





1. 서론
이 논문에서는 이집트인 학습자들을 대상으로 한 한국어 모음 지각 실험과 산출 실험을 통해 이집트인 한국어 학습자들이 한국어 모음을 어떻게 지각하고 범주화하며, 이들이 발음한 한국어 모음을 한국인들이 어떻게 지각하는지 밝히고, 이를 토대로 이집트인 학습자들의 한국어 모음 범주화가 그들의 한국어 모음 지각과 산출에 어떤 영향을 미치는지 밝히고, 기존의 L2 음성 지각을 설명하는 두 모델인 Flege(1995)의 SLM(speech learning model, 음성학습모델)과 Best(1995)와 Best & Tyler (2007)의 PAM(perceptual assimilation model, 지각동화모델)이 이집트인 학습자들의 한국어 인지와 산출을 얼마나 잘 설명할 수 있는지, 보완할 점이 있는지 논의하는 것을 목표로 한다.
SLM과 PAM은 모두 L2 음소가 L1 음소와 별개의 공간에 독립적으로 존재할 수 있는 것이 아니라 L1 음소 공간에 들어가 L1 음소들에 동화되거나 별도의 L2 음소 범주를 형성한다고 보는 관점에서는 동일하지만 어떤 L2 음소는 쉽게 습득하고, 어떤 음소는 습득하기 어려운지에 대한 설명에서 차이가 난다. SLM에서는 L1과 동일하거나 비슷한 L2 음소는 대응하는 L1의 음소로 범주화되고, L1과 다른, 혹은 L1에 없는 L2 음소는 독립된 음소로서 새로운 범주(new category)를 형성하게 된다고 보고, 다른 음소는 새로운 범주를 쉽게 형성하기 때문에 더 잘 습득하지만 비슷한 소리는 그 차이를 인식하지 못하기 때문에 습득이 어렵다고 보았다.
반면에 PAM에서는 L1 음소와 같거나 비슷해서 L1 음소와 일대일로 범주화되는(two category assimilation) L2 음소는 지각이 잘 되는 반면, L1 음소와 달라서 두 개, 혹은 세 개의 L2 음소가 하나의 L1 음소로 범주화되는 경우(single category assimilation, 혹은 category goodness assimilation)에는 하나의 L1 음소와 범주화되는 복수의 L2 음소들은 구별해서 지각하는 데 어려움이 발생하는데, 한 L1 음소에 동화되는 복수의 L2 음소들의 지각적 거리가 비슷할 경우(single category assimilation)에는 지각적 거리가 다른 경우(category goodness assimilation)보다 구별해서 지각하는 데 더 어려움을 겪는다고 보았다.
이 논문에서는 한국어와 이집트 아랍어(이하 ‘이집트어’)의 모음들에 대한 선행 음향 연구와 이 연구에서 수행한 지각실험 결과를 토대로 한국어의 모음들이 이집트인 학습자들에게 어떻게 범주화되었는지 살펴보고, SLM과 PAM이 이 현상을 적절하게 설명하는지 검토할 것이다.
SLM과 PAM은 L2 음소의 지각을 설명하는 것이 목적이어서 L2 음소의 산출(production)에 대해서는 아무런 설명을 하지 못한다.
모어 습득의 경우 생후 상당히 많은 언어 입력이 일어난 후에 음성 산출이 가능해지기 때문에 대부분의 연구자들은 L2 음성 학습에서도 음소의 지각이 산출에 앞서며, 하나의 L1 음소에 동화된 복수의 L2 음소들을 구별해서 지각할 수 있어야 구별해서 발음할 수 있게 된다고 본다(Best, 1994; Bradlow et al., 1997; Cho & Jeong, 2013; Flege, 2003; Iverson et al., 2012; Jusczyk, 1997; Lopez-Soto & Kewley-Port, 2009; Wong, 2013).
그러나 여러 연구에서 L2 음소의 지각이 산출로 쉽게 연결되지 않는다는 사실이 밝혀졌으며(Hwang & Lee, 2015; Golestani & Pallier, 2007; Lopez-Soto & Kewley-Port, 2009; Peperkamp & Bouchon, 2011), 심지어는 산출이 지각보다 먼저 일어난다는 사례도 보고되었다(Joh & Lee, 2001; Sheldon & Strange, 1982).
L2 지각과 산출과의 관계는 더 심층적으로 연구되어야 하는데, 이 논문에서는 이집트인 학습자들이 한국어 모음을 어떻게 범주화하는지 살펴보고, 이를 토대로 한국어 모음 지각과 산출과의 상호관계를 논의할 것이다.
이상의 내용을 요약하면 이 논문에서는 다음의 연구 문제들을 논의할 것이다.
2. 이집트인 학습자의 한국어 모음 범주화 예측
현대 표준 아랍어의 모음 체계는 장모음 /aː, iː, uː/와 단모음 /a, i, u/로 이루어져 있다(Alghamdi, 1998; Alotaibi & Hussain, 2010; Khalil, 2014; Watson, 2002). 현대 표준 아랍어의 문자 체계에서는 장모음만 모음을 표기하는 문자로 표기되고, 단모음은 모음 삽입 기호로 표기된다(Al-Eisa, 2003; Alotaibi & Hussain, 2010; Kotby et al., 2011).
역사적인 변화를 통해 이집트 구어체 아랍어는 문어체보다 더 많은 모음을 가지게 되었다. 이집트 구어체 아랍어의 모음 체계는 장모음 5개(/a:, e:, i:, o:, u:/)와 단모음 3 개(/a, ɪ, u/)로 구성되어 있다(Bishai, 1961; Broselow, 1976; Fathi, 2013; Munro, 1993; Norlin, 1987; Watson, 2002). 단모음은 100−150 ms 정도의 길이로 실현되며, 장모음은 단모음의 두 배가 넘는 225−350 ms 정도의 길이로 발음된다(Al-Ani, 1970; Fathi, 2013).
다음의 그림 1은 이집트 카이로 출신 남성 9명의 이집트 구어체 아랍어의 모음 포먼트 도표를 보여준다(Norlin, 1987).
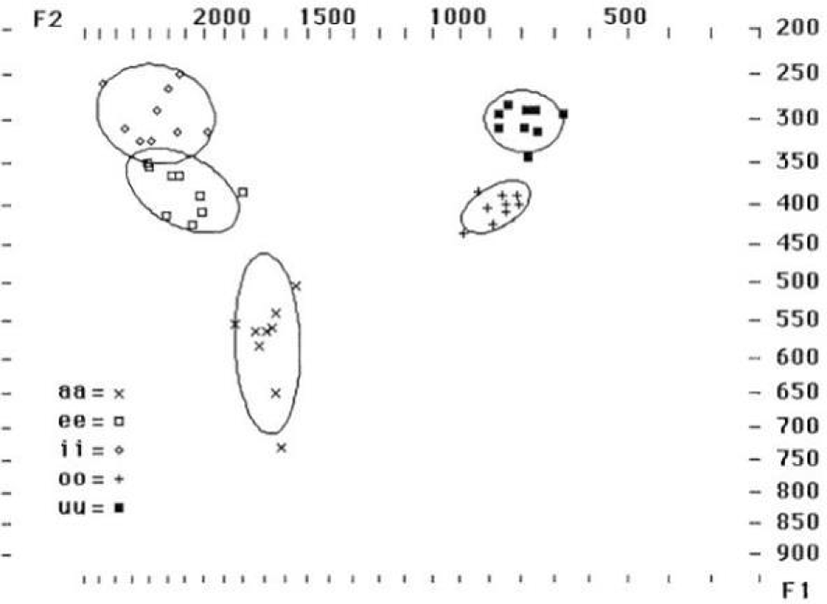
다음의 표 1은 Norlin(1987)에서 보고된 남성 화자들의 이집트어 모음 평균 포먼트 값과 Shin et al.(2012)에 보고된 한국인 남성 화자들의 한국어 모음 평균 포먼트 값을 보여주며, 그림 2는 표 1의 내용을 포먼트 도표로 변환한 것이다.
| /ㅏ/ | /ㅗ/ | /ㅜ/ | /ㅣ/ | /ㅔ/ | /ㅡ/ | /ㅓ/ | ||
|---|---|---|---|---|---|---|---|---|
| 한국어 | F1 | 788 | 356 | 280 | 259 | 490 | 334 | 560 |
| F2 | 1,407 | 795 | 858 | 2,066 | 1,828 | 1,518 | 1,045 |
| /aː/ | /oː/ | /uː/ | /iː/ | /eː/ | ||||
|---|---|---|---|---|---|---|---|---|
| 이집트어 | F1 | 585 | 405 | 305 | 295 | 385 | ||
| F2 | 1,780 | 880 | 790 | 2,365 | 2,215 |
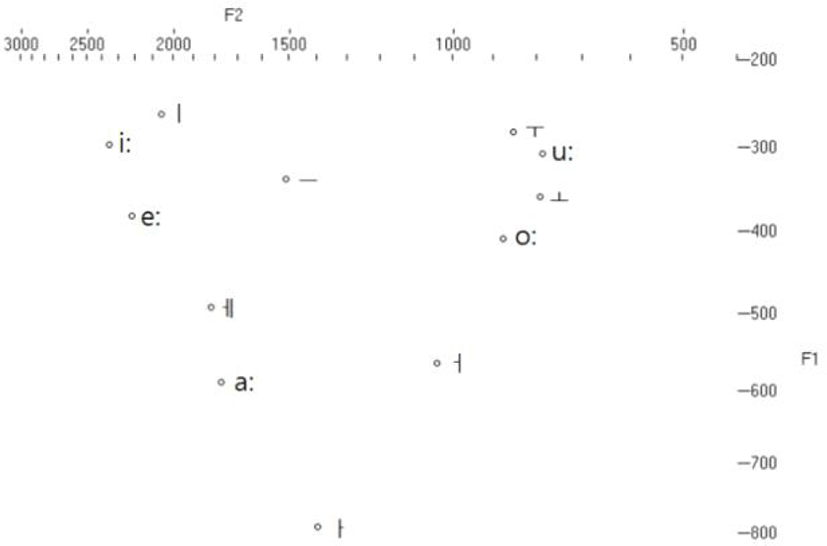
그림 2를 보면 한국어의 /ㅡ/와 /ㅓ/는 이집트인 학습자들에게는 이집트어에는 없는 새로운 모음으로 지각될 가능성이 높아 보이는데, 대부분의 외국인 한국어 학습자들이 /ㅓ/를 /ㅗ/로 혼동하는 경향이 있어(Lee & Park, 2011; Meutia & Kim, 2012; Paek, 2010; Zhao, 2006) 이집트인 학습자들도 /ㅓ/를 /ㅗ/로 범주화할 가능성도 있다. 이집트어의 /aː/는 포먼트 도표에서 한국어의 /ㅏ/보다는 /ㅔ/에 더 가까운데, 이집트인 학습자들이 한국어의 /ㅏ/와 /ㅔ/를 어떻게 범주화하는지 지각실험을 통해 살펴보아야 한다. 그리고 한국어의 /ㅗ/와 /ㅜ/는 대부분의 외국인들에게 구별하기 어려운 모음이라서 지각에서 혼동이 발생할 것으로 예측되므로 이 점도 지각실험을 통해 검증해 보아야 한다. 한국어의 /ㅣ/는 이집트어의 /iː/로 쉽게 범주화될 것으로 보이며, /ㅔ/는 이집트어의 /eː/로 동화될 가능성이 높아 보이지만 음향적으로 이집트어의 /aː/로 범주화되지는 않는지 지각실험을 통해 살펴볼 필요가 있다.
문어체 아랍어에는 이중모음이 2개(/aj, aw/) 있는데, 구어체에서 /aw/가 단모음 /o:/와 합류되어 사라졌다(Watson, 2002). /aw/와 /o:/의 합류로 인해 이집트어에서는 /o:/의 기능 부담량이 높아져 /u:/보다 출현 빈도가 더 높다.
이집트어에서는 모음 /a:/가 /e:/나 /i:/로 발음되는 특징적인 모음 상승 현상(예: /wa/→/we/)이 일어나기 때문에(Yoon, 2009) 이중모음 /we/가 존재한다. 그리고 반모음 /w/가 단모음 /i/와 결합하여 이중모음 /wi/로 실현된다(예: /tanwiːr/(지식)). 따라서 이집트 구어체 아랍어에는 이중모음을 3개(/aj, we, wi/) 설정할 수 있다.
한국어에는 12개의 이중모음 /ㅑ, ㅕ, ㅛ, ㅠ, ㅖ, ㅒ, ㅘ, ㅝ, ㅟ, ㅞ(ㅚ), ㅙ, ㅢ/가 있기 때문에(Lee, 1996), 이집트인 학습자는 많은 수의 한국어 이중모음들을 구별해서 지각하는 데 어려움을 겪을 가능성이 있다.
Eom(2018)은 이집트인 초급 학습자를 대상으로 한국어 모음 산출 실험을 하고, /ㅓ, ㅗ, ㅜ/와 /ㅡ, ㅣ/, 그리고 /ㅕ, ㅛ, ㅠ/와 /ㅚ, ㅢ/ 등의 산출에 문제가 있었다고 보고했는데, 이 역시 산출 실험을 통해 검증해 볼 것이다.
3. 실험1: 이집트인 학습자의 한국어 모음 지각
이 실험은 이집트인 한국어 학습자가 수준별로 한국어 모음을 어떻게 지각하고, 어떤 오류를 보이는지 파악하는 것을 목적으로 하여 진행되었다.
실험에 참여한 이집트인 학습자는 총 53명이었다. 피험자는 지각 실험에 참여하기 전에 설문조사에 참여했다. 학습자는 나이, 성별, 출생지, 모국어 등의 기본 정보와 한국어를 배우기 시작한 시점, 한국어를 배운 기간, 한국 거주 경험 여부, 수강하고 있는 한국어 강좌, 한국어 사용량, 배우기 어려운 한국어 발음 등에 관해 설문지에 대답하였다. 초급 학습자는 이집트 카이로의 A 대학교나 한국어 교육원에서 한국어를 학습하고 있는 31명의 학생들로 구성되었다. 나이는 18–35세였으며, 한국어 정규 교육 과정을 대학교 1–2학년까지 학습 중이었으며, 한국에 거주한 경험이 없었다. 설문조사 결과에 따르면 학교에서 <한국어문법>, <한국어 회화>, <한-아, 아-한 번역> 등의 한국어 수업을 수강하는 시간을 포함하여 1주일에 평균 11시간 정도를 한국어 학습에 할애했으며, 일상생활에서 한국어에 노출되는 시간은 거의 없었다(표 2).
중급 학습자는 이집트의 아인샴스대학교나 한국어 교육원에서 한국어를 학습하는 13명의 학생들이었다. 나이는 19–27세이며, 한국어 정규 교육과정을 3–4학년까지 학습 중이었으며, 한국에 거주한 기간이 0–6개월까지 다양했다. 설문조사 결과에 따르면 <한국어문법>, <한국어 회화>, <한-아, 아-한 번역> 등의 한국어 수업을 수강하는 시간을 포함하여 1주일에 평균 13시간 정도를 한국어 학습에 할애했으며, 일상생활에서 한국어에 노출되는 시간은 드라마를 보거나 한국 노래를 들을 때 정도였다.
고급 학습자는 모두 9명이었다. 이들은 이집트 아인샴스대학교에서 4학년까지 한국어 정규 교육과정을 모두 이수하고 한국에서 체류한 기간이 1년 내외이거나, 한국에서 대학원을 다니고 있거나 대학원을 졸업한 학습자들이었다. 한국어 학습 기간은 4년에서 13년까지였으며, 한국에서 거주한 기간은 평균 4.6년이었다. 학습자의 나이는 24–30세였다. 고급 학습자는 졸업하고 나서 한국어와 관련된 전문적인 직업에 종사하거나 연구를 진행하고 있어 한국어가 매우 능숙하며, 아랍어를 모국어로 가지고 있는 화자들 중에서 한국어를 가장 잘하는 집단으로 볼 수 있다. 고급 학습자 집단이 가장 오랜 기간 한국어 학습을 해 왔기 때문에 원어민과 근접한 발음을 가져야 하지만 실제로는 지각과 산출에서 어려움을 겪는 발음이 여전히 존재함을 볼 수 있었다. 따라서, 다른 연구와 달리 지각 실험을 실행할 때, 한국어를 학습 중인 초급이나 중급 학습자뿐만 아니라, 한국어과를 졸업하고 전문가가 된 학습자까지 실험에 포함시켜 이들의 한국어 발음 지각과 산출을 종합적으로 살펴보고자 한다.
이 논문에서 고급 학습자는 9명밖에 안 되었고, 실험 결과 중급 학습자 집단과 뚜렷한 차이가 관찰되지 않았기 때문에 고급과 중급 학습자를 한 집단으로 묶어 논의를 진행하도록 하겠다. 피험자들은 모두 카이로 표준어를 사용하는 학습자들이었다(표 2).
이 실험을 위해 Hwang(2017)에서 사용된 단어 목록을 참고하여 7개의 단모음을 포함한 단어 7개와 이집트인 학습자들에게 어려울 것으로 판단되는 이중모음 6개를 포함한 단어 6개를 자극 단어로 선정했고, 자연스러운 지각이 이루어질 수 있도록 1개의 자극(예: 게르다)을 제외하고는 모두 의미 있는 어휘들로 구성하였다(표 3).
| 구분 | 실험 단어 |
|---|---|
| 단모음 | 가르다-거르다-고르다-구르다-그르다-기르다-게르다 |
| 이중모음 | 요가-유가-여가-외가-위가-의가 |
지각 실험에 사용할 한국어 발음의 녹음에는 서울 출신의 20– 30대 여성 2명, 남성 1명이 참여했다. 13개의 실험 단어를 무작위로 섞은 리스트를 3번 읽게 하였고, 단어별로 가장 명료하게 발화된 것들을 선택하여 모두 39개 자극(13단어×3명)을 실험에 사용하였다. 녹음은 서울대학교 언어학과 녹음실에서 이루어졌고, 삼성 노트북 NT900X4D, 슈어(SHURE)사의 SM48S 마이크, 사운드 디바이스(Sound Devices)사의 USB Pre2 오디오 인터페이스를 사용하여 녹음하였다.
실험에 앞서, 이집트인 학습자들에게 실험에 대한 영어와 한국어 설명문이 제공되었으며, 간단 설문지를 작성하도록 했다. 이집트인을 대상으로 한 한국어 발음 지각 실험은 PRAAT ExperimentMFC를 이용해 자극 단어를 무작위로 제공했으며, 소리를 헤드폰으로 듣고 정답을 고르는 방식으로 진행되었다. 피험자가 소리를 잘못 들은 경우, 5번까지 다시 듣기를 할 수 있게 했다. 이집트인 학습자의 실력에 따라 10–20분의 시간이 소요되었으며, 중간에 휴식이 제공되었다. 실험 장비로는 휴렛 팩커드사의 HP 노트북 Pavilion 13-b225TU과 젠하이저사의 헤드폰(Sennheiser HD 202)을 사용하였다.
컴퓨터를 이용한 실험이기 때문에 학습자들은 이집트 아인샴스대학교의 편하고 조용한 장소에서 39개의 자극을 듣고 화면 상에 제공된 보기 중에서 들은 소리와 일치하는 단어를 고르도록 했다. 4개의 보기는 모음별로 혼동되기 쉬운 모음이 들어간 단어들로 구성했다. 지각 실험 분석 대상은 모두 2,067개(39 자극×53명)였다.
이집트인 학습자의 한국어 모음의 지각 양상은 표 4에 제시하였다. 전체적인 결과를 살펴보면 모음의 지각 정확도가 높게 나타났다.
| 초급(n=31) | 중고급(n=22) | |
|---|---|---|
| 평균 | 75.3 | 85.5 |
| 표준편차 | (11.0) | (9.4) |
이집트인 학습자들의 모음 지각 정확도를 모음 집단별로 집계한 결과를 표 5에 제시하였다. 이집트인 학습자들은 다른 외국인 학습자들과 마찬가지로 /ㅓ, ㅗ, ㅜ/와 /ㅕ, ㅛ, ㅠ/를 구별해서 지각하는 데 다른 모음들에 비해 어려움을 더 많이 겪기 때문에 이 모음들을 별도의 두 집단으로 설정하고 /ㅏ, ㅡ, ㅔ, ㅣ/ 집단과 /ㅚ, ㅟ, ㅢ/ 집단과의 지각 정확도 차이를 볼 수 있게 표를 만들었다. 또한 표 5를 보면 학습 기간에 따른 지각 능력 향상도 확인할 수 있다.
| 초급 | 중고급 | ||
|---|---|---|---|
| 단모음 | /ㅓ, ㅗ, ㅜ/ | 60.2 | 75.2 |
| /ㅏ, ㅡ, ㅔ, ㅣ/ | 87.3 | 96.2 | |
| 이중모음 | /ㅕ, ㅛ, ㅠ/ | 70.2 | 79.7 |
| /ㅚ, ㅟ, ㅢ/ | 79.5 | 87.3 |
통계적으로 학습자 집단에 따른 지각 정확도의 차이를 알아보기 위해 모음 집단(/ㅓ, ㅗ, ㅜ/, /ㅏ, ㅡ, ㅔ, ㅣ/, /ㅕ, ㅛ, ㅠ/, /ㅚ, ㅟ, ㅢ/)과 학습자 집단을 고정효과로 하고, 종속변수를 점수(0과 1)로, 무작위 효과의 변수로 피험자와 자극단어를 설정하여 혼합효과 로지스틱 회귀분석을 실시하였다. 그 결과 중고급 집단이 초급 집단보다 모음 지각 정확도가 유의미하게 높은 것으로 나타났다[χ²(1)=13.187, β=0.611, SE=0.246, z=2.486, p<0.01]. 모음 집단에 따른 차이도 유의미하게 나타났는데[χ²(1)=11.9021, β=1.101, SE=0.131, z=8.367, p<0.01], /ㅓ, ㅗ, ㅜ/와 /ㅕ, ㅛ, ㅠ/보다 /ㅏ, ㅡ, ㅔ, ㅣ/와 /ㅚ, ㅟ, ㅢ/의 모음 지각 정확도가 더 낮았다[χ²(1)=13.961, β=1.165, SE=0.334, z=3.484, p<0.001]. 그러나 단모음과 이중모음의 지각 정확도는 유의미하게 다르지 않았다[χ²(1)=0.418, β=0.215, SE=0.486, z=0.442, p<0.1]. 단모음 /ㅏ, ㅔ, ㅡ, ㅣ/ 집단이 /ㅓ, ㅗ, ㅜ/ 집단보다 유의미하게 높은 것으로 나타났다[χ²(1)=18.322, β=1.69, SE=0.435, z=3.989, p<0.001]. 이중모음 /ㅕ, ㅛ, ㅠ/와 /ㅚ, ㅟ, ㅢ/ 집단은 유의미하게 다르지 않았다[χ²(1)=2.479, p<0.1].
위의 표 6은 개별 모음의 지각 정확도를 학습자 수준별로 보여준다. 이집트인 학습자가 가장 잘 지각한 모음은 /ㅏ/, /ㅔ/, /ㅚ/였다. 앞에서도 언급했듯이(그림 2) 한국어 /ㅔ/가 포먼트 도표 상에서 이집트어의 /aː/에 가까워 한국어의 /ㅏ/와 /ㅔ/가 이집트어의 어느 모음에 동화되는지 궁금했는데, 한국어 /ㅏ/는 이집트어 /aː/에 쉽게 동화되었고, /ㅔ/는 음가가 제법 차이가 나는 이집트어의 /eː/에 동화되었다. 한국어 /ㅣ/는 이집트어 /iː/와 음가가 매우 비슷해 쉽게 동화될 것으로 보았으나 생각보다는 덜 동화되었다.
| 모음 | 초급 | 중고급 | |
|---|---|---|---|
| 단모음 | /ㅏ/ | 95.6 | 100 |
| /ㅡ/ | 89.2 | 93.9 | |
| /ㅣ/ | 81.7 | 92.4 | |
| /ㅔ/ | 82.7 | 98.4 | |
| /ㅓ/ | 67.7 | 74.2 | |
| /ㅗ/ | 45.1 | 66.6 | |
| /ㅜ/ | 67.7 | 84.8 | |
| 이중모음 | /ㅕ/ | 80.6 | 81.8 |
| /ㅛ/ | 55.9 | 72.7 | |
| /ㅠ/ | 74.1 | 84.8 | |
| /ㅟ/ | 75.2 | 80.3 | |
| /ㅚ/ | 82.7 | 98.4 | |
| /ㅢ/ | 80.6 | 83.3 |
이집트어에는 이중모음 /wi/와 /we/가 존재하기 때문에 한국어의 /ㅟ/와 /ㅚ/는 쉽게 지각될 것으로 예측되었는데, /ㅚ/는 /we/와 잘 동화되어 쉽게 지각되었으나 /ㅟ/는 /wi/에 생각보다 잘 동화되지 않아 다소 저조한 지각 정확도를 보였다.
한국어 /ㅡ/는 거의 모든 외국인들에게 매우 생소한 새로운 모음이라 SLM에 따르면 쉽게 별개의 음소로 범주화되고 잘 지각될 것으로 예측하였는데, 예측한 대로 상당히 잘 지각되었다. 반면에 모음 /ㅡ/와 이중모음 /ㅢ/도 별도의 범주로서 형성된 것으로 보이지만 지각 정확도는 /ㅡ/보다 많이 저조했다.
이집트인 학습자들이 지각에 가장 어려워한 단모음은 /ㅓ, ㅗ, ㅜ/였다. 이집트인 학습자들뿐만 아니라 거의 대부분의 외국인 학습자들이 /ㅗ/와 /ㅜ/를 구별하여 지각하는 것을 매우 어려워하고, /ㅗ/를 /ㅜ/로 지각하는 경우가 많았다(Hwang, 2017; Lee, 2016; Park, 2010). 이는 언어마다 /o/와 /u/의 음가가 다르게 실현되고, 한국어에서 /ㅗ/와 /ㅜ/의 음가가 매우 근접해 있기 때문인 것으로 해석된다. 일본인이나 중국인 학습자들이 /ㅓ/와 /ㅗ/를 잘 구별하지 못하는 사실도 여러 연구에서 보고되었다(Lee & Park, 2011; Meutia & Kim, 2012; Paek, 2010; Zhao, 2006). 이집트인 학습자들이 단모음 /ㅓ, ㅗ, ㅜ/를 잘 구별해서 지각하지 못하기 때문에 이중모음 /ㅕ, ㅛ, ㅠ/도 잘 구별해서 지각하지 못했다.
아래의 표 7−9에 정리한 /ㅓ, ㅗ, ㅜ/, /ㅕ, ㅛ, ㅠ/, /ㅚ, ㅟ, ㅢ/의 지각 혼동 행렬을 보면 이집트인 학습자들이 이 모음들을 어떻게 범주화하는지 파악할 수 있다.
| 자극\응답 | /ㅓ/ | /ㅗ/ | /ㅜ/ | |
|---|---|---|---|---|
| /ㅓ/ | 초급 | 67.7 | 34.5 | |
| 중고급 | 74.2 | 25.7 | ||
| /ㅗ/ | 초급 | 15.0 | 45.1 | 37.6 |
| 중고급 | 1.5 | 66.6 | 31.8 | |
| /ㅜ/ | 초급 | 5.3 | 15.1 | 67.7 |
| 중고급 | 12.1 | 84.8 | ||
위의 표 7을 보면 이집트인 학습자들은 한국어의 /ㅜ/를 대체로 이집트어의 /uː/로 범주화하지만 /oː/로 범주화하는 사람들이 다소 있는 것을 알 수 있다. 한국어의 /ㅗ/는 이집트인 학습자들에게 가장 어려운 모음인데, /oː/로 범주화하는 사람이 가장 많고, /uː/로 범주화하는 사람도 꽤 많았다. 한국어의 /ㅓ/는 이집트어의 /oː/와 음가가 많이 달라 별도의 모음으로 범주화되었지만 제법 많은 사람들이 /oː/로 범주화했다.
위의 표 8에서 보듯이, 이중모음 /ㅕ, ㅛ, ㅠ/의 지각 정확도도 단모음 /ㅓ, ㅗ, ㅜ/의 지각 정확도와 대체로 비슷하게 나타났다. 중고급 학습자들도 /ㅕ, ㅛ, ㅠ/의 지각 정확도가 72.7%–84.8% 수준에 불과해 학습 기간이 늘어나도 이중모음 /ㅕ, ㅛ, ㅠ/의 지각은 크게 향상되지 않음을 확인할 수 있었다. 단모음 /ㅗ/가 가장 낮은 지각 정확도를 보였듯이, 이중모음 /ㅛ/도 초급 학습자의 지각 정확도가 55.9%에 불과했다.
| 자극\응답 | /ㅕ/ | /ㅛ/ | /ㅠ/ | |
|---|---|---|---|---|
| /ㅕ/ | 초급 | 77.4 | 22.5 | 0 |
| 중고급 | 81.8 | 18.1 | 1.5 | |
| /ㅛ/ | 초급 | 21.5 | 55.9 | 22.5 |
| 중고급 | 10.6 | 72.7 | 3.0 | |
| /ㅠ/ | 초급 | 6.4 | 16.1 | 74.1 |
| 중고급 | 3.0 | 12.1 | 84.8 | |
위의 표 9를 보면 한국어의 /ㅚ/와 /ㅟ/는 이집트어의 /we/, /wi/에 동화되었다는 사실을 알 수 있고, 이집트인 학습자들에게 새로운 이중모음인 /ㅢ/도 SLM에서 예측하는 대로 새로운 이중모음으로 범주화된 것을 확인할 수 있다.
| /ㅚ/ | /ㅟ/ | /ㅢ/ | ||
|---|---|---|---|---|
| /ㅚ/ | 초급 | 82.7 | 11.8 | 5.3 |
| 중고급 | 98.4 | 1.5 | ||
| /ㅟ/ | 초급 | 18.2 | 75.2 | 6.4 |
| 중고급 | 6.0 | 83.3 | 12.1 | |
| /ㅢ/ | 초급 | 3.2 | 17.2 | 80.6 |
| 중고급 | 1.5 | 12.1 | 83.3 |
이상의 논의를 토대로 이집트인 학습자들이 한국어 단모음을 어떻게 범주화했는지 도식화하면 다음과 같다. 선의 굵기는 동화의 강도를 나타낸다.
한국어의 모음 /ㅣ, ㅔ, ㅏ/는 이집트어의 /iː, eː, aː/와 매우 비슷해 일대일로 동화되며(two category assimilation), 한국어의 /ㅗ, ㅜ/는 이집트어의 /oː, uː/와 비슷하기는 하지만 서로 혼동되어 한국어의 /ㅗ, ㅜ/는 /oː/에 동화되기도 하고(single category assimilation의 성격), /uː/에 동화되기도 한다(category goodness assimilation). 한국어의 /ㅡ/는 이집트어에 동화될 만한 비슷한 모음이 없어 별개의 모음으로 범주화되며, /ㅓ/도 대부분의 이집트인 학습자들에게는 새로운 모음이어서 새로운 모음으로 범주화되지만 일부 학습자들은 /oː/로 범주화한다(표 10).
| 한국어 모음 | 이집트 모음 |
|---|---|
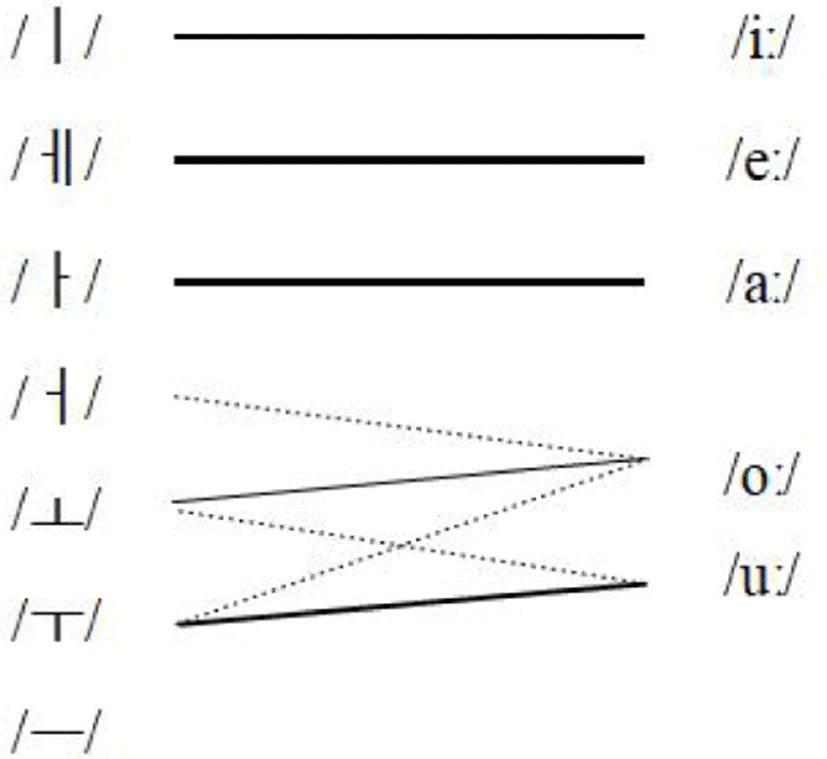
|
|
4. 실험 2: 이집트인 학습자의 한국어 모음 산출
이 실험은 한국인이 이집트인 학습자가 산출한 한국어 모음을 듣고 어떻게 지각하는지, 지각된 한국어 발음과 얼마나 유사한지 측정하는 것을 목적으로 한다. 그리고 이 실험의 결과와 실험 1의 결과를 바탕으로 지각과 산출 간의 관계를 파악하고자 한다.
산출 실험 자료 녹음에는 이집트 아인샴스대학교에서 한국어를 학습 중인 재학생과 한국어과를 졸업한 이집트인 학습자 9명이 피험자로서 참여하였다. 이들 중 4명은 초급 학습자였고, 5명은 중고급 학습자였다. 이들은 모두 실험 1에 참여한 피험자였다(표 11).
이집트인 학습자가 산출한 한국어 모음을 듣고 평가하는 실험에는 한국인 피험자 8명(여자 6명, 남자 2명)이 참여했다. 이들은 모두 한국어를 모국어로 하는 언어학 전공자이며, 청각장애, 감각신경성 장애나 지적 장애, 언어장애가 없는 20–30대 학생이었다.
실험 2에 사용한 실험 단어 목록은 실험1에서 사용한 13개의 실험 단어 목록과 똑같으며, 47개의 위장 단어(filler)를 포함하여 모두 60개의 단어를 가지고 녹음하였다. 이집트인 피험자들에게 60개 단어를 4번 반복하여 발화하게 했으며, 녹음 소요 시간은 10분에서 15분 정도였다.
녹음은 이집트 카이로에 있는 전문 녹음실에서 이루어졌고, 매킨토시사의 Mac OS X 10.6.8 v1.1 컴퓨터, 뉴먼(Neumann)사의 TLM 49 마이크, Pro Tools HD 10.0 software와 DigiDesign사의192 I/O Analog Digital Recording Interface를 이용하여 24 bit/44.1 kHz로 녹음했다.
실험에 앞서 한국인 피험자들에게 실험에 대한 설명문을 제공하여 읽게 했다. 한국인을 대상으로 한 이집트인 학습자의 한국어 발음 산출 평가 실험은 PRAAT ExperimentMFC를 이용해 실시하였으며, 자극 단어를 무작위로 제공했다. 서울대학교의 조용한 연구실에서 한국인 피험자들은 이집트인 학습자들이 발음한 한국어 117(13개×9명)개 단어를 헤드폰을 통해 하나씩 듣고 컴퓨터 화면에 제시된 4개의 보기 중에서 어느 단어로 들렸는지 고르도록 했다(identification task). 4개의 보기는 모음별로 혼동되기 쉬운 모음이 들어간 단어들로 구성했다. 각 구별 과제 문제를 푼 다음 자신이 들은 단어의 모음이 자신이 선택한 단어의 원어민 모음 음가와 얼마나 유사한지 평가해 1–5점(5점이 원어민 수준) 사이의 점수 하나를 고르도록 했다(goodness rating). 각 자극 단어는 5번까지 반복하여 들을 수 있었으며, 발음 평가 소요 시간은 20–30분 정도였다. 중간에 약간의 휴식 시간이 제공되었다. 분석 대상은 모두 936개였다(117개×8명). 실험 장비로는 휴렛 팩커드사의 HP 노트북 Pavilion 13-b225TU와 젠하이저사의 헤드폰을 사용하였다.
이집트인 학습자들의 모음 산출 정확도를 아래 표 12에 제시하였다. 한국어 모음의 산출 정확도는 중고급 학습자 집단이 뚜렷하게 높았다. 학습 기간이 길어지면서 산출 정확도도 향상되었음을 알 수 있다.
| 초급(n=4) | 중고급(n=5) | |
|---|---|---|
| 평균 | 67.0 | 81.7 |
| (표준편차) | (5.0) | (3.6) |
한국어 원어민이 평가한 이집트인 학습자의 모음 산출 정확도를 다음의 표 13에서 살펴보면 단모음 /ㅓ, ㅗ, ㅜ/의 산출 정확도는 초급 집단 60.4%, 중고급 집단 63.3% 정도였고, /ㅣ, ㅔ, ㅏ, ㅡ/의 산출 정확도는 초급 집단 82.8%, 중고급 집단 99.2% 정도였다. /ㅓ, ㅗ, ㅜ/의 경우 중고급 집단이 초급 집단보다 별로 나은 점이 없을 정도로 산출 정확도가 저조한 반면 /ㅣ, ㅔ, ㅏ, ㅡ/는 학습 기간에 따른 산출 정확도 향상이 눈에 띄었다. 이중모음 /ㅕ, ㅛ, ㅠ/와 /ㅚ, ㅟ, ㅢ/의 산출 정확도는 초급 집단에서 각각 54.1%와 65.0%로 나타났고, 중고급에서는 65.6%와 93.9%로 나타나 학습 기간에 따라 이중모음의 산출 능력 향상이 이루어졌음을 알 수 있으며, /ㅕ, ㅛ, ㅠ/는 /ㅓ, ㅗ, ㅜ/와 마찬가지로 중고급 집단에서도 산출 정확도가 상당히 낮게 나타났다.
| 초급 | 중고급 | ||||
|---|---|---|---|---|---|
| 정확도 | 유사도 | 정확도 | 유사도 | ||
| 단모음 | /ㅓ, ㅗ, ㅜ/ | 60.4 | 2.1 | 63.3 | 3.5 |
| /ㅏ, ㅡ, ㅔ, ㅣ/ | 82.8 | 2.5 | 99.2 | 3.4 | |
| 이중모음 | /ㅕ, ㅛ, ㅠ/ | 54.1 | 3.6 | 65.0 | 3.6 |
| /ㅚ, ㅟ, ㅢ/ | 65.6 | 2.7 | 93.9 | 3.4 | |
모음 집단과 학습자 집단에 따라 산출 정확도가 통계적으로 의미 있게 차이가 나는지 알아보기 위해 모음 집단과 학습자 집단을 고정효과로 하고, 종속변수를 점수(0, 1)로 하여 혼합 효과 로지스틱 회귀분석을 실시한 결과 단모음과 이중모음 사이의 차이는 유의미하지 않았으나[χ²(1)=0.002, β=0.998, SE=0.99, z=1.008, p<0.1], /ㅓ, ㅗ, ㅜ/와 /ㅣ, ㅔ, ㅏ, ㅡ/ 간의 차이는 유의미하여[χ²(1)=9.23462, β=1.274, SE=0.199, z=6.375, p<0.001] 이집트인 학습자들은 /ㅓ, ㅗ, ㅜ/보다는 /ㅣ, ㅔ, ㅏ, ㅡ/을 더 잘 발음했음을 알 수 있었다. 실험 1에서 언급했듯이 이집트인 학습자들은 한국어 /ㅓ, ㅗ, ㅜ/보다 /ㅣ, ㅔ, ㅏ, ㅡ/를 더 잘 지각했는데, 이 경향은 산출에도 그대로 이어졌다. 이중모음 /ㅕ, ㅛ, ㅠ/ 집단과 /ㅚ, ㅟ, ㅢ/ 집단의 산출 정확도는 유의미하게 다르지 않게 나타났다[χ²(1)=1.148, p<0.1]. 집단에 따른 산출 정확도의 차이는 유의미해[χ²(1)=5.217, β=0.83356, SE=0.15901, z=5.242, p<0.001], 중고급 집단이 초급 집단보다 모음을 더 잘 발음한 것으로 나타났다.
표 14를 살펴보면 이집트인 학습자의 한국어 모음 산출 정확도는 전반적으로 높은 수준이었다. 특히 /ㅏ, ㅡ, ㅣ, ㅔ, ㅟ, ㅚ/의 경우 중고급 학습자들의 산출 정확도가 97.5%–100%에 이를 정도로 정확하게 발음되었다. /ㅔ, ㅚ/의 경우 초급 단계에서는 산출 정확도가 매우 떨어졌으나 중고급 단계에서 100%에 도달한 점은 주목할 만하다. 반면에 이집트어에 없는 /ㅓ, ㅕ/는 산출 정확도가 가장 떨어진 반면 /ㅢ/는 중고급 단계에서 80%에 도달할 정도로 산출 정확도가 크게 향상되었다. 실험 1의 지각 실험에서 /ㅗ/와 /ㅜ/는 지각 정확도가 매우 떨어졌으나 산출 실험에서는 정확도가 꽤 높은 점도 주목할 만하다. 이집트어 /o:, u:/의 발음이 한국어의 /ㅗ, ㅜ/와 차이가 나고 한국어에서 /ㅗ, ㅜ/의 음가가 가깝기 때문에 이집트인 학습자들이 한국어의 /ㅗ, ㅜ/를 구별해서 지각하는 데 어려움을 겪는 반면 한국어의 /ㅗ, ㅜ/를 이집트어의 /o:, u:/로 발음하면 한국인들은 대체로 한국어의 /ㅗ, ㅜ/로 지각한다는 것을 의미한다.
5. 종합 논의: 지각과 산출과의 관계
실험 1과 실험 2에서는 이집트인 학습자가 한국어 모음을 어떻게 지각하고 산출하는지를 밝혔다. 전체적인 결과를 보면 이집트인 학습자는 한국어 모음의 산출보다 지각을 더 잘하는 것을 알 수 있다(표 15).
| 초급 | 중고급 | ||
|---|---|---|---|
| 지각 | 산출 | 지각 | 산출 |
| 75.3 | 67.0 | 85.5 | 81.7 |
통계적으로 지각과 산출이 어떤 관계를 가지고 있는지 판단하기 위해 혼합 로지스틱 회귀분석을 실시하였다. 실험(산출, 지각)과 집단(초급, 중고급)을 고정효과로 하고 응답 점수(0, 1)를 종속변수로, 피험자와 자극 단어를 무작위 효과로 설정하였다. 그 결과 실험과 집단에 따른 주효과는 매우 유의미하게 나타났으며[χ²(1)=60.554, β=0.764, SE=0.126, z=6.044, p<0.01], 상호작용도 유의미했다[χ²(1)=4.13, p<0.05]. 이는 지각과 산출 정확도가 의미 있게 다르며 초급과 중고급 학습자들 간의 점수 차도 의미가 있었음을 보여준다.
이집트인 초급 학습자와 중고급 학습자의 한국어 단모음과 이중모음 지각과 산출 양상을 다음의 표 16과 표 17에서 비교해 보면, 두 집단 모두 지각과 산출에서 비슷한 양상을 보였다. 이집트인 학습자들은 이집트어의 대응 모음과 매우 비슷하고 일대일 대응(two category assimilation)을 보이는 /ㅏ, ㅔ, ㅣ/는 지각과 산출이 모두 잘 되었고, 이집트어에 비슷한 모음이 없는 /ㅡ/는 새로운 음소로 쉽게 범주화되어 지각과 산출이 모두 잘 되었다. 그러나 /ㅓ/의 경우 이 모음을 새로운 모음으로 범주화하는 사람들도 있고, 이집트어의 /oː/로 범주화하는 사람들도 있어 지각 정확도가 대체로 저조했으며, 산출 정확도는 한국어 모음들 중에서 가장 떨어졌다.
한국어의 /ㅗ/는 이집트어의 /oː/로 범주화하는 학습자가 더 많기는 하지만 /uː/로 범주화하는 학습자가 상당수 있어(single category assimilation – category goodness assimilation) 모음들 중 지각 정확도가 가장 떨어졌다. 반면에 한국어의 /ㅜ/를 이집트어의 /uː/로 범주화시키는 학습자가 /oː/로 범주화시키는 학습자가 훨씬 많아(category goodness assimilation) /ㅜ/가 /ㅗ/보다 더 잘 지각되고 산출되었다. 그러나 초급 학습자들의 경우 /ㅜ/보다 /ㅗ/를 더 잘 발음한 것으로 나타났다.
한국어 /ㅚ, ㅟ/는 거의 같은 음가를 가진 이집트어 이중모음 /we, wi/와 일대일로 범주화되어(two category assimilation) 상당히 잘 지각되고, 중고급 학습자의 경우 완벽하게 발음했다. 어떤 이유에서인지 모르겠으나 /ㅚ/가 /ㅟ/보다 더 잘 지각되었으며, 초급 학습자들의 /ㅚ/ 산출 정확도는 40.6%에 불과했다.
이집트어에 대응되는 이중모음이 없어 이집트인들에게 매우 이국적인 이중모음 /ㅢ/의 경우 지각은 제법 잘 되었지만 /ㅡ/와는 달리 산출 정확도는 상당히 저조하였다. ‘다름’의 정도가 지나치면 새로운 범주를 형성하더라도 불완전하게 범주화되어 지각도 다소 떨어지고, 산출은 매우 어려운 것으로 보인다.
이중모음 /ㅕ, ㅛ, ㅠ/의 지각과 산출은 단모음 /ㅓ, ㅗ, ㅜ/의 지각, 산출과 매우 유사한 양상을 보였다.
지금까지 논의한 이집트인 학습자들의 한국어 모음 지각 정확도와 산출 정확도 내용을 바탕으로 지각과 산출과의 관계를 정리하면 다음과 같다. 지각에서 어려움을 겪은 모음 집단들은 ‘△’로 표시했으며, 산출에서 특별히 어려움을 겪은 모음들은 ‘×’로 표시했다(표 18).
| 모음 집단 | 이집트어 대응 음소와의 유사성 | 지각 | 산출 | |
|---|---|---|---|---|
| 단모음 | /ㅗ, ㅜ/ | 비슷한 | △ | △ |
| /ㅓ/ | 다른/비슷한 | △ | × | |
| /ㅏ, ㅔ, ㅣ/ | (거의) 같은 | ○ | ○ | |
| /ㅡ/ | 다른 | ○ | ○ | |
| 이중모음 | /ㅛ, ㅠ/ | 비슷한 | △ | △ |
| /ㅕ/ | 다른/비슷한 | △ | × | |
| /ㅟ, ㅚ/ | (거의) 같은 | ○ | ○ | |
| /ㅢ/ | 다른 | △ | △ |
6. 결론
이상에서 이집트인 학습자들이 한국어의 단모음과 이중모음을 어떻게 지각하고, 어떻게 산출하는지 두 가지 실험을 통해 살펴보고, 지각과 산출과의 관계를 논의했다.
이집트인 학습자들은 이집트어의 대응 모음과 음가가 매우 비슷하고 일대일로 동화되는 모음 /ㅏ, ㅔ, ㅣ, ㅟ, ㅚ/를 매우 잘 지각하고 산출했으며, 이집트어에 없는 새로운 모음인 /ㅡ/는 별개의 모음으로 범주화되어 지각과 산출 모두 잘 되었다. 그런데 이집트어에 없는 매우 새로운 이중모음 /ㅢ/는 /ㅡ/보다 훨씬 저조하게 지각되고 산출되었다. ‘다름’의 정도가 너무 커 지각과 산출에 어려움이 있었던 것으로 보인다. /ㅓ/는 학습자에 따라 새로운 모음으로 범주화되기도 하고, 이집트어의 /oː/에 동화되기도 해 전반적으로 지각 정확도가 떨어졌으며, 산출 정확도는 모음들 중에서 가장 떨어졌다.
한국어 /ㅗ/는 이집트어의 /oː/에 동화되기도 하고, /uː/에 동화되기도 해 이집트인 학습자들에게는 가장 지각하기 어려운 단모음이었으며, 산출 정확도도 /ㅓ/ 다음으로 가장 저조했다. /ㅜ/는 상당히 많은 학습자들이 이집트어의 /uː/로 범주화했지만 /oː/로 범주화한 사람들도 있어 /ㅗ/보다는 잘 지각되고 산출되었지만 어느 정도 어려움이 있음을 확인할 수 있었다.
한국어의 이중모음 /ㅚ, ㅟ/는 이집트어의 /we, wi/와 음가가 매우 비슷해 중고급 집단에서는 거의 완벽하게 지각되고 산출되었는데, 초급 집단에서는 의외로 지각과 산출에 어려움이 있었다. 어떤 이유에서인지 모르겠으나 /ㅚ/가 /ㅟ/보다 더 잘 지각되었으며, 초급 집단의 /ㅚ/ 산출 정확도는 40.6%로 매우 저조했다. 이중모음 /ㅕ, ㅛ, ㅠ/의 지각과 산출은 /ㅓ, ㅗ, ㅜ/의 지각, 산출과 매우 유사한 양상을 보였다.
이집트인 학습자들의 한국어 모음 지각 양상은 SLM과 PAM으로 설명할 수 있었으며, 모음 지각 양상은 산출에서도 비슷하게 관찰되었는데, 어느 정도의 지체 현상이 관찰되었다. SLM과 PAM은 제2언어 음성 지각과 관련해서 상당히 통찰력 있는 설명을 제공하는 것을 확인할 수 있었으며, 이 두 모델이 어느 정도의 수정을 하면 제2언어 음성 산출 양상도 설명할 수 있다는 확신을 제공해 주었다. 이 연구를 자음에까지 확장시키고, 여러 언어에까지 확장시키면 제2언어 음성 산출을 설명할 수 있는 모델을 수립할 수 있을 것으로 보인다.