





1. Introduction
This paper examines Korean EFL listeners' phonetic difficulties based on self-paced passage dictation tasks. Listening is considered a difficult skill to learn, because underlying speech sounds are modified in connected speech through various phonological processes such as linking, reduction and elision (Johnson, 2004). Due to the differences between spoken and written language, English learners often mishear what they can understand in written forms, displaying a gap between listening and reading proficiencies. The purpose of this study is to provide a quantitative and comprehensive analysis of L2 listeners' listening difficulties in single vs. multi words and in different word categories, content vs. function words.
Hwang (2004) studied listening difficulties with two different levels of text and English proficiency in high school students. Students listened to a spoken text, verbally described what they heard, and then reflected on and wrote down any difficulties they encountered in listening. She found that listening difficulties predominantly involved non-recognition of sequences of words.
That is, listeners identified only a few words from a long phrase. For example, only leg is heard in “.. its short legs and clumsy looking”. The error rate in word-sequence recognition was significantly higher in less proficient learners than more proficient learners. Low-proficiency learners also showed higher error rate in mishearing a word (e.g., bat heard as back). Errors in phonetic decoding ('non-recognition') were more common than errors of other types, e.g., understanding meaning of a word that is correctly heard ('non-grasp') (p. 288). In other words, learners may miss the words that they can easily understand in written forms. Based on these results, she suggests that predominant listening difficulty is phonetic perception, so developing basic decoding skills is important (p. 294). Phonetically-accurate perception is the most important element in order to improve one's listening proficiency.
Choung (2014) also highlighted the difficulties and importance of aural perception practice in her study of high school students' listening strategy. Among various listening strategies, including metacognitive and affective ones, the students felt that phonetic perception practice (such as listening to British English and linked sounds) is the most effective and facilitate the use of other metacognitive strategies.
What makes spoken English harder to understand is connected-speech phenomena such as linking, elision, contraction, and reduced forms. Linking has been identified as a phonetic obstacle that hinders listening comprehension (Choung, 2014; Hagiwara & Kuzumaki, 1982; Jeong & Koo, 2017). Function words are usually monosyllables, so when they undergo linking (e.g., make a [meɪkə]), they can sound like a part of the preceding word. Moreover, function words easily undergo reduction and elision due to their lack of stress. Reduced vowels have lower intensity and shorter duration, which makes them particularly more difficult to perceive than content words. In Kang (2017), the subjects showed higher error rate in function words than in content words. In Hagiwara & Kuzumaki (1982), in dictation data by Japanese learners of English, high frequency errors involved function words: demonstrative that (in go to that restaurant) was misheard as the, auxiliary will was omitted, article a was omitted, and past suffixes were frequently omitted (e.g., listened to is misheard as listen to).
Dictation is a common way of assessing listening difficulties of L2 learners. In dictation tasks, students are asked to write down full sentences or fill in the blanks (Chang & Chang, 2014). Test sentences are usually played to the subjects a limited number of times. Researchers often pre-determine target phonological processes and include them in test words and phrases. For example, Kang (2017) constructed 7 sentences for dictation task, which are designed to include function words (preposition, pronoun, conjunction), played three times to the students. Jeong & Koo (2017) adapted 27 sentences from a TOEIC practice book containing various phonological processes that hinders aural perception, such as linking, assimilation, elision, and weak forms. Listeners showed highest error rates in vowel-vowel linking, progressive assimilation, and consonant-vowel linking.
Another way of collecting listening errors is through the observation of relatively larger-scale dictation, without hand-picking difficult sounds or phonological processes beforehand. Kim (2002) gave dictation assignments to graduate students of interpretation major with high-intermediate to advanced English proficiency. The materials were TV news broadcast of about 20 minutes, assigned each week. In the transcriptions, he observed many errors in function words, though quantitative information was not provided. Due to the process of contraction and reduction, function words are easily missed (They should have done this is transcribed as They _this), or misheard (to win the race is transcribed as the window racer a). His work focused more on illustrating errors in content words and phrases on the ground that difficulties of function words are evident. He classified the error phrases by word position (initial, mid, final in word), wrong syllabification (was hit misheard as with it), wrong separation (consider misheard as can see a), and fusing (wrongly combined words, to read misheard as tree). However, quantitative analyses are not given, and content words and function words are not fully separately analyzed.
Yang & Kang (2020) attempted to find out a full range of listening error types from a self-annotated transcription task that they developed. They used 50 short sentences (ten sentences×five assignments) selected from a TOEFL practice book. Students were asked to transcribe English sentences and then mark the parts where they had problems and describe them. From the transcription data by 19 students, they reported six error types: substitution (floral for floor), wrong segmentation (to wishin for tuition), wrong merge (ferries for fare), omission (absent-mind for absent-minded), insertion (days for day), spelling and blank (p. 41). However, while this way of classifying errors shows what happened to the difficult sounds, it does not directly reveal what are the sounds that are difficult to listen.
The present study also aims to discover learners' common errors in a full range, but unlike Yang & Kang (2020), classifies the error types based on length (one word or a word sequence) and type of words (function word or content word). In addition, instead of constructing sentences to contain some particular phonological processes, students are asked to transcribe a whole passage, so that an overall picture of difficulties can be captured. Most dictation tasks have been carried out at word or phrase level (fill-in-the-blanks) or sentence level. Research based on whole-phrase dictation by Korean EFL learners is not much found in the literature, except Kang (2017).
The transcription data collected from whole-passage dictation tasks may serve as a learner corpus. It is generally known that corpora allow research based on real-world data, rather than experimental settings. Learner corpora, consisting of L2 learner output, can contribute not only to study of characteristics of L2 learners' language, but also to development of a computer-assisted language learning system (CALL) (Kotani & Yoshimi, 2015). Listening corpora, consisting of EFL learners' response to spoken data, have been relatively rare (Kotani & Yoshimi, 2015). The L2 listening corpus created by Kotani & Yoshimi (2015) consists of two components, phonetic recognition and comprehension, including text data transcribed from a dictation exercise.
In the present study, students are allowed to play, pause, and repeat the assigned audio files as much as they want. This will help release psychological obstacles such as attention, working memory and anxiety problems (Choung, 2014; Hwang, 2004; Rubin, 1994; Yang & Kang, 2020) that can arise during listening to materials just once or a few limited number of times. This way we can tease apart phonetic difficulties from psychological obstacles, and identify phonetic problems separately. A drawback is that it is different from usual real-life listening or language-test situations (Voss, 1984).
This paper is organized as follows: Section 2 explains the research method. Section 3 presents the results describing listening errors in terms of the number of connected words, function vs. content words, suffix errors, and errors in word sequences. Section 4 is discussion and conclusion.
2. Research method
Subjects were 55 Korean students (26 male, 29 female) who enrolled in TOEIC Listening course in a university. Of these students, 39 students have taken a TOEIC test and their score average is 795 and the median is 749. This corresponds to the English proficiency level of intermediate to high intermediate.
Listening materials were four TOEIC passages, two conversations and two telephone messages, from a TOEIC textbook (ETS, 2018). The instructor assigns a passage for dictation each week for four weeks (total 4 passages). The details are given in Table 1.
The total word count is 432, consisting of 215 content words (50%) and 218 function words (50%). Mean duration of the audio files was 33.5 seconds. Contracted words were treated as two words (UCLES, 2021). In the fourth column, WPM is speech rate (word per minute) (mean of 171). In total, there were 433 words (47 sentences) in four passages. For each passage, 52, 51, 51, and 50 students submitted their dictation homework. This makes the total number of targeted words 22,111 (the number of students×word count for each passage) (10,971 content words, 11,140 function words) and the number of sentences 2,399 (the number of students× sentence count for each passage) to be analyzed.
In addition, among the content words, there were a total of 24 inflectional suffix instances (14 plural, 6 third-person singular, 4 regular past-tense suffixes) in the listening materials. Multiplied by the number of students, the total number of targeted suffixes is 1,230.
Text complexity was measured using the ATOS text analyzer1, which calculates the readability level for short text passages. The results are shown in Table 2.
| Passages | 1 | 2 | 3 | 4 | All |
|---|---|---|---|---|---|
| ATOS level | 4.4 | 3.8 | 5.9 | 6.0 | 4.8 |
| Average word length | 4.4 | 4 | 4.5 | 4.4 | 4.3 |
| Average sentence length | 7.8 | 7.8 | 11.2 | 11 | 9.4 |
| Average vocabulary level | 2.43 | 2.6 | 3 | 2.9 | 2.9 |
According to this, ATOS readability level, average sentence length, and average vocabulary level were higher in passages 3 and 4 (telephone messages) than passages 1 and 2 (conversations). Average word length was similar in all passages.
Subjects were asked to transcribe a passage once a week for four consecutive weeks as homework. They were allowed to listen to the passage as much as they needed, and asked to write down the passage with a pencil as accurately as they can. They were instructed to stop the audio wherever they can write what they heard as a chunk. After completing dictation, they compared their own passage with the answer script given in their textbook and corrected errors using a color pen, and wrote down unknown vocabularies. After finishing the corrections, they took a picture of their passage and submit it through the online learning management system. Students were given participation points, but not evaluated by their performance in dictation. The researcher collected the submitted pictures and manually entered errors in an Excel spreadsheet. R Studio (version 1.3.959; RStudio Team, 2020) was used for statistical analyses.
The present research focuses on length of word sequences and types of words where errors occur. Thus, error words were first classified into the number of word sequences (single word, word sequences), and then single-word errors were further classified into content words, function words, and suffixes. Among the error types, I examined only substitution and omission errors. Insertion errors (e.g., back as backs) are not analyzed, because they account for only a small portion of the errors (5% of all the errors) (cf. the insertion error rate was 4.5% in Yang & Kang [2020]). Spelling errors, considered unrelated to listening, were ignored (cf. Hagiwara & Kuzumaki, 1982).
3. Results
A total of 970 error words and word sequences were identified from students' passage dictation. Excluding 51 insertion errors, 919 errors were analyzed. This includes 710 single-word errors and 209 word-sequence errors. Single-word errors mean substitution or omission errors in a single word, where immediately adjacent words are correctly heard. Word-sequence errors mean a sequence of words where errors are found in all the connected words. For example, when “these sorts of” is misheard as “these all to”, it is considered as one word-sequence error with two (not three) connected error-words. In other words, the single word or word sequence criterion is the number of words where errors occur consecutively.
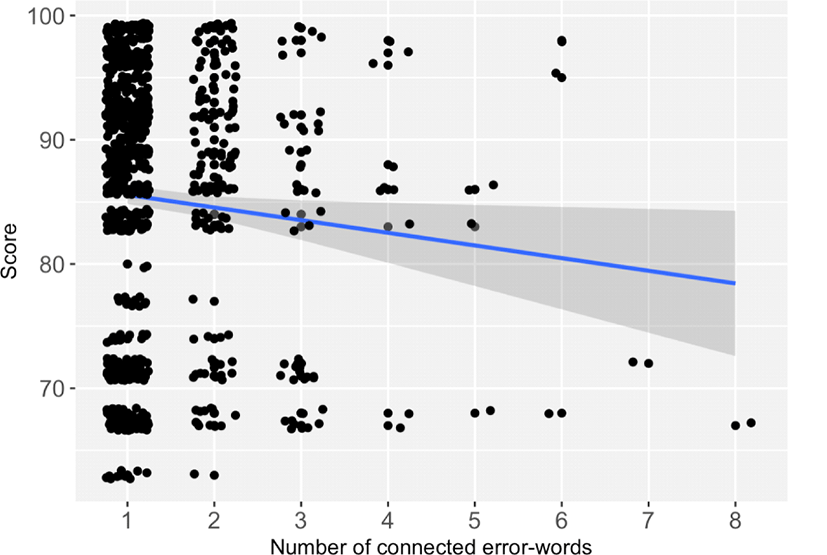
It can be expected that low-proficiency learners will have a greater difficulty in understanding longer phrases than single words. To examine for this, the number of connected error-words was compared with students' scores (mean of midterm and final exam test scores). Figure 1 shows the number of connected words plotted against the students' scores. R function jitter was used to avoid overplotting. A linear regression was performed with number of connected error-words as the independent variable, and scores as the dependent variable. As the number of connected words increases, students' scores tend to decrease significantly (t(917)=–2.29, p<0.05). This indicates that low proficiency learners tend to miss longer phrases than high proficiency learners. In particular, it can be noted that high-score students (above 80) are mostly found in the upper-left corner of the plot. This indicates that high-proficiency learners are most likely to miss just one word, or two subsequent words. This result conforms to Hwang (2004: 288) where low proficiency learners showed a higher error rate in word sequences than high proficiency learners.
Single-word errors were classified further into errors in content words (CT), function words (FN), and suffixes (SF). Table 3 shows the frequency of errors in each category. The second column is the raw count of errors and the third column is the percentage of errors relative to the total number of single-word errors (710). The last column shows the percentage of errors relative to the number of all words or suffixes in each category. Figure 2 shows the errors relative to the total number of words in each class.
| Class | Raw count | % in total errors | % in the category (total number) |
|---|---|---|---|
| Content words | 172 | 24 | 1.6 (10,971) |
| Function words | 471 | 66 | 4.2 (11,140) |
| Suffix | 67 | 9 | 5.4 (1,230) |
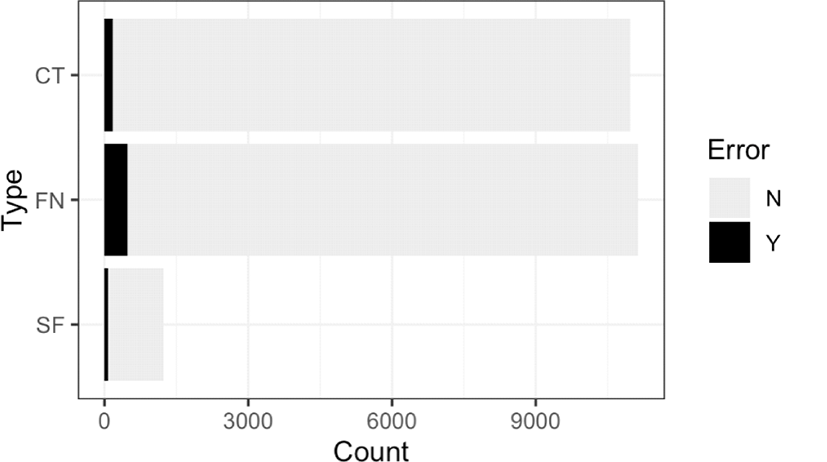
Table 3 and Figure 2 show that the error rate is higher in function words than content words, in both raw absolute and relative frequencies. This is a similar result to Kang (2017). In college students' listening tasks in Kang (2017), function words showed error rate of 50%–58%, compared to 25%–29% of content words. These rates are similar to the current result, but here function words show a higher error-rate (66%) and content words show a lower error-rate (24%) than Kang (2017), so a greater difference is found. The relative frequencies in the last column confirm this finding: function word errors are more frequent than content word words. Table 2 also shows that suffix errors account for 9% of the total errors. However, in terms of the relative frequencies (in the last column), suffix errors are the most frequent2.
Figure 3 shows score distribution in each category. Content words have a lower median (the vertical line) than function words. This means that content words posed more difficulties in lower-proficiency learners than in high-proficiency learners. This may indicate that low-proficiency learners have less vocabulary knowledge than high-proficiency learners. A linear regression was conducted with word class as the independent variable, and scores as the dependent variable. The results show that the difference is statistically significant. The scores in content vs. function words are significantly different from each other (t(916)=3.43, p<0.001). Score is significantly higher by 3.1 in function words. Content words and suffix errors are not significantly different from each other (t(916)=1.21, p=0.2).
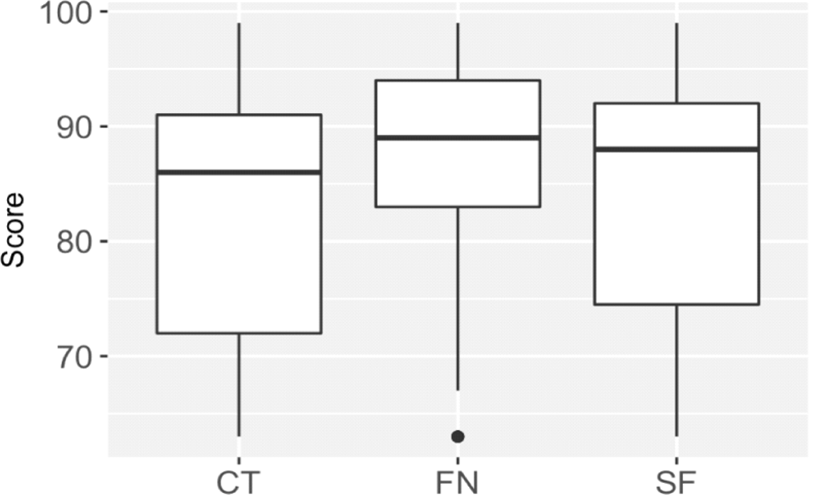
Figure 4 and Table 4 show the raw count and relative frequency of subtypes of function words. In terms of the relative frequency, the three most frequent function word errors are found in Aux-Cont (contracted forms of auxiliaries and modals), infinitive marker to (in just to make sure), and articles.
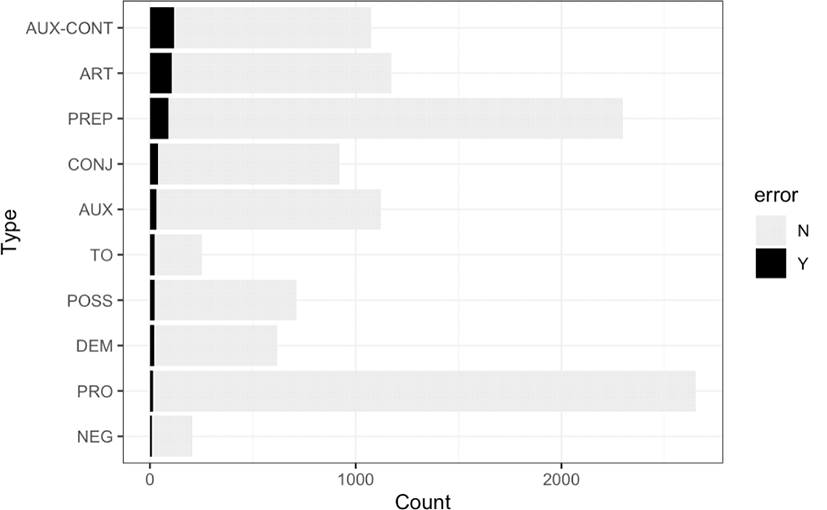
Table 5 shows the most frequent function word errors with error rate of 12% and more. The fourth column illustrates examples of the most frequent error for a given word (the numbers in parentheses are frequency). The rates show the frequency of errors relative to each given word. The most frequent errors are found with auxiliary contractions, 's (has) and 're (are). The former was mostly omitted, and the latter, you're, was perceived as your. The frequent error words also include prepositions (under), possessive our, were with negative contraction (weren't). Wrong separation is found in under, which is misheard as on the (cf. Kim, 2002). The most common type of errors is omission. Misperception of the article a as the most frequently arises after with, where linking between with and a very likely makes a sound like the. Thus, linking is a crucial cause for listening difficulty.
There were 10 content words that have error frequency of 5 or more, as shown in Table 6.
Of these, the most frequent error is found with evaluation, which is misheard as devaluation. The first vowel of evaluation is linked with the final sound of the preceding word first, resulting in misperception. There was no audible pause between first and evaluation, so [t] in first and [ɪ] in evaluation are linked and sounds like unstressed [tɪ], which is likely heard as [dɪ]. As for had, it is unclear what causes the error (have), since usually [d] and [v] are not considered confusable. It could be the influence of the following labial sound [m]. Wrong separation errors (Kim, 2002; Yang & Kang, 2020) are found with away (misheard as a way) and weekend (misheard as we can). Shipment is often misheard as ship. Only the stressed syllable ship is perceived, whereas the unstressed -ment [mn̩], with syllabic consonant and [t] deletion, is omitted. Misperception of [f] as [p], which are not contrastive in Korean, is found in the error of shifts as ships.
Suffix errors account for 9% of the single word errors. Table 7 shows the frequency of each type of the suffix errors. The most frequent errors are found with past suffix -ed, followed by plural suffix -s. The 3rd person singular -s is omitted only 3 times of 308. Nearly all suffix-errors were omission errors (65/67=97%).
| Type | Frequency | Error example | Context |
|---|---|---|---|
| Past | 17/205 (8%) | work (15) | I worked three |
| Plural | 45/717 (6%) | month (21) shift (15) |
several months before weekend shifts last |
| 3rdSg | 3/308 (1%) | get (2) | she gets back |
Table 8 shows word-sequence errors that occurred with frequency of 6 or more errors. These errors take up 39% of the total word-sequence errors (81/209).
The most frequent error-sequences include auxiliary contraction (you've received, a mistake's) and negative contraction (weren't). Others involve C-V linking (payroll issues, called _in, that weren't included _in) and elision due to C-C linking (these _sorts of). A similar error involving C-V linking has been reported in Japanese learners of English (interest _in → interesting) (Hagiwara & Kuzumaki, 1982: 57). Wrong segmentation is found in away on, misperceived as a when (cf. Kim, 2002; Yang & Kang, 2020).
As shown in the results above, it is clear that linking and elision make L2 listening harder in connected speech. Words and word sequences involving linking and elision were often misheard or omitted. L2 listeners had difficulties in correctly perceiving linked word-sequences, such as first evaluation, payroll issues. Figure 5 shows spectrograms of first evaluation, where the final consonant in the preceding word is linked with the initial vowel in the subsequent word. As can be seen in the spectrograms, there seem to be no salient cues to boundary between the two words. It thus can be difficult for L2 learners to decide whether the [t] belongs to the first or second word.
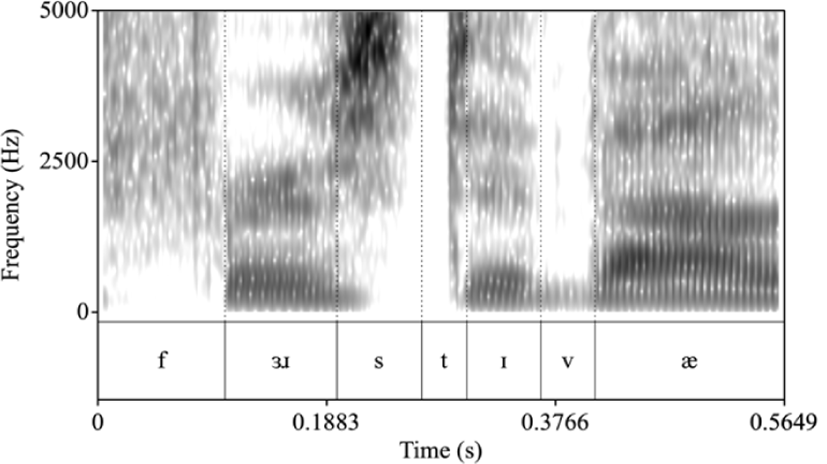
In particular, the most frequent error substitute for evaluation was devaluation (Table 6). In Figure 5, the stop closure for [t] in first is short, immediately followed by the next vowel without a pause, so it can be ambiguous to the L2 listeners. Moreover, short release duration may lead to perception of [d] instead of [t]. Whereas it is known that native speakers successfully utilize the juncture, or word boundary, information (e.g., VOT; Altenberg, 2005), the Korean EFL learners were not able to use the juncture cues and made errors in correctly locating the boundary.
This substitution cannot come from the top-down process, because evaluation would be better than devaluation in terms of the context (It was three monthsbefore I had my first devaluation), and in terms of frequency (the COCA frequency of first evaluation is 36, first devaluation is 1). Considering this, in the substitution error of evaluation as devaluation, listeners seemed to use bottom-up information (acoustic signal) rather than top-down, contextual, information. However, the lack of sensitivity to fine-grained juncture cues led to the wrong-segmentation errors.
The same applies to other phrases involving C-V linking. As in first evaluation, errors involving C-V linking result in wrong segmentation, a failure to correctly locating word boundary. Some subjects misperceived payroll issues as pay rollyshoes, as if the [ɪ] in the following word issues belongs to the preceding word. Accordingly, issues were perceived as shoes, an error in correctly locating the word boundary.
Misperception of C-C linked phrases was also common, particularly with auxiliary contractions, such as nobody's said. Frication interval is longer in double than single fricatives, but Korean EFL learners have difficulties in distinguishing between single vs. geminate fricatives across word-boundary (Shin & Hwang, 2012). L2 listeners are less sensitive to this kind of fine-grained phonetic differences than native speakers (Best, 1995; Desmerules-Trudel, 2018).
4. Discussion and Conclusion
To summarize the results, low proficiency learners tend to have more errors in longer sequences. They also tend to misperceive content words more often than higher proficiency learners do. Function words showed more errors than content words. Among the function words, the most frequent errors were auxiliary contraction, infinitive marker to, and articles. Auxiliary contraction (you've, nobody's), articles (a, the), prepositions (in), are linked with the adjacent word or elided, making them harder to perceive. The most frequent suffix errors were omission of past suffixes (worked → work). Content-word errors mostly come from linking (first evaluation → first devaluation), confusing similar sounds (shifts → ship), and possibly from the reduction of unstressed syllable (shipment → ship).
Word-sequence errors show consecutive combination of these errors: auxiliary contraction and suffix omission (you've received → you receive), wrong segmentation due to linking (payroll issues → pay rolly shoes), omission of conjunction, auxiliary, and negative contraction (that weren't → ø).
Linking is a frequent source of errors. C-V linking results in wrong segmentation, and C-C linking results in omission of final sounds of the preceding words, which are often auxiliary contractions. The results reaffirm that, due to these difficulties in phonetic decoding, listening for reduction and juncture should be explicitly taught (Celce-Murcia et al., 2010).
In addition, L2 learners would have to learn how to utilize fine-grained phonetic cues that may help them detect the juncture (in C-V linking) and distinguish single vs. double consonants (in C-C linking and elision). Even if they explicitly learned linking and elision rules, there would not be acoustic cues enough for L2 learners to detect. For accurate perception, learners will have to develop sensitivity to fine-grained phonetic details, such as the durational difference between single vs. double consonants. This is an achievable goal, since literature show that advanced L2 learners can detect fine-grained phonetic details to the level comparable to native speakers (Shoemaker, 2010; Zhang & Wang, 2019).
To conclude, the current study showed what aspects of phonetic perception are the most difficult for Korean EFL learners. It is reconfirmed that connected speech phenomena such as linking and elision are the primary source for phonetic difficulties, for both function words and content words. Improvements can be made if they learn the linking and elisions rules, and sensitivity to the fine-grained phonetic details in the linked or elided sounds.