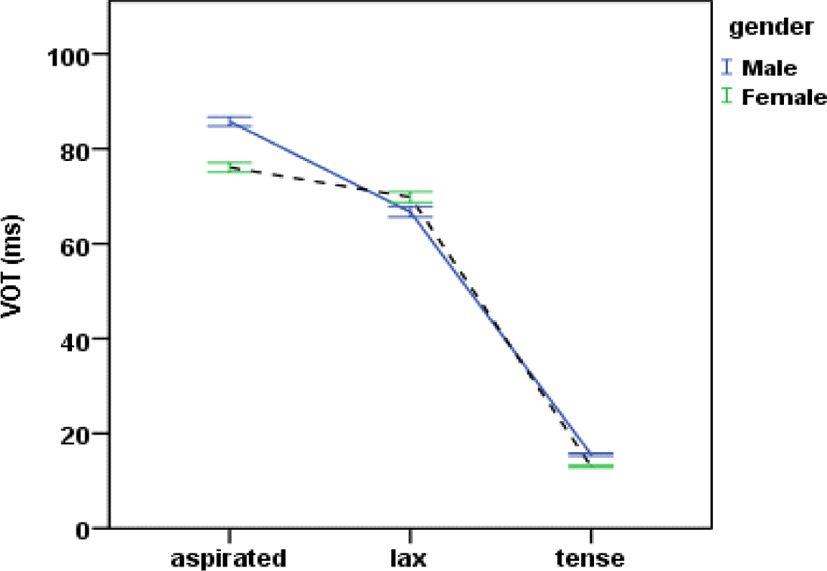
In Table 2, with respect to VOT, the differences between the aspirated and lax stop are much smaller for female speakers than male speakers (7 ms vs. 20 ms). The results support the previous findings that women have more VOT merger than men (Kim, 2017; Oh, 2011). Post hoc Tukey HSD tests revealed that, for most of female speakers, there were statistically two subsets (tense< lax=aspirated) whereas, for most of male speakers, there were three statistical subsets (tense<lax<aspirated) (see Appendix 1). There was neither interaction between gender and place nor any 3-way interactions among stop, gender, and place of articulation (p >.05).
Overall, the group-normative data showed that, despite systematic mean differences among the three stops in statistics, VOT differences between lax and aspirated stops largely decreased toward the merger of the two stops. Tense stops were distinguished well from either aspirated or lax stops. All of them were consistently realized with short-lag voicing where their mean VOT was 14.1 ms in the range between 10 ms and 15 ms. In contrast, both aspirated and lax stops were not stable. Aspirated stops were not distinguished well from lax stops because they both were realized with relatively long-lag voicing. The mean VOT of the aspirated stop was 81 ms in the range between 28 ms and 145 ms. The mean VOT of the lax stop was 68 ms in the range between 9 ms and 153 ms. There was an apparent VOT merger in their range between aspirated and lax stops. With respect to the VOT merger as evidence of sound change, the current findings correspond to previous ones (Kang, 2014; Kim, 2019; Lee et al., 2013; Oh, 2011; Silva, 2006).
Much research has focused on group-normative effects, that is, effects that are representative of the population as a whole. If we consider individuals’ results, there may be remarkable speaker variations in terms of VOT (Kim, 2017). Let us consider how Korean adult learners of L2 English produce stops according to the different groups of LOR.
Statistical analysis confirmed significant differences among speakers [F(38, 2691)=59.655, p<.0001] and an interaction between stop and individual [F(76, 2691)=22.724, p<.05] in that individual speakers produced the three stops differently in terms of VOT. Individual speaker’s mean VOTs of the three stops with ranges, standard deviations, and statistical subsets are provided in Appendix 1. Taking Figure 5 and Appendix 1 into consideration together, while tense stops were consistently produced with short-lag VOTs, there were huge speaker variability in the production of both aspirated and lax stops. As can be clearly seen in Figure 5, individuals’ VOT patterns on stop production are not stable in terms of LOR.
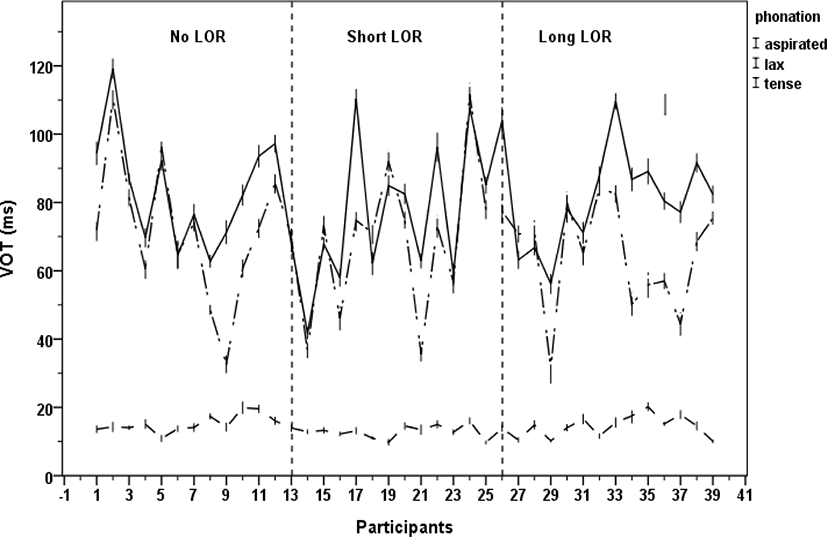
Let us consider in detail how individuals produced aspirated and lax stops differently. Their productions could divide into two groups; one for those who did not undergo VOT merger and the other for those who did undergo it (Appendix 1). Out of 39, 18 speakers statistically maintained a three-way subset, while the others did not. Out of 18, 15 consisted of male speakers. For these speakers, VOT might be an important acoustic cue to distinguish lax from aspirated stops. Although they showed three statistical subsets, however, their stops were also shown to be undergoing a change. Out of 18 speakers, three speakers produced aspirated stops with about 70 ms-long VOTs and nine speakers produced lax stops with about 70 ms-long VOTs. Taking mean VOTs of Lisker & Abramson (1964) as a reference point (Masp=103 ms and Mlax=30 ms) into consideration, their aspirated stops became shorter, while their lax stops became longer. This tells that their stops were somewhat in the process of changing.
Except for 18 described above, the rest 22 participants showed a two-way statistical subset because of the VOT merger. That is, their stops underwent VOT shift. Some speakers produced aspirated stops with primarily long-lag VOTs (>80 ms) and lax stops also with long-lag VOTs (>80 ms), indicating that these speakers underwent a lax-lengthening process toward the VOT merger. Others produced aspirated stops with primarily short-lag VOTs (<60 ms) and lax stops also with short-lag VOTs (>60 ms), indicating that these speakers underwent an aspirated-shortening process toward the VOT merger. Individuals’ patterns differed in that some speakers changed only one stop and others changed two stops both.
There is an issue on which stops undergo sound change. Some studies report that aspirated stops only undergo a change (Kang, 2014; Silva, 2006), while other studies report that aspirated and lax stops both undergo a change (2017, 2019). It is worth noting that much attention has been given to the change of the aspirated stop, while less attention has been given to the change of the lax category. Most of studies discuss that, among the three stops in Korean, change in VOT affects only aspirated stops (i.e., VOT reduction from aspirated stops) (Kang, 2014; Silva, 2006). Recently, Kim (2017, 2019) showed that lax stops also underwent a VOT change by getting longer than early findings and claimed that they played an important role in a tonogenetic-like sound change. The present findings correspond to Kim’s in that not only aspirated but also lax stops underwent changes in VOT.
When considering individuals’ productions, the process seems to occur in either bi-directional or uni-directional. For aspirated stops, 34 out of 39 participants underwent a shortening process (<103 ms). There were only five participants whose VOTs were over 100 ms, six from 90 ms to 99 ms, ten from 80 ms to 89 ms, and the rest 19 participants under 80 ms, indicating that, for most of participants, VOTs in the present study were mean 20 ms shorter than those in Lisker & Abramson (1964). For lax stops, the lengthening processes (>30 ms) were more frequent than the shortening ones. All participants but a few underwent a lengthening process. There were only four participants whose VOTs were around 30 ms and the rest were all over 40 ms. Very interestingly, two participants produced lax stops with approximately 100 ms-long VOTs, and 21 speakers with 70 to 99 ms-long VOTs, indicating that, for most of participants, their lax VOTs were much longer than those in Lisker & Abramson (1964). Surprisingly enough, eight speakers (5, 13, 15, 19, 24, 27, 28, 30) produced lax stops even longer VOTs than aspirated stops. The results clearly support that lax stops can also be undergoing a change.
Regarding the aspirated-lax merger for each individual, pairwise comparisons showed that, out of 39, 21 participants significantly show the merger in statistics (see Appendix 1). Out of 21, 18 consisted of female speakers. Remarkable inter-speaker variations on the merger showed some gender dependency. Similar to Oh’s (2011) and Kim’s (2014, 2017, 2019) findings, female speakers showed more merger than male speakers. Almost all female speakers but four had the merger. In contrast, the exactly opposite pattern was found for male speakers. Our data support Labov’s (1994, 2001) assumption that, if socio-phonetic factors are working well, young female speakers are leaders in sound change. That is, women rather than men play a leading and active role in sound change. They are often called “innovative” propagators. For the stop production of female speech in this study, both lax and aspirated stops were produced with long-lag VOTs and were grouped in the same statistical subset.
There were also intra-speaker differences within the same gender. Let us compare the results of speaker 23 with those of speaker 24. They both were male speakers (same gender), in their twenties (23 vs. 20), and they grew up in Seoul (same dialect). In addition, they had lived in the USA for no more than 2 months (same LOR). In spite of the socio-phonetic factors controlled, their VOT values for aspirated and lax stops were remarkably different in terms of VOT. Speaker 24’s VOT values for both aspirated and lax stops were twice as long as those of speaker 23 (Masp=108 ms and Mlax=112 ms vs. Masp=59 ms and Mlax=57 ms). However, they both statistically showed the complete merger. This was because speaker 24 underwent a lengthening process for lax stops, while speaker 23 underwent a shortening process for aspirated stops. Whatever they developed, either way resulted in a merger.
Considering all the individual data, speaker variability is shown to be spectacular. The within-speaker variability in gender appears to be high. Note that speakers employed in the present study were from the same Seoul dialects and the same generations in their twenties and thirties. In addition, their speech rate was also controlled. Despite the fact that such socio-phonetic factors as age, gender, dialect, L2 exposure, and even speech rate were controlled, there was huge inter-speaker and intra-speaker variability on the merger and duration on VOT, indicating that a synchronous speech sound change is still ongoing in Korean stops.
4. Discussion
This study investigated effects of LOR on VOT in L1 Korean stops by recruiting different groups of Korean adult learners of L2 English. The purpose of this study was to determine if adult language learners of English exhibit VOT drift in the same way as bilinguals or advanced learners acquiring an additional language in an L2-dominant environment. In particular, the study addressed the possible relationship between L1 change and L2 acquisition.
The results showed that L1 Korean stops were not differently produced between groups in terms of VOT. Regardless of LOR, Korean adult learners of L2 English produced their stops in a similar pattern. This indicates that LOR’s effect on VOT was very small in the production of Korean stops. In contrast, the effect of sound change on VOT was very big. VOT merger as evidence of sound change in Korean stops were significantly found for most of female speakers across the groups. The results suggest that there is little relationship between L1 change and L2 acquisition. In addition, L2 English may not be the main cause of sound change in L1 Korean.
The new findings of the present study are summarized as follows; First, Korean stops are truly undergoing a sound change. Although they were statistically different in terms of VOT: longest (81 ms) for the aspirated, longer (68 ms) for the lax, and shortest (14 ms) for the tense stop, there was much overlap between lax and aspirated stops in their ranges. Second, the change takes place in aspirated and lax stops together: aspirated stops are getting shorter, while lax stops are getting longer. However, some individuals showed slightly different patterns on VOT. Third, the change in L1 is not closely related to L2 acquisition. Regardless of the amount of L2 exposure, I.e., LOR, Korean stops are in the process of changing VOTs. That is, the change in VOT is not affected by L2 English. Fourth, the change is more significantly found in women than in men. Compared with female speakers, the three-way contrast was still maintained by most of male speakers who were known to be very conservative in sound change. Fifth, the change showed huge inter- and intra-speaker variability. Some individuals showed the merger, while others did not. Overall, the present results suggest that Korean stops are still undergoing a sound change and the change is not mainly by external factors such as language contact and social factors but by internal factors referred to as a tonogenetic-like sound change.
The findings of the present study provide a counter-evidence to the claim that L1 can be affected by the learning of an L2 or LOR and there are cross-linguistic influences between L1 and L2 (Chang, 2012; Flege, 1995; Fowler et al., 2008). Specifically, the present findings does not support previous ones (Chang, 2012; Herd et al. 2015; Kim 2011) that L1 is affected by L2 learning. Unlike their findings, the present results did not show any VOT drift due to LOR. Thus, we can conclude that VOT drift, L2-influenced L1 change, is not obvious.
The findings of the present study has a couple of implications. First, the cross-linguistic influences between L1 and L2 are asymmetrical. The influence of L1 on L2 is more robust than the influence of L2 on L1. Second, the influence of L2 on L1 does not always hold for advanced learners or bilinguals. From our data, a male speaker, almost a bilingual, with a 10-year LOR exhibited the most conservative three-way contrast in VOT among all participants (tense 10 ms<lax 82 ms<aspirated 110 ms). Although his mean VOT values for the lax category were much longer than early findings (82 ms vs. 30 ms) in Lisker & Abramson (1964), he clearly kept a traditional three-way pattern of stops in VOT.
The present study makes some important contributions. First, this study shows that the sound change of the Korean stop system takes place not only among Koreans in Seoul, but also among people residing in the United States. Second, it is the first to show whether English is affected by a learner’s residency. Third, this study presents a systematic and quantitative phonetic study on a large scale of Korean stop production(2,808 token total). Finally, it is the first to show that L2 English and L1 sound change are not directly related to each other.
In conclusion, there are little effects of LOR on VOT in the production of L1 Korean stops. The VOT merger as evidence of a sound change in Korean stop are predominantly shown for women across the groups. All languages change through time, but how they change, what drives these changes, and what kinds of changes we can expect are not always obvious. It is well-attested that Korean is undergoing a sound change in that tonal differences are being replaced by VOT differences to distinguish lax from aspirated stops. What remains still unclear is what the main cause of a sound change is and how the sound change can be accounted for. Kim & Duanmu (2004) suggest that the Korean case can be accounted for in terms of standard tonogenesis (voiced-L vs. voiceless-H, Martisoff, 1973). Regarding a tonogenetic-like sound change, however, many issues remain controversial. Further study is necessary to see solve the issues.