





1. Introduction
The phonetic features of a person’s voice can convey the social and affective stance of a speaker (Campbell & Mokhtari, 2003; Scherer, 1986; Tatham & Morton 2004), including the expression of a polite stance (Brown et al., 2014; Hübscher et al., 2019; Idemaru et al., 2019, 2020; Nadeu & Prieto, 2011; Ofuka et al., 2000; Winter & Grawunder, 2012). In particular, many of these studies have discussed the effect of pitch on polite speech. Ohala’s (1984) Frequency Code proposes that high pitch is associated with the expression of a polite stance, and low pitch is associated with the vocal expression of dominance. New evidence suggests that several languages do not abide to the Frequency code with respect to the expression of politeness, showing lower voice pitch in polite speech contexts. This is the case with Korean (Shin, 2005; Winter & Grawunder, 2012), Taiwanese Mandarin (Lin et al., (2006), German (Grawunder et al., 2014), and Catalan (Hübscher et al., 2018). However, there are also many other acoustic variables that can index polite speech, including low intensity (e.g., Culpeper et al., 2003; Idemaru et al., 2020), longer speech duration (e.g., Fan & Gu, 2016; Navarro & Cabedo Nebot, 2014; Ofuka et al., 2000), and voice quality features (Hübscher et al., 2018; Idemaru et al., 2019; Winter & Grawunder, 2012), among others. This suggests that politeness-related meanings are signaled not just by one cue alone, but by a complex web of acoustic cues.
Here, we analyze new Korean data for a new acoustic dimension of politeness expression. Whereas Winter & Grawunder (2012) used a task where participants had to imagine speaking with a socially superior interlocutor (such as a professor) as opposed to a same-aged peer, we now look at the phonetic realization of politeness in a more naturalistic setting that involves actual dyadic interactions with interlocutors differing in social status, thereby creating formal/ polite versus informal/casual contexts. As was the case with previous research by Winter & Grawunder (2012), the Korean language is an ideal test bed for looking at politeness-related meanings because this language has grammaticized honorifics. For example, the following two utterances demonstrate how the same propositional content differs as a function of whom a speaker is talking to:
(1) 바쁘시겠지만 잠깐만 가르쳐 주실 수 있나요?
pappu-si-kyess-ciman camkkan-man kaluchy-e cwu-si-l swu iss-na-yo?
/pa p͈ɯ.si.get.ʤi.man ʨam. k͈an.man ka.ɾɯ.ʨhʌ. ʨu.sil. su it. na.yo/
busy-HON-but briefly-only teach-BEN-HON-can-INT-HON?
‘I know you must be busy(HON), but can(HON) you teach(HON) me how to use it?’
(2) 바쁘겠지만 잠깐만 가르쳐 줄 수 있니?
pappu-kyess-ciman camkkan-man kaluchy-e cwul swu iss-ni?
/pa p͈ɯ.get.ʤi.man ʨam. k͈an.man ka.ɾɯ.ʨhʌ. ʨul. su it.ni/
busy-but briefly-only teach-can-INT?
‘I know you must be busy, but can you teach me how to use it?’
The utterance in the first example belongs to what is endemically called contaymal (“polite/deferential speech”) by Korean speakers, as opposed to the casual and informal register, panmal (“casual/ intimate speech”) (e.g., Byon, 2006). The existing literature on politeness in Korean has much focused on these honorific markers with, in the past, little attention being paid to what phonetic factors correlate with honorification. In the current study, we look specifically at vowel hyperarticulation. This is motivated by the fact that Winter & Grawunder (2012) found a number of their phonetic correlates of polite speech to be consistent with clear speech, such as increased harmonics-to-noise ratio and slightly slower speech rate. In line with this existing evidence and Gussenhoven’s Effort Code (Gussenhoven, 2002, 2004, 2016), which correlates greater articulatory effort in speech with lower social positioning, we reasoned that when Korean speakers use contaymal, they would speak more effortfully, with more hyperarticulated vowels. This prediction is also motivated by the fact that Korean contaymal is associated with “proper” speech that would be used in more formal settings (Lee & Ramsey, 2000; Sohn, 1999).
Independent of speech rate, clear speech has been shown to result in longer vowel duration and expanded acoustic vowel spaces compared to conversational speech, resulting in greater vowel intelligibility improvements for listeners (Bradlow et al., 2003; Ferguson & Kewley-Port, 2002; Picheny et al., 1985, 1986). Ferguson & Kewley-Port (2007) found that an expanded F1 range and higher F2 values for front vowels were important criteria for improved vowel intelligibility in clear speech. In Smiljanić & Bradlow (2005), the vowel expansions contributed to great intelligibility in clear speech for both Croatian and English, suggesting that the expansion of the vowel space in clear speech may be language independent regardless of vowel inventory size.
Also note that clear speech as a function of politeness must take gender into consideration as studies have suggested clearer speech style for female speakers (e.g., Idemaru et al., 2020; Simpson, 2009; Winter & Grawunder, 2012). Moreover, female speakers have been perceived as being clearer than male speakers by making greater vowel acoustic changes for clear speech (e.g., Bradlow et al., 2003; Lam & Tjaden, 2013), suggesting that vowels may be more hyperarticulated by female than male speakers in polite speech as well.
The aim of the current study is twofold. First, we explored the segmental aspects of Korean polite speech, specifically through the acoustic analysis of vowels produced in polite and casual speech contexts. We predicted that the articulatory effort found in clear speech shares acoustic similarities with vowel production in polite speech. Second, we sought to examine whether there is a gender difference in the degree of vowel hyperartculation when expressing politeness. We predicted that female speakers are more likely to employ greater vowel acoustic changes than male speakers in polite speech. To this end, our study engaged participants and their actual friends (casual speech) and an unfamiliar professor (polite speech) in spontaneous interactions to minimize the level of stylistic control associated with the naturalistic setting and to encourage speakers to exploit the acoustic correlates of politeness they would in everyday speech behavior.
2. Methods
Fourteen adult (mean age: 23.3) native speakers (7 female and 7 male) of Standard Seoul Korean participated in the study for a small payment. All participants were born and raised in the Seoul/ Gyeonggi and were students at a university in Seoul at the time of testing. All participants reported normal hearing.
All participants produced the utterances in two social conditions to elicit polite and casual speech. Participants were seated in a sound-attenuated booth once with an unfamiliar elderly male professor to elicit polite speech, and the other time with their close friend of the same gender to elicit casual speech. For both conditions, several tasks were given of which we discuss here only two: In the map task (Brown et al., 1984), all participants were asked to help the professor/friend navigate to the final destination on a map. In the role play task, they role-played a situation where participants had to apologize for losing a valuable item borrowed from the professor/friend. The two social conditions were randomized and half of the participants were assigned to “professor” condition first and the other half to “friend” condition first, but always in the order of the map and then the role playing task1. The productions were recorded using a Shure SM 10A head-mounted microphone on a Marantz PMD670 solid-state recorder at a 44.1 kHz sampling rate with 16-bit quantization.
Using Praat 6.0.35, first (F1) and second formants (F2) of the sentence- and phrase-initial monophthongs of the fourteen participants’ production were measured. Seven vowels (/i/, /e/, /ɯ/, /o/, /u/, /ʌ/, /a/) were measured from the onset of the first periodic wave to the offset of the last one observed in both the waveform and the spectrographic display. The vowel duration was measured from the onset of voicing in the vowel to the beginning of the consonant constriction. The onset and offset of clear energy in the second formant frequency on the sound spectrogram served as a reference, along with the waveform, to determine the onset and offset of the vowel. A total of 3,994 vowels were evaluated.
We used R version 4.0.2 (R Core Team, 2019) with the tidyverse package 1.3.0 (Wickham et al., 2019) for statistical analysis. Effect size (Cohen’s d) was computed with the effsize package 0.8.0 (Torchiano, 2019). Bayesian mixed regression models were implemented with brms 2.13.3 (Bürkner, 2017). All data and analysis code is available at the following publicly accessible Open Science Framework repository: https://osf.io/a6ryk/
Throughout the paper, all Bayesian mixed models have a similar structure, with the primary fixed effect in question being ‘condition’ (friend versus professor), and an interaction of this effect with ‘gender’ (male versus female). To facilitate the interpretation of interactions, gender and condition were sum coded (–1, +1). Vowel type (7 levels, as specified above) was added as another fixed effect. Random effects include random intercepts for participants and items, as well as by-condition varying random slopes for participants. No random slopes can be fitted for items, as there were many items (543 distinct words, lemmatized), making the item distribution very sparse, with most items not being attested in both conditions. More details (including prior specifications) are given when each model is discussed.
3. Results
We first assessed whether there were reliable differences in duration. Overall, vowels in the casual condition were slightly shorter (M=55.0 ms, SD=27.2) than in the polite speech condition (M=59.2 ms, SD=30.5), as predicted. The effect size of this difference (pairwise across speaker averages) was large (Cohen’s d=0.84), but a Bayesian mixed effects regression with the fixed effect speech condition (casual/polite), gender, vowel, and a speech condition x gender interaction showed that this difference was not reliable2. The credible intervals of the speech condition effect or the interaction firmly covered zero. The posterior probability for polite speech being longer in duration was p (β>0)=0.77. The results indicated that there was no sufficient evidence for politeness influencing vowel duration consistently across speakers and items.
Figure 1 shows the F1/F2 averages for each vowel separately for female participants (left) and male participants (right). The vowel space for casual speech (yellow) is largely contained within the vowel space for polite speech (gray). The high-front vowel /i/ was particularly more hyperarticulated (fronted and raised) for female participants. To quantify hyperarticulation in a unified fashion across vowels, we computed each speaker’s F1/F2 midpoint (arithmetic mean) and calculated the Euclidian distance for each vowel token from this midpoint. On average, Euclidian distances were greater for polite speech (M=379 Hz, SD=247 Hz) than for casual speech (M=326 Hz, SD=198 Hz), suggesting hyperarticulation in polite speech.
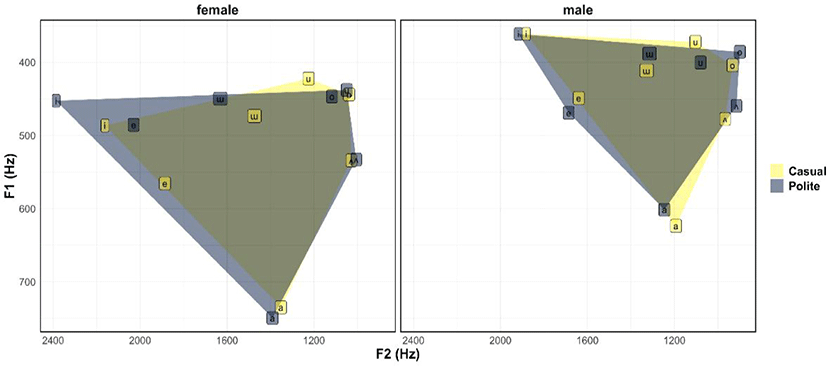
We did not normalize vowel formants for speaker because 1) the Euclidian distance measure we used already takes into account each person’s central value in their respective F1/F2 spaces, and 2) our statistical model further accounts for speaker dependencies via the random effects structure. We want the speaker characteristics to be available for inference rather than extracting it out via normalizing before entering it into the model.
When these averages are broken up by gender, it becomes apparent that female speakers showed a much bigger difference between polite speech (M=442 Hz, SD=275 Hz) and casual speech (M=358 Hz, SD=195 Hz) than male speakers (polite: M=330 Hz, SD=211 Hz; casual: M=302 Hz, SD=196 Hz). This corresponds to about 24% increase in Euclidian distances for polite speech compared to casual speech; whereas this figure is only a 9% increase for men.
Figure 2 shows the Euclidian distances separately for each speaker. A pairwise analysis across speakers shows that this is a medium effect size (Cohen’s d=0.61), and a total of 10 out of 12 speakers (83% of our sample) show an increase in Euclidian distances for polite speech, with the only two exceptions being male speakers3. This suggests that the pattern is remarkably consistent across speakers.
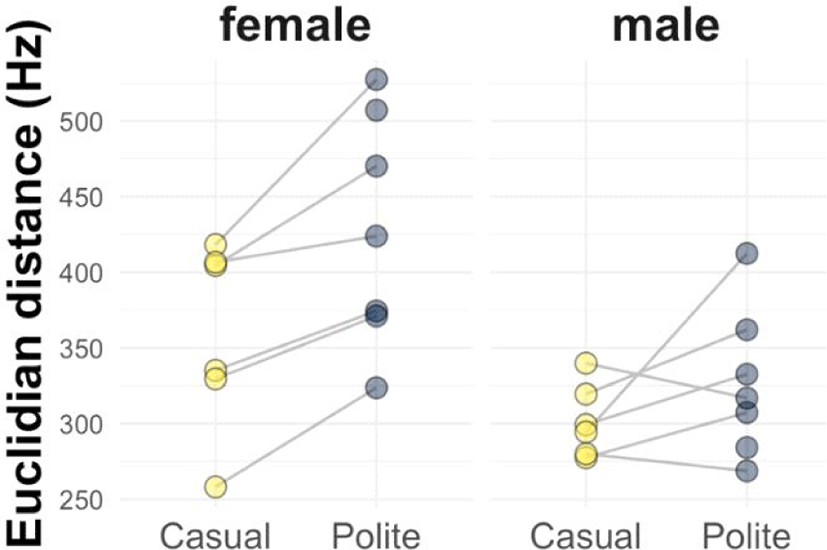
Using the token-based Euclidian distances as a response measure in a Bayesian mixed effects regression model with speech condition, gender, vowel, duration, and speech condition x gender interaction with subjects and items as random effects (with the same random effects structure and Monte Carlo (MCMC) specifications as the last model). The duration terms controls for the fact that longer vowels are generally more hyperarticulated. As is to be expected, duration exerted a reliable positive influence on Euclidian distances [estimate: +0.41, 95% CI: (0.13, 0.69)], with a very low posterior probability of this effect being below zero (p=0.001). However, controlling for this duration difference, there still was a strong effect of speech condition, with the 95% credible interval of the condition coefficient (estimate: +12, more positive=more Euclidian distances in polite speech) barely including zero [–1.06, +25.05] and a very low posterior probability of the effect being below zero (p=0.03). There was a significant gender effect [estimate: +47.5, 95% CI: (18.19, 77.31), p=0.001], but no reliable speech condition x gender interaction [estimate=+0.88, 95% CI: (–11.63, +14.36), p>0=0.77], indicating that polite speech has a strong effect on both groups.
In order to better view the effect size on individual vowels across groups, we examine the vowel-specific results descriptively. Figure 3 shows that Euclidian distances from a speaker’s vowel space centroid are clearly larger for women overall, specifically for high vowels /i/, /e/, /ɯ/ and /u/. The /i/ pattern is absent from male speakers, although male speakers display a trend toward hyperarticulation for /e/.
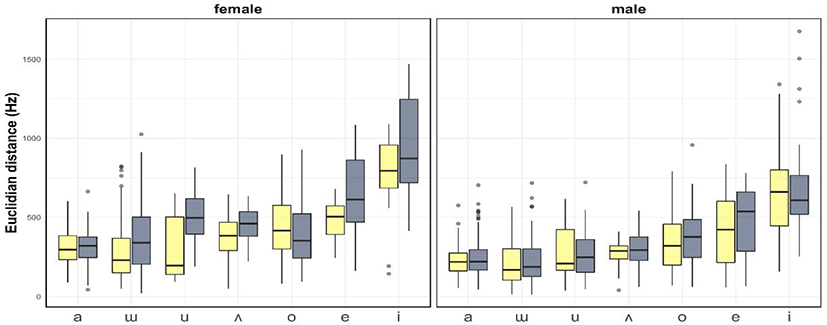
4. Discussion
In this study, we examined the vowel space and duration of casual and polite speech in Korean. In particular, we report acoustic correlates showing that polite speech shares similarities with clear speech. Specifically, speakers showed greater vowel space expansion for polite speech than casual speech. The vowel hyperarticulation in polite speech was more evident in female speakers’ production, specifically for high vowels.
In view of the positive correlation between vowel expansion and speech intelligibility (Bradlow et al., 1996; Ferguson, 2012), a stretching of the acoustic-phonetic space along the F1 and F2 dimensions demonstrates the speaker effort to enhance intelligibility in polite speech without slowing down. This is consistent with the idea that Gussenhoven’s Effort Code plays a role in the communication of politeness-related meanings, as it suggests that speakers (especially female speakers) produce more hyperarticulated vowels regardless of speech rate. Furthermore, as phonetic reduction of vowels in casual speech was shown as a social marker of closeness between interlocutors (Lancien, 2019), enhancing the acoustic distance across vowel categories can be interpreted as an effort to enhance social distance in polite speech.
The expansion of the vowel space dispersion was more prominent for female speakers than male speakers. This suggests a gender-based difference in employing vowel space as an intelligibility-enhancing strategy to communicate politeness. However, our results depart from previous reporting on the concomitant association in vowel duration and vowel space expansion in clear speech (Bradlow et al., 2003; Ferguson & Kewley-Port, 2007; Picheny et al., 1986). Specifically, we found that the reported Euclidian distance measure was affected by social context while statistically controlling for duration. And duration itself did not in fact differ between the two experimental conditions.
Our results are broadly in line with the observation that female speakers make a greater phonetic contrast across vowel categories for clear speech (Henton, 1995 for British English and Yang for Korean, 1996). Explanations for the female speaker benefit in greater perceptual intelligibility have been attributed to female speakers’ greater vowel space expansion during production. For example, Bradlow et al. (1996) found that female speakers with more dispersed peripheral vowels resulted in a higher transcription accuracy, indicating that vowel space can be a good measure of overall intelligibility (p. 270). Gordon & Heath (1998) claimed that female speakers tend to push high-front vowels to the peripheral regions of the vowel space as a way to denote smallness and femininity. Given the previous findings of a systematic shifting for high front as well as low back vowels in clear speech regardless of gender (Bradlow, 2002; Pettinato et al., 2016), the greater upward targeting of high tense vowels for female as well as male speakers, although to a much lesser extent, may be better interpreted as a socially motivated signature of polite speech (i.e., projecting smallness and submission). However, it should be noted that greater variability shown in Euclidian distances for female speakers may also indicate a larger disparity among female speakers in the effect of the perceived social prestige on speech production.
Our results add to the growing body of literature showing the multimodal social-emotional cues in speech production and perception. Despite a large amount of acoustic variability stemming from naturalistic contexts during the dynamic face-to-face social interactions adopted in this study, a larger vowel space size was shown to correlate with polite stance. Although vowel space is known to induce less coarticulation and more precise articulation (de Jong et al., 1993) in hyperarticulated speech, the influence of vowel space expansion on the level of politeness in speech perception has not been extensively investigated, and thus, can be applied in future study to examine whether listeners also use these cues to decode social communicative intentions in speech.