





1. Introduction
When acquiring second language (L2) phonemes, phonological characteristics of the L2 learner’s native language (L1) greatly influence on the acquisition of L2 sound system. For example, several studies have argued that the presence or absence of stress pattern in learners’ native language determine the learnability of L2 stress pattern (Stress Parameter Model: Dupoux, et al., 2001; Dupoux, et al., 2008). However, other studies have also found that, if a phonological prosodic contrast exists in L2 learners’ L1, such as lexical tone, then, L2 learners are less constrained to use those cues (e.g., F0) to implement stress in L2 (See Vietnamese learners of English in Nguyen & Ingram, 2005; Nguyễn, et al., 2008; Chinese learners of English in Lai, 2008; Shen, 1993; Qin et al., 2017; Zhang et al., 2008).
In Korean, all these three clues (F0, intensity, duration) to implement English stress are also used in higher level prosody. Korean does not have stress (Lee & Jongman, 2019) but has phrasal-level prominence that is expressed with F0, intensity, and duration (Jun, 1993; Jun, 1995). Although F0 is mainly used to express accentual phrase (AP) pattern (e.g., L(H)HLH pattern in 4 syllable phrase), both intensity and duration are also used to mark AP boundary as well (e.g., so the final syllable has high intensity and long duration). Duration is also used at the sentence final position to mark intonational phrase (IP) boundary (e.g., so the sentence final syllable has the longest duration). Therefore, in Korean higher-level prosody, F0 is used the most frequently as compared to other two suprasegmental cues.
Lee, et al. (2006) examined the production of Korean-English bilingual speakers and found that late bilingual speakers used F0 as well as native speakers in speaking English stress, but not intensity nor vowel duration. If the native-likeness use of F0 by late Korean-English bilingual speakers is due to the frequency of the occurrence of F0 in Korean prosody, it can be predicted that Korean L2 speakers will also show a similar pattern in acquiring English stress.
Kang & Kim (2016) also examined Korean learners’ perception on English nonceword in which 3 suprasegmental cues were manipulated in 5 steps and found Korean learners weighted F0 more strongly than other two cues.
Then, what about the cue that does not exist in learner’s native prosody? In the case of the vowel reduction in unstressed syllable, we might be able to predict that Korean learners of English will not be able to acquire vowel reduction at all because Korean does not have vowel reduction (Lee & Jongman, 2019). A similar result was also found from Lin et al. (2013) such that Korean listeners were not facilitated by vowel reduction cue in the stimuli when performing a lexical decision task (e.g., ‘human’ ['hju.mən] vs. nonword [hju'mæn]). These results might indicate that only the perceptual cues existing in learners’ L2 phonological system will be easily acquired, due to L2 learners perceptual exposure in their L1.
Therefore, the purpose of this study is to investigate which perceptual cues Korean learners of English weight the most when perceiving English lexical stress. If the similarity between English and Korean phonological system determines the learnability of English lexical stress, like Stress Parameter Model suggests, Korean learners of English will not be able to perceive English stress at all. On the other hand, if the perceptual exposure of cues in learners’ L1 can facilitate English lexical stress, Korean learners of English will be able to weight suprasegmental cues F0 the most, followed by intensity and duration.
2. Methodology
A total of 27 subjects participated in this experiment. Thirteen subjects in the experimental group were Korean learners of English, all of whom were born and raised in the Seoul or near Seoul area. The average age of Korean group was 23.4 years old (SD=2.5) and the age at which they learned English was 9 years old (SD=2.5). None of the Korean group had ever lived in an English-speaking country, and the average score on the Michigan proficiency test (2003) was 37.9 (out of 45, SD=2.5), which indicate all of them were upper-intermediate to advanced level of English.
The 14 subjects in the control group were English native speakers who were born and raised Midwest region of the United States (mean age=21.4, SD=2.4). None of the subjects had lived abroad or lived for a long time. None of the subjects had a hearing or speech impairment.
An English stressed minimal pair, OBject-obJECT (capital letters indicate stressed syllables), was selected as the base token. Initially, this word was produced and recorded 5 times by 5 native speakers for the experiment recording. At first, the word was produced in the contextually-related sentences to induce the intended stress, and then the word was produced in context-neutral sentences (Lai, 2008). And finally, the word was produced in word-isolation. Among these ‘object’ pairs, the token with the largest spectral difference between the stressed syllable and the unstressed syllable was selected. And, as basic tokens for the stimuli manipulation, the first syllable of noun utterance (‘OB’) and the second syllable of verb utterance (‘JECT’) were selected, respectively. It was to preserve, and also to reduce the probability of distorting acoustic information by artificially lengthening short vowels (ex. ject to JECT). F1, F2 and F3 values on the first syllable, were manipulated to reduce the vowel quality, and the suprasegmental cues (vowel length, F0, intensity) of the first and second syllables were also manipulated.
Based on the F1, F2, and F3 values of the stressed syllables ‘OB’ and ‘JECT’, five step continua from /ɑ/ to /ə/ vowels were artificially created, by using line spectral frequencies interpolation in Matlab (Ver. R2014a). For the manipulation of suprasegmental cues (vowel duration, F0, intensity), based on the maximum and minimum values of all the tokens across all five male speakers, we created five steps of each segmental cue, referring Zhang & Francis (2010). The manipulation procedure of duration, F0, and intensity was conducted by setting the onset and offset of periodicity of the vowels in the Duration manipulation tier of Praat to extract the Duration Tier. Then, the vowel duration was multiplied with a manipulation factor for each step. Tables 1 and 2 represent the detailed manipulation values of the five steps of the duration, F0, and intensity of the first and the second syllables, respectively.
In order to investigate which perceptual cues affected listeners’ perception, we manipulated only two cues in one condition. Since vowel reduction occurs in the first syllable, vowel quality and one suprasegmental cue were always manipulated (e.g., Vowel Quality × Vowel Duration). In this case, the remaining two suprasegmental cues were manipulated to be neutral (F0 and intensity at step 3). When the first syllable is manipulated, the second syllable is always in the middle value of the maximum and minimum values (step 3). When the second syllable was manipulated, since the vowel quality of the first syllable had already been manipulated to be neutral (step 3), only one suprasegmental cue of the second syllable was manipulated. Thus, the experimental stimuli were controlled to be manipulated only two cues at one time.
Therefore, a total of 75 experimental stimuli with the first syllable manipulated, Vowel Quality and Vowel Duration (5 step × 5 step). Vowel Quality and F0 (5 step × 5 step), Vowel Quality and Intensity (5 step × 5 step) conditions. The number of experimental stimuli in which the second syllable was manipulated was 15, while the vowel quality of the first syllable was controlled to be steps 3 (5 steps of duration + 5 steps of intensity + 5 steps of F0). While creating experimental words, 10 identical tokens were created in duplicate in the first syllable condition and 2 duplicated tokens in the second syllable condition. Excluding these tokens, a total of 78 experimental words were generated. Therefore, for each experimental condition, one spectral cue (Vowel Quality step 1– step 5) and one suprasegmental cue (step 1– step 5) were manipulated in an orthogonal manner.
All the participants completed English stress judgment task. Only Korean learners performed the Michigan English Proficiency Test (University of Michigan, 2003) task prior to the main experiment task. In the English stress judgment task, the participants listened to the sentence ‘please say object again’ and were asked to identify whether the played word ‘object’ is either first syllable stressed word or second syllable stressed word. The experiment was performed by pressing either the [q] button (first syllable stressed word) or [p] button (second stressed word) on the keyboard. The order of the [q] and [p] buttons on the keyboard is counterbalanced.
The experiment consisted of a total of 3 blocks, and 78 experimental stimuli were played in a randomized order in each block. Therefore, in this perceptual experiment, a total of 234 experimental words (78 experimental words × 3 repetitions) were played, and the intertrial interval was 1,500 ms. Before the main experiment started, the subjects had time to practice with 12 trial tokens, and they were also allowed to take a short break after each block.
In order to investigate how four perceptual cues (Vowel Quality, Duration, Intensity, F0) affect the perception of the stress patterns between Korean L2 learners and English native listeners, we conducted binomial logistic regression using R (R Core Team, 2012, Version 3.1.2) with the lme4 package (Bates, 2005; Bates & Maechler, 2010). “Choice (first syllable vs. second syllable)” was entered as the dependent variable, and Syllable (first vs. second), Vowel Quality (step 1–5), Duration (step 1–5), Intensity (step 1–5), F0 (step 1–5), Group (Korean vs. American) was entered as fixed effects, and subject was set as a random effect. The word with first-syllable stressed word, noun ‘OBject’, was coded as ‘1’ because of its higher frequency of occurrence (‘OBject’: 104 per million vs. ‘obJECT’: 24 per million, based on the CELEX database; Baayen et al., 1993). For the Group factor, Americans’ perceptual patterns were used as a baseline to examine how Koreans’ perceptual patterns differ from native listeners. Thus, the baseline in the model was the English native listeners’ performance on the first-syllable stressed word ‘OBject’ with intensity 1, duration 1, F0 1, and vowel quality 1.
The model tested the main effect of the independent variables, two-way interactions between the segmental and suprasegmental cues (VQ by Duration; VQ by Intensity; VQ by F0), a two-way interaction between Group and Syllable, three-way interactions among Group and two of the cues (e.g., Group by VQ by Duration), and four-way interactions among Syllable, Group, and two of the cues (e.g., Syllable by Group by VQ by Duration). When there was an interaction between the independent variables, we stratified the data by the factors that showed the interaction. When a significant interaction was found between independent variables, a post-hoc analysis was conducted using binomial logistic regression by stratifying the data to analyze the relationship between the factors. A series of fitted mixed-effects regression models were tested in a stepwise analysis to find the most parsimonious model.
3. Results
Binomial logistic analysis showed main effects of Group and Vowel Quality (p<.01). These results show that Korean listeners showed a more biased perceptual pattern for the second syllable stressed word ‘obJECT’ (66%) than English native speakers (54%) as the vowel quality changed to schwa. When the first syllable is in step 1 (no stress on the first syllable), the response rate that the listener answered that the first syllable is stressed was 21%, and this response rate increased to 27%, 29%, 60% and 72%, respectively. We also found significant two-way interactions between Group and Syllable (p<.01), Group and Vowel Quality (p=.04), Group and Intensity (p<.01), and threeway interaction among Group, Syllable, Intensity (p<.01) and among Group, Syllable, F0 (p<.01). Table 3 represents the result of the logistic regression on both syllables.
In order to further understand these interactions, we stratified the data as a function of Syllable, and ran a model that include Group, Vowel Quality, Intensity, Duration, F0 as main effects, and two-way interactions between Group and each of the acoustic cues, with Subject as random effect. When the cues on the first syllable were manipulated, the analysis showed a main effect for Vowel Quality (p<.01), and significant interactions between Group and Vowel Quality, between Group and Intensity, and between Group and F0 (p<.01). The main effect on the Vowel Quality indicates that both listening groups were perceptually influenced by the changes of the vowel quality on the first syllable on the English stress. Table 4 represents the summary of results of the model with the listeners’ responses to the tokens for which the first syllable was manipulated while controlling the second syllable (first syllable level).
In order to examine the interactions between Group and Vowel Quality, Group and Intensity, and Group and F0, we further conducted two separate linear mixed-effects models examining participants’ responses to the tokens for which the first syllable was manipulated with each listener group. For native English listeners, we found a main effect of Vowel Quality only (p<.01), indicating that English listeners only weight Vowel Quality of the first syllable in identifying stress pattern. Table 5 represents a summary of results of the model at the level of the first syllable by the native English listeners.
| Variable | Estimate (SE) | Z | p-value |
|---|---|---|---|
| (Intercept) | –3.30 (0.32) | –10.30 | <.01 |
| Vowel Quality | 0.90 (0.04) | 23.65 | <.01 |
| Intensity | 0.04 (0.05) | 0.75 | .45 |
| Duration | 0.10 (0.05) | 1.82 | .07 |
| F0 | 0.01 (0.05) | 0.21 | .83 |
For Korean learners, we also found a main effect of Vowel Quality (p<.01), indicating that the probability of the first-syllable stressed responses decreased as the vowel quality was reduced. The smaller estimate score for Korean learners (0.43) than English listeners (0.90) indicates that English listeners weight vowel quality more heavily than the Korean listeners. We also found main effects of Intensity (p<.01) and F0 (p<.01). These results indicate that when the intensity value on the first syllable increases, the probability of responding first-syllable stressed word also increased. The first-syllable stressed response rate when the intensity was at step 1 (first syllable unstressed) was 24%, and this rate increased to 27%, 37%, 39%, and 51% at step 2, 3, 4, and 5 (first syllable stressed), respectively. Similarly, when the F0 values on the first syllable were increased, the first-syllable stressed response rate also increased. The response rate to the first-syllable stressed word when F0 was at step 1 (first syllable unstressed) was 29%, and this rate increased to 34%, 35%, 41%, and 49% at step 2, 3, 4, and 5 (first syllable stressed), respectively. Table 6 presents a summary of results of the model at the level of the first syllable by Korean learners.
| Variable | Estimate (SE) | Z | p-value |
|---|---|---|---|
| (Intercept) | –4.06 (0.37) | –10.90 | <.01 |
| Vowel Quality | 0.43 (0.04) | 12.48 | <.01 |
| Intensity | 0.33 (0.06) | 6.11 | <.01 |
| Duration | 0.11 (0.05) | 2.01 | .04 |
| F0 | 0.25 (0.05) | 4.57 | <.01 |
Figure 1 presents the probability of first-syllable stressed responses (‘OBject’) between the two listener groups for the tokens in which four acoustic parameters varied in the first syllable while controlling the cues in the second syllable. Each cue is represented with a different color, and two listener groups are represented by different lines (Korean learners: dashed lines; Native English listeners: solid lines). This figure shows that native English listeners weight vowel quality more heavily than the Korean learners, and English listeners do not weight other suprasegmental cues in perceiving English stress pairs. On the other hand, Korean learners weight Vowel Quality the most, and also weight intensity, duration, and F0.
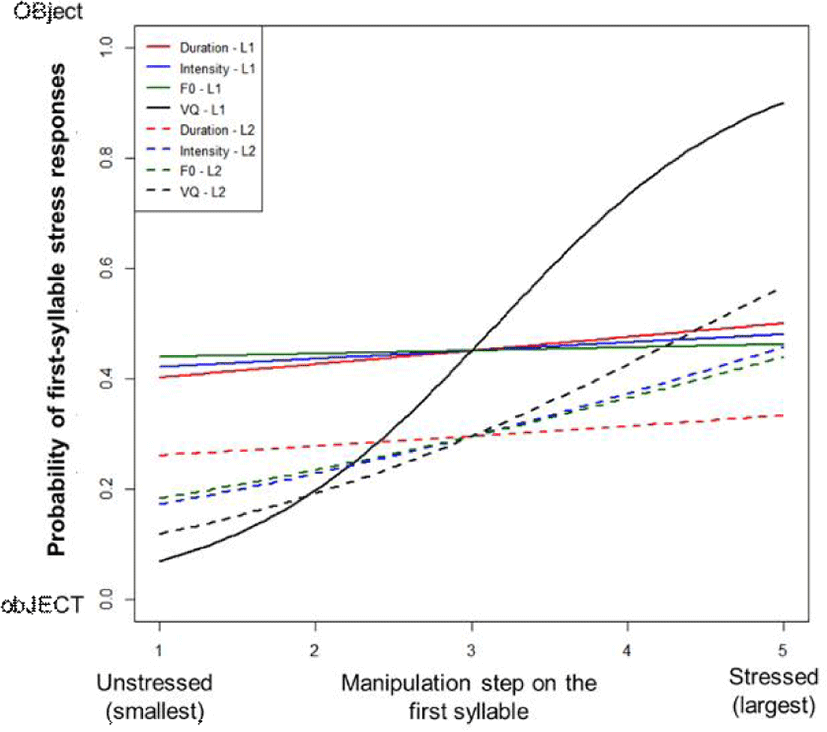
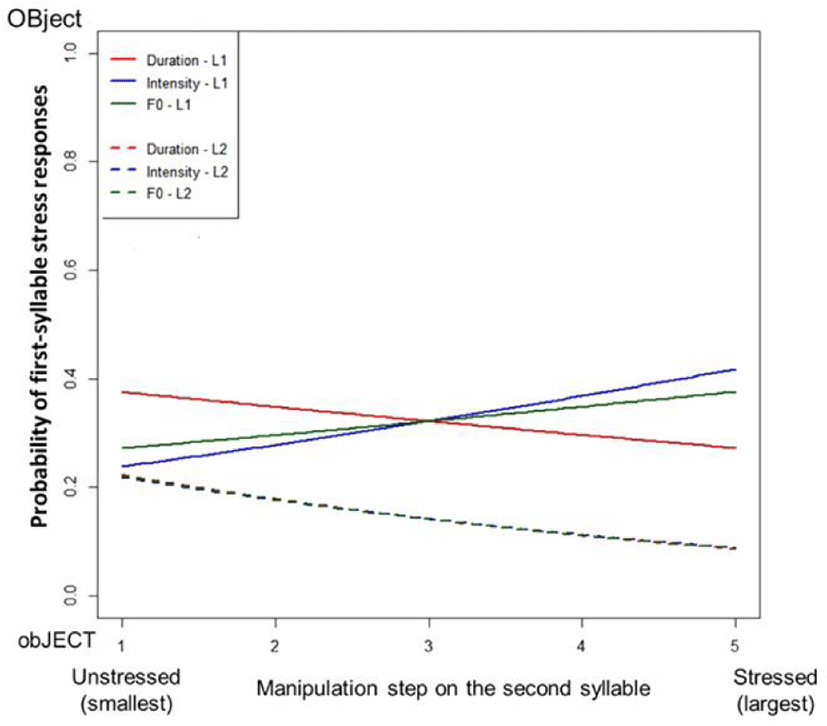
When we conducted a linear mixed-effects model on the tokens for which the suprasegmental cues in the second syllable were manipulated while controlling the acoustic cues in the first syllable to be neutral, we found no main effects or interactions, indicating that neither listener group was using cues in the second syllable in perceiving English stress pairs. Figure 2 presents native and L2 listeners’ responses as a function of manipulated steps of three cues, showing the lack of effect of acoustic cues in the second syllable on the perception of the English stress pairs.
4. Discussion
In this paper, we investigated which perceptual cues Korean L2 learners of English weight to distinguish English lexical stress compared to native English speakers. Considering that the three suprasegmental cues (F0, duration, intensity) implementing English lexical stress are also used in Korean higher-level prosody, we predicted that Korean English learners would be able to use the same three perceptual cues to perceive English stress. We also examined whether Korean English learners can learn new perceptual cues (vowel reduction) that do not exist in their native language. The results showed that Korean learners of English perceived English stress by weighting on vowel quality cues the most, indicating that L2 learners can acquire a new cue that does not exist in their L1 phonological category. This finding is very conflicting when compared to the inability of Korean English learners to use vowel reduction cues (Lin et al., 2013). Regarding the weighting of suprasegmental cues, we found that Korean learners of English weight F0 and intensity more heavily than duration cue in recognizing English stress pattern. Although F0 is more frequently used than intensity and duration in Korean higher level prosody, duration is still the least frequently used cue in phrasal boundary, since duration only marks at the sentence-final position whereas intensity and F0 both AP and IP boundary. Also, since Korean phonemic vowel length has lost in the production (Lee & Jongman, 2019), it seems plausible that duration is not affecting the recognition of lexical stress pattern in L2. This result is also consistent with previous studies showing that an L2 learner’s linguistic experience will modulate perceptual attention to specific acoustic cues, thus influencing L2 stressed learning (Francis & Nusbaum, 2002; Guion & Pederson, 2007; Iverson et al., 2003; Lee et al., 2006). In this study, Korean learners were led to pay attention to these cues in recognizing the stress of English based on their experience of richness of intensity and F0 in their native language, so the experience of these cues in L1 led them to learn in L2 perception. Korean learners may be able to perceive English stress because they were guided to pay attention to these cues, at least in our findings, as supported by the Cue Weighting Model (e.g., Francis & Nusbaum, 2002; Holt & Lotto, 2006; Ingvalson et. al., 2011; Zhang & Francis, 2010).
Then, how were Korean learners able to acquire segmental signals that did not exist in their mother tongue? According to the Cue Weighting Model, perceptual cues that do not exist in the native language have a low perceptual weight and are highly likely to not be used when learning a foreign language (Schmidt, 2001; Tomlin & Villa, 1994). However, in this study, it was found that, at least in English stress perception, a new perceptual cue called vowel reduction acts as the biggest factor for L2 learners. Chrabaszcz et al., (2014) also found that Mandarin and Russian learners gave more weight to vowel reduction cues in recognizing non-word stress patterns in English. It may be the case that spectral cue is more perceptually distinct than suprasegmental cues. Or, other possibility is that L2 learners might be perceptually assimilate full English [ɑ] and [ə] to corresponding Korean vowels, [ɑ] and [ʌ]. In order to investigate these possibility, further investigation is needed.
Overall, this paper found that L2 learners are able to acquire a new cue that does not exist in their L1 phonological system, and also revealed that L2 learners can extract cues from the L1 higher-level prosody, and transfer these cues to acquire L2 word- level prominence.