





1. Introduction
Automatic Speech Recognition (ASR) has been widely studied by many researchers, as it is successfully implemented to speech related applications. Since ASR transforms human’s speech signals to sentence as a text, a number of tasks processing human’s speech information adopt speech recognition result. A chatbot task (Wei et al., 2018), for instance, analyzes human’s intentions based on the sentences produced by ASR system to interact with people. Sentiment analysis which evaluates the emotional state of a person also utilizes speech recognition result in order to adapt the sentiment recognition models in a noisy environment (Lakomkin et al., 2019). In practice, sentiment recognition task is usually tested in a noisy background. Therefore, building a noise-robust ASR model is crucial to the task.
Speech recognition model is generally built up with 3 different models: Acoustic Model (AM), Pronunciation Model (PM), and Language Model (LM). Human language is comprised of various syllables and AM learns how each syllable is pronounced and sequentially arranged in speech production. PM contains the mapping information of words and their realized pronunciation affected by complex phonological rules embedded in the language. Lastly, the proper structures of word sequence and grammatical information that make a sentence natural is stored in LM.
Traditionally, Hidden Markov Model with Gaussian Mixture Model (HMM-GMM) is frequently used to make an AM to learn phone sequences from the speech signals. HMM-GMM learns triphone information, three consecutive phone sequence, by cumulating mixture information of diagonal covariance Gaussians. To build a PM, a dictionary that properly maps each word to phoneme sequences is required. Therefore, generating a dictionary is crucial for creating a PM. However, this task is tricky and laborious because it needs to be updated whenever new words are found in a corpus and cover multiple pronunciation if each word is pronounced in many ways. For example, tomato has two ways to be pronounced: [təméitou] or [təmάːtou]. Trigram modeling is one of the best options to build a LM. Good-turing (Gale & Sampson, 1995) or modified kneser-ney (James, 2000) smoothing algorithms are suggested and applied to LM to predict unseen words in efficiency. However, a few drawbacks such as a sparse representation of language and computation overhead remain.
After neural network merges in ASR field, a lot of researchers have achieved a state-of-the-art performance in the speech recognition tasks (Chang et al., 2020; Miao et al., 2020; Nakatani, 2019; Watanabe et al., 2017). Especially, end-to-end (E2E) ASR models have been developed by utilizing recurrent neural network or transformer network (Vaswani et al., 2017). The greatest benefit of the neural network based model is that it trains all the AM, PM, and LM with the single neural network. To do so, training a speech recognition model becomes simpler compared to the previous algorithms that need to train each model separately and combine them.
Recently, ASR toolkits providing numerous neural network architectures such as ESPnet (Watanabe et al., 2018; Watanabe et al., 2020), or KoSpeech (Kim et al., 2020) are also introduced and they ease the speech recognition model building process. Although training a model by composing neural networks is not trick, achieving a better performance in a speech recognition task is challenging. A few papers (Koutsoukas et al., 2017; Popel & Bojar, 2018) try to suggest the solutions to improve the performance but not mainly focus on speech recognition task.
In this paper, we examine the impact of hyperparameters provided in the neural network. We select transformer network constructed with attention mechanism, since it shows a significant improvement in speech recognition tasks and is frequently applied in many studies. Our study aims to two goals. 1. Finding out which hyperparameter plays a critical role in performance improvement. 2. The tendency of training speed variation with respect to the hyperparameter values.
2. Experiments
The training network consists of two transformer architectures both in encoder and decoder parts and they are jointly trained with Connectionist Temporal Classification (CTC; Graves et al., 2006).
We implement the hyperparameter experiments on ESPnet framework compiled with Pytorch backend and the network training is carried out using 6 NVIDIA Tesla T4 GPUs.
ESPnet transformer network provides total 30 adjustable hyperparameters in the training configuration. In this paper, only 17 hyperparameters are selected because in the perspective of training network, chosen hyperparameters are more closely related to the network learning process. The selected hyperparameters are trained with proportionally ranged values based on their provided default values in the configuration. Excluded 13 hyperparameter values are fixed with the given default set in the network training configuration.
When each hyperparameter is applied in the training process with the preset values sequentially, other hyperparameters except the selected value, is fixed to the given default in order to prevent dependencies among the hyperparameter values. It is critical to keep the independency in the hyperparameter experiments, since this paper aims to investigate each hyperparameter’s impact on the network performance.
Transformer architecture has 9 hyperparameter variables in the encoder network. 3 hyperparameter variables (“output size”, “input layer”, “positional dropout rate”) are fixed to default values, and the other 6 hyperparameters (“normalized before”, “attention heads”, “linear units”, “num blocks”, “dropout rate”, “attention dropout rate”) are set to diversely ranged values. Table 1. below describes how the encoder hyperparameters are initialized and the bold text indicates the default value.
The hyperparameters involved in the training encoder network is described in Figure 1 and the selected hyperparameters for the experiment are highlighted in gray.
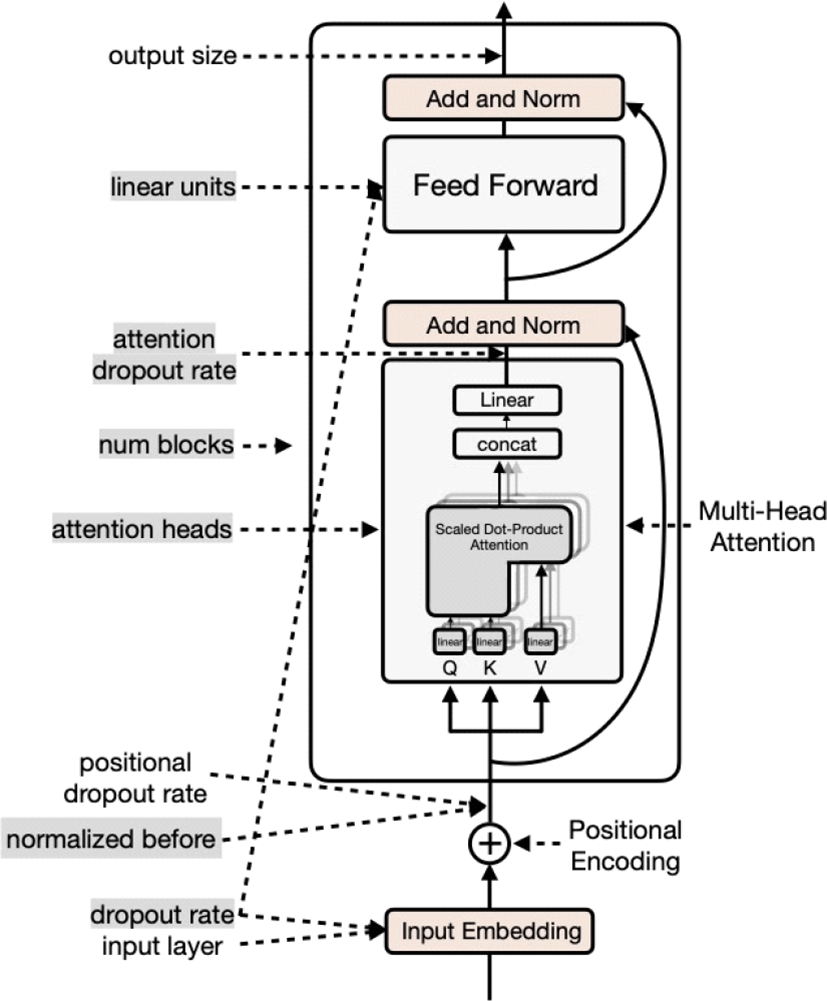
An “output size” hyperparameter is fixed to 256 so that the number of “attention heads” is able to be adjusted. The number of “attention heads” split the number of Q, K, and V variables and then split variables are concatenated after they passed scaled dot-product attention. Therefore, the dimension of scaled dot-product attention should meet the “output size” in order to evade dimension mismatch.
Since input feature extraction is not the main focus in the study, convolutional network as a default setting for extracting input features is applied to input layer hyperparameter. “positional dropout rate” was not included in the experiment list because ESPnet toolkit ignores the value in the configuration but automatically initializes this hyperparameter with “dropout rate” hyperparameter.
In the decoder network, 7 hyperparameters are ready to be adjusted, but only 5 hyperparameter variables (“attention heads”, “linear units”, “num blocks”, “dropout rate”, “self attention dropout rate”) are extracted for experiment, and the rest 2 variables (“positional dropout rate”, “src attention dropout rate”) are remained as default. Table 2. shows the types of hyperparameters used in the transformer network and their values. The default values of the hyperparameter in the box are bolded.
As Figure 2 depicts, hyperparameters for the experiment are listed right next to the decoder network architecture and among them, the shaded variables in gray are trained with multiple values.
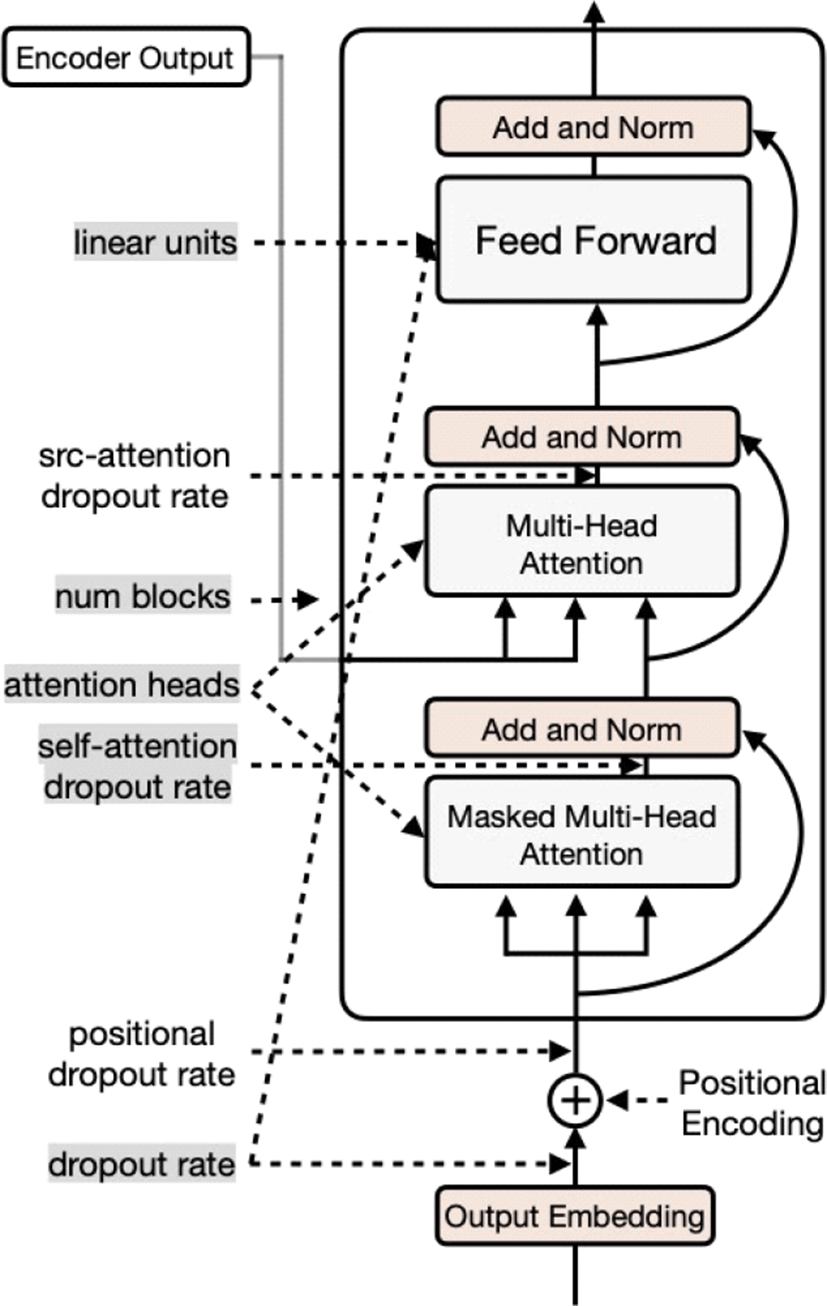
In the decoder section, we ignore two hyperparameters, “src attention dropout rate” and “positional dropout rate” because they automatically share “self attention dropout rate”, and “dropout rate” values respectively during training network.
A few hyperparameters which are not directly related to the network are included in the experiment because of their significant impact on the network performance. There are 14 hyperparameters in total, and 6 of them are chosen to the training process. Table 3. elaborates the detail information about the indirectly related hyperparameters. Hyperparameters set to default are bolded.
Rather than directly participating in the training process to improve speech recognition performance, model hyperparameters mainly relate to managing GPU memory in efficiency or boosting up the speed of the training process.
“batch type”, “batch size”, and “accum grad” hyperparameters which contribute to memory management are initialized to default values. When it comes to “max epoch”, instead of using default value 100, we minimize it to 50 so as to save the training duration to finish all the combinatory hyperparameter experiments. “patience” given default ‘none’ in the experiment, decides whether to stop training process when the model is not improved after the repeated epochs. “learning rate” and “scheduler” are fixed to default but in order to see the impact of “scheduler”, we diversify a “warmup steps” value in the training process. An “optim” hyperparameter is another important factor in the neural network training, but it is already experimented a lot in the previous studies (Kingma & Ba, 2014; Okewu et al., 2019). Thus, “optim” is set to default value in this study.
Since Wall Street Journal (WSJ) has been trained and tested frequently in ASR experiments, this article carried out the hyperparameter experiment with WSJ dataset. Before training the model, WSJ, which consists of csr_1 and csr_2_comp was extracted into SI-284 set for training and dev93 and eval92 set for evaluation. The training set provides total 37,416 English sentences including noise, space, and symbols (e.g., exclamation or question marks) and 333 sentences are prepared in an equivalent condition for evaluation set.
3. Results
After training speech recognition models with selected hyperparameters, each model decoded WSJ dev93 and eval92 set and we extracted Word Error Rate (WER) information from the result. The Table 4 shows all the decoding result in WER, with respect to the hyperparameter values. The decoding result is sorted by model, encoder and decoder parts and the best WER score (mean WER score from dev93 and eval92 sets) in each hyperparameter set is bolded in the table. This paper mainly focuses on how the WER score and training speed vary as the hyperparameter values change. Therefore, the speech recognition performance achieved from the experiment could be lower than the other state-of-the-art studies’ because the model is not fully trained in optimal condition.
An “init” hyperparameter controls weight initialization and xavier method especially using uniform distribution shows the best performance (17.0/12.7 WER) among the other methods. The “init” hyperparameter provides chainer option which is used in chainer toolkit and this option initializes weight with LeCun normalization (LeCun et al., 2012). WER decreases gradually when “warmup steps” declines. Since the “warmup steps” hyperparameter modifies the “learning rate” value in which “warmup steps” reaches its value, setting it to a lower value tweaks the learning rate much earlier and helps the model to converge fast. Similar to “warmup steps”, a “keep nbest model” hyperparameter also shows tendency that WER in eval92 set declines as value decreases thought the WER in dev93 set shows the opposite result. The result implies that the more the number of hypothesis to choose, the more the task difficulty of finding a correct one increases. Thus, lowering the complexity by reducing “keep nbest model” might be crucial in the network training. However, too much low value could degrade or halt WER score because the score increases a bit (12.7 to 12.8 WER in eval92) when the hyperparameter is adjusted to 5 from 10. A “length normalized loss” hyperparameter derives better score from false setting (17.3/12.7 WER). “ctc weight” and “lsm weight” hyperparameters do not show any meaningful result because their WER scores fluctuate regardless of the values’ shift.
Two hyperparameters in the encoder network, “linear units” and “num blocks” improve the decoding performance as the hyperparameter values increase. Compared to “num blocks” (17.3/12.7 WER), a “linear units” (16.3/12.3 WER) hyperparameter makes a better progress in the decoding performance. A “dropout rate” hyperparameter, however, shows convex like tendency in its result. When it is set to the lowest value, 0.0, its WER is 17.4/14.4, but it is dropped (17.3/12.7 WER) as the value increases by 0.1 but as soon as the value rises, the performance is degraded. “attention heads” and “attention dropout rate” do not draw a meaningful result in this experiment.
As seen in the encoder network hyperparameters, “linear units” and “num blocks” hyperparameters in the decoder network also show linearity in their improvement curve. However, the performance increases rather slowly as the value changes. WER scores from “num blocks” and “linear units” in the encoder network are dropped by 7.2/7.0 and 2.6/2.5 respectively, but 3.4/3.5, and 0.8/0.6 in the decoder network. A “dropout rate” hyperparameter in the decoder network does not act like the one in the encoder network, but it reaches the lowest WER at the value 0.1 and maintains high WER at the other values. Meaningful result is not found in “attention heads” and “self attention dropout rate”.
According to the experiment, the study shows which hyperparameters are relatively critical to speech recognition performance. Based on the result, we collect optimal values from each hyperparameter and train the model again to see whether the model develop the decoding performance.
However, the optimal values gained independently may not guarantee the best decoding performance since each value was tested without considering dependencies among the 17 hyperparameter values. In order to find the optimal hyperparameter set, several research (Wang et al., 2019; You et al., 2019) have considered dependencies of two or three hyperparameters in their experiment. In light of this fact, our study needs to proceed the experiment considering all the dependencies of the hyperparameters, but this is almost impossible due to the large number of experimental trials. If we take the dependencies into account, the number of trials will be 20,480,000,000 based on the equation (1). In (1), X, Y, Z is the number of value sets (2, 4, 5), and i, j, k is the number of hyperparameters (2, 8, 7) respectively.
This trial number will go down to 71 if the dependencies of the hyperparameter values are not considered. This paper trains the model with optimal values drawn from the independent condition to see that the model is still able to increase the speech recognition performance even though the optimal values were not considered the dependencies of the hyperparameters.
The trained model that ignores dependencies of the hyperparameters proves that the decoding performance has been improved by reducing WER score to 13.4/10.4 and this performance could be developed by running more epochs.
While the network trains models with different hyperparameter values, we mark the training duration between the 1st and 2nd epochs to see how the training duration varies depending on the hyperparameter values. In terms of training speed, the result shows that the number of “linear units” and “num blocks” hyperparameters brings a meaningful change in the encoder and decoder networks.
Figure 3 shows two hyperparameters’ training speed as the number of “linear units” varies. When the number of “linear units” in the encoder network increases, the training speed declines gradually. In contrast, the identical hyperparameter’s behavior of training speed variation in the decoder network does not gradually increase but is stabilized its speed around 590 seconds except when the number of “linear units” hits highest value, 636 seconds, in this experiment. Although the number of “linear units” hyperparameter has a direct influence on the training speed, the degree of change in both the encoder and decoder network is not similar.
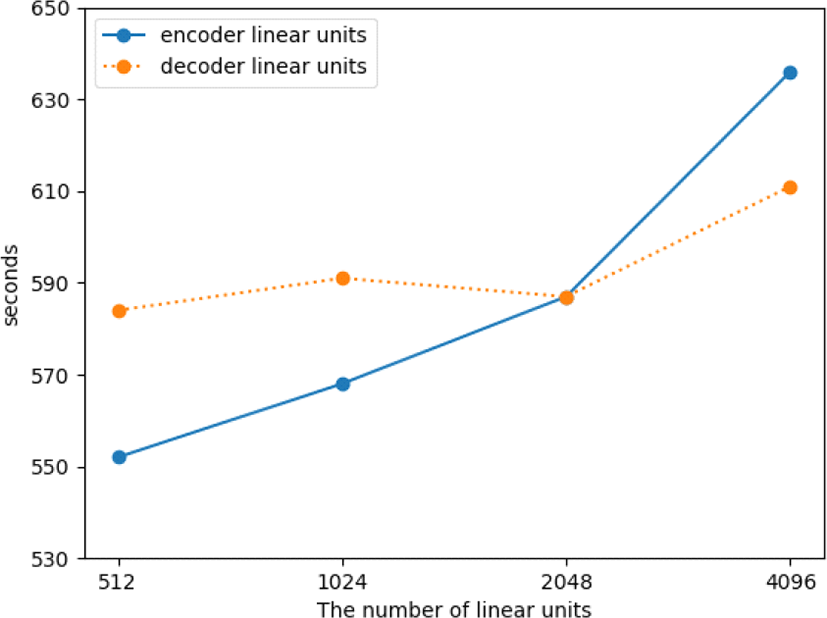
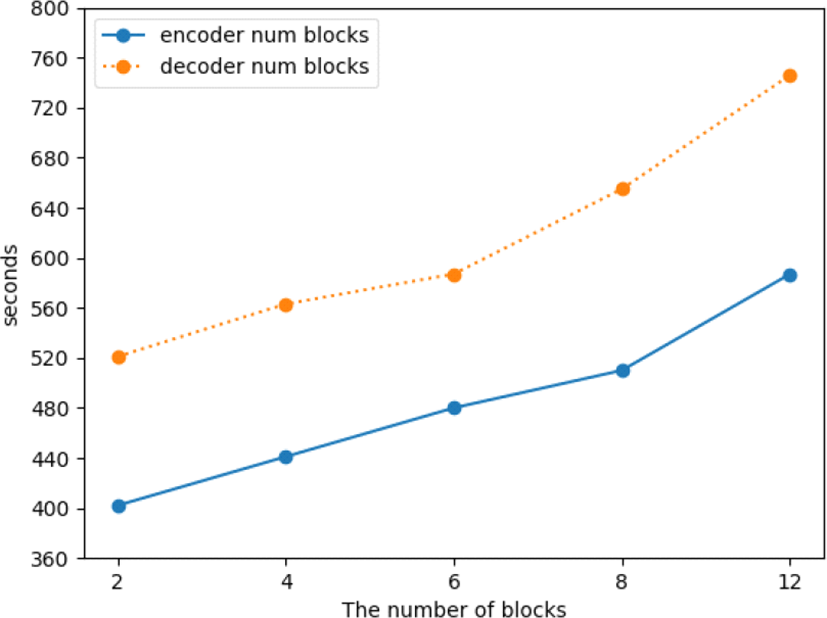
Figure 4 presents that “num blocks” hyperparameters in both the encoder and decoder networks show steady increase with respect to training duration. In terms of the pattern of speed increase in both hyperparameters, the amount of the speed duration increased is similar as the number of blocks pile up. However, the mean speed gap between the two hyperparameters is 130 seconds and it predicts that a computational cost of “num blocks” in the decoder network is more expensive, thought the number of “num blocks” hyperparameter remains identical in both networks.
4. Conclusions
This paper investigates the impact of hyperparameters in both ASR performance and training speed based on the E2E transformer network. Total 17 hyperparameters out of 30 are selected and trained with diversely ranged values.
In model hyperparameters, “init”, “warmup steps”, “keep nbest model” and “length normalized loss” show a significant impact on the speech recognition performance. This study also finds that the number of “num blocks” and “linear units” brings a gradual improvement as their values increase but this tendency is more strongly presented in the encoder network hyperparameters.
Training speed varies when the number of “num blocks” and “linear units” hyperparameters change. As the result indicates, WER score from the “linear units” hyperparameter in the encoder network is more significantly affected by the number of values, when the other in the decoder network does not show a strong correlation between the WER score and the number of values. When it comes to the training speed comparison of “num blocks” hyperparameters both in the encoder and decoder networks, the hyperparameter in the encoder network is more computationally expensive than the other.
Two hyperparameters, “linear units” and “num blocks”, that bring a significant impact on WER score may be differently evaluated if we consider the training speed result. Since training duration is critical in real-world application, A speech recognition model needs to be trained fast in order to save hardware resources and research time. In light of this aspect, the “linear units” hyperparameter in the decoder network may not worth experimenting with various values because its training time usually takes longer with little improvement. The same hyperparameter in the encoder network, however, achieves relatively fast performance in training duration with quick convergence though the WER score lags behind a bit.
When it comes to the “num blocks” hyperparameter, the gap between the two WER scores from encoder and decoder network is relatively large in lowest value 2. This gap almost perishes when the hyperparameter value is grown up to 12. While this WER score gap between the two networks gets lower as the hyperparameter value increases, the training duration gap between the two networks has been almost stable. Therefore, if the “num blocks” hyperparameter value needs to be set high, it may be efficient to tweak this value in the encoder network and vice versa.
Finally, after the experiment, we train the model with the optimal values found from the result, we obtained the improved model that shows 13.4/10.4 WER. Compared to the best result in the experiment 16.3/12.3, the optimal model dropped WER by 2.9/1.9.