





1. Introduction
When adult listeners recognize spoken words, they encounter substantial variation caused by factors from speakers, contexts, styles, etc. However, there is ample evidence that listeners can handle such variation in the speech signal (Connine et al., 1993; Gaskell & Marslen-Wilson, 1996; Gow, 2001, 2002; Ranbom & Connine, 2007; Sumner & Samuel, 2005, 2009). Research in this field has been divided between studies of phonologically regular variation such as assimilation and those of arbitrary variation such as mispronunciation. The former is further divided into the investigations between “out-of-context” and contextual variations. There is a large body of evidence that contextual variation does not disrupt word recognition because there is an explicit conditioning environment that licenses the change (Gaskell & Marslen-Wilson, 1996). Ernestus et al. (2002), for example, investigated the recognition of reduced word forms in casual Dutch (e.g., [dam] from /darɔm/ <daarom> ‘therefore’), manipulating the size of context (Full context, Limited context, Isolated context), and the degree of reduction (Low, Medium, High). They found that even highly reduced forms are recognized accurately in their Full context, whereas they are recognized poorly in the Limited context. Unlike the context-dependent variation, Coenen et al. (2001) pointed out that non-contextual variation can incur a cost in processing because any variant form can occur in the identical environment.
However, Sumner & Samuel (2005) showed that if the variation is common and legitimate, there may be no cost in the short-term processing. They examined the immediate and long-term processing consequences for variation occurring in English word final /t/, using the short-term and long-term priming tasks, respectively. The word final /t/ has at least three possible variants: a fully articulated [t], a coarticulated, glottalized [ʔtㄱ] and a singly articulated glottal stop [ʔ] (i.e., [flut], [fluʔtㄱ], and [fluʔ] for flute). They found that variation does not hinder immediate semantic processing, whereas form priming over time is not as lenient as immediate priming, demonstrating that strong priming is found only for the canonical form of /t/.
The current study was further concerned with frequent, context-in-dependent variation from an on-going sound change to examine what effect, if any, such variation has on immediate word recognition. Specifically, this study employed a short-time repetition priming lexical decision task to examine the variants of the consonant cluster /lk/ in Korean. It is well known that Korean does not allow consonant clusters in syllable onset and coda positions. As a result, consonant clusters may occur underlyingly but when consonant clusters are followed by a vowel, the second consonant of the cluster is resyllabified into the onset of the following syllable (e.g., [kap.si] from /kaps/ ‘price’ + /i/ ‘nominal suffix’), whereas they are realized as a single consonant when followed by another consonant (e.g., [kap.to] from /kaps/ ‘price’ + /to/ ‘too’). Which consonant of the cluster is deleted is determined by the cluster type (Iverson & Lee, 1994; Jun, 1998; Kim, 2022; Kim-Renaud, 1974; Oh, 1994) or regional dialect (Cho, 1988; Whitman, 1985). According to the Standard Pronunciation of Korean (The National Institute of the Korean Language), eleven underlying clusters (i.e., /ps, ks, nc, ls, lth, lk, lm, lp, lph, nh, lh) exhibit two different deletion patterns. Namely, the second consonant is invariably deleted in the clusters /ps, nc, lth, nh, ls, lh/, while the clusters /lk, lm, lph/ delete the first consonant. In the cluster /lp/, the second consonant is deleted, except for the word /palp-ta/ ‘step on’ where the first consonant is deleted.
However, regardless of this regulation, the clusters containing /l/ plus a stop such as /lk, lp/ show substantial variation whose realization is conditioned by linguistic and sociolinguistic factors. Recent phonetic studies have shown that [l] is frequently realized in the cluster and sometimes both consonants are preserved (Cho, 1999; Cho & Kim, 2009; Kim & Kang, 2021). More recently, based on a large-scale spontaneous speech corpus (National Institute of Korean Language Dialogue Corpus, 2022), Kwon et al. (2023) reported that for /lp/, the preservation of /l/ is already prevalent among both old and younger speakers; for /lk/, speakers born after 1970 showed a significantly higher rate of [l] or [lk] realizations (e.g., 84% for standard Seoul dialect speakers), whereas those born before 1970 showed less preservation of [l] or [lk] (e.g., 56% for Seoul speakers). Based on these results, Kwon et al. (2023) argued that there may be a sound change in progress towards preserving the first consonant (i.e., [l] or [lk]) of the /lk/ cluster.
Thus, focusing on the variants of /lk/, in which the consonant cluster simplification is still on-going, unlike those of /lp/ where the change is almost complete, the present study is concerned with what effect, if any, the /lk/ variants, namely, two innovative forms ([l] and [lk]) and the standard form ([k]), have on immediate word recognition. This variation is particularly interesting in that it is not arbitrary as in accidental mispronunciations, nor context-dependent as in assimilation because the three variants show free variation. Furthermore, the standard form (i.e., [k]) is not the most frequently produced variant. We expect that there are two possibilities in the short-term processing of /lk/ variants: the variant forms without an explicit conditioning context can incur a cost in processing, following Coenen et al. (2001). Alternatively, there may be no cost with regular variation in the short term, following Sumner & Samuel (2005). Thus, we examine whether nonstandard, innovative variants may be as effective as the standard variant in the immediate processing. To this end, a short-term priming task was administered to collect reaction time (RT) to make a lexical decision from the native Seoul Korean speakers. Typically, this task is a way of investigating what forms become available (i.e., activated) when a listener hears speech. Priming occurs when a previously processed stimulus (prime) facilitates recognition of subsequent perceptual objects (target) (Schvaneveldt & Meyer, 1973). The RT to accept the target word is expected to be faster after related prime than after an irrelevant, control prime (Zwitserlood, 1996).
2. Method
Ninety participants took part in the experiment. They were all native speakers of Korean (30 males, 60 females) aged between 18 and 31 (mean=21.3, SD=2.02) and none reported hearing or language impairment. They were paid for their participation.
Eight Korean disyllabic words (verbs or adjectives) were selected for targets: /palk-ta/ ‘bright’, /ilk-ta/ ‘to read’, /kulk-ta/ ‘thick’, /kɨlkta/ ‘to scratch’, /malk-ta/ ‘clear’, /mulk-ta/ ‘watery’, /nalk-ta/ ‘old (object)’, /nɨlk-ta/ ‘old (human)’. Each word has /lk/ in the coda of the first syllable (verb/adjective stem), which is known to be realized as either [k], [l], or [lk]. We employed a priming method in the lexical decision task: each word had 9 conditions (3 variants for prime × 3 variants for target) for the critical prime-target pair. To balance the number of real word and non-word targets in the experiment, the same number of non-words were constructed in terms of replacing the coda consonant by another single coda (e.g., [in-t’a], [iŋ-t’a], [imt’a] for /ilk-ta/). To prevent the participants from focusing on the structure of consonant clusters, 432 fillers were additionally constructed. In sum, there were 576 trials, 144 target pairs (8 words × 9 conditions × 2 non-words) and 432 filler pairs. The stimuli were recorded by two female speakers of Seoul (standard) Korean (ages: 20, 24) in a sound-attenuated booth, using Tascam HD-P2 solid-state recorder and Shure KSM44 microphone. Each speaker was directed to produce all variant forms of the cluster in two contexts, one with a complete sentence that includes a verb/adjective and its complement (e.g., /toŋ.hwa.chæk.ɨl.ilk.ta/ ‘(He/She) reads a fairy tale book’), and the other with a target verb/adjective only in the frame sentence (/i.tan.ʌ.nɨn. i.ta/ ‘This word is ’). The former was used for the prime, while only the target word in the latter was used for the target. Unlike the typical priming task, the prime in this study provided context for the target words. The inclusion of complement in the prime had two purposes: 1) prohibiting misunderstanding from the homonyms, given that the verb/adjective stems with the consonant clusters in the coda are only 11 in Korean but many of the variant forms (with [l] or [k]) have abundant homonyms (e.g., [ik.t’a] from/ilk-ta/ ‘to read’ versus [ik.t’a] ‘to ripe’); and 2) allowing us to simulate fairly normal, natural speech. In everyday speech, the target words are not used alone but presented within a phrase or sentence. The primary question to be raised in this study was whether the variants of the consonant clusters in normal conversation might have an impact on the immediate word recognition. The complete list of sentences is presented in Appendix I.
Participants were informed of the details of the experimental procedure and provided their informed consent before the experimental session began. Each participant was tested individually in a soundattenuated booth with E-prime 2.0 software (Psychology Software Tools, Sharpsburg, PA, USA) and headphones (HD 599, Sennheiser, Hannover, Germany). They were presented with a sentence with the structure of a complement and target verb/adjective (prime) over headphones and were asked to make a lexical decision to the word (verb/adjective only) which was immediately followed (target). The auditory prime and target they heard were taken each from the recordings of the two different speakers to avoid any strategic judgment based on indexical characteristics of the speakers. Each trial began with a fixation mark (+) which remained at the center of the screen for 1,000 ms. Next, participants were presented with an auditory prime, followed by an auditory target after a 500 ms interstimulus interval (ISI). Participants were instructed to judge the auditory target as quickly and accurately as possible by pressing “1” on the keypad if they thought that it was a real word of Korean, or “3” if they thought it was a non-word. If participants did not respond within 3 seconds, a new pair was presented. RT was measured from the onset of the target. The stimuli were presented in 9 blocks, and 90 participants were randomly assigned to one of the 9 blocks (10 for each block). The prime-target pairs in the 9 conditions for the same target words were not included in the same block. Thus, each participant experienced 64 trials continuously in a randomly chosen condition (block) ((8 target words + 24 filler words) × 2 nonwords). Participants were given 9 practice trials (fillers) before proceeding onto the main task and the entire experiment took approximately 5 minutes to complete. After the experiment was completed, each participant read the list of the words to evaluate how he/she produced the target clusters, which was recorded, using a Tascam HD-P2 solid-state recorder. The recording lasted around 5 minutes. At the end of the experiment, each participant filled out the sheet for familiarity of the test words, using 7 Likert scale (1: unknown, 7: very familiar).
3. Results
Of the 5,760 tokens obtained (90 participants × 64 trials), only the target words (not fillers) and the real words of the target pairs were included for analysis of priming effects, which led to 720 tokens (8 words × 9 conditions × 10 subjects). Among the 720 tokens, a total of 75 items, including missing responses and errors, were excluded; RTs more than 2.5 standard deviations above or below the mean for a given participant were further trimmed to avoid the influence of outliers (Elgort, 2011). This resulted in the exclusion of 13.75% (n = 99) of participants’ responses to targets and the total number of tokens for RT analysis was 621.
Before presenting the results of the immediate priming task, the results of the acoustic measurements for the stimuli produced by the two female Seoul speakers were examined. Figure 1 shows the three representative spectrograms and Table 1 summarizes the relevant acoustic measures.
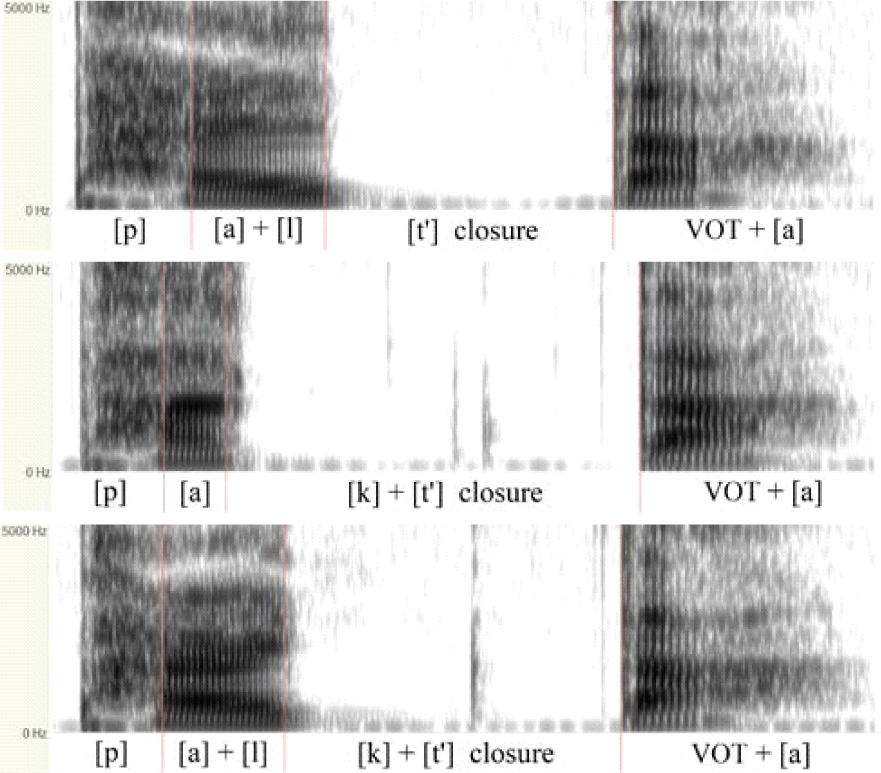
Comparison of the three spectrograms in Figure 1 demonstrates that the closure duration of the stop is longer for the [lk] variant (bottom) than for [l] (top), presumably because of the production of [k] in the former. In the spectrograms of [k] and [lk], as shown in the two bottom figures, F2 of the transition from the preceding vowel or [l] to the target stop [k] shows a velar pinch because the immediately following consonant is dorsal (Kim & Kang, 2021). The acoustic measurements in Table 1 confirmed that both speakers produced the three variants of /lk/ as described above, regardless of some inter-speaker variation.
The RT data for correct responses in each prime-target pair are presented in Figure 2.
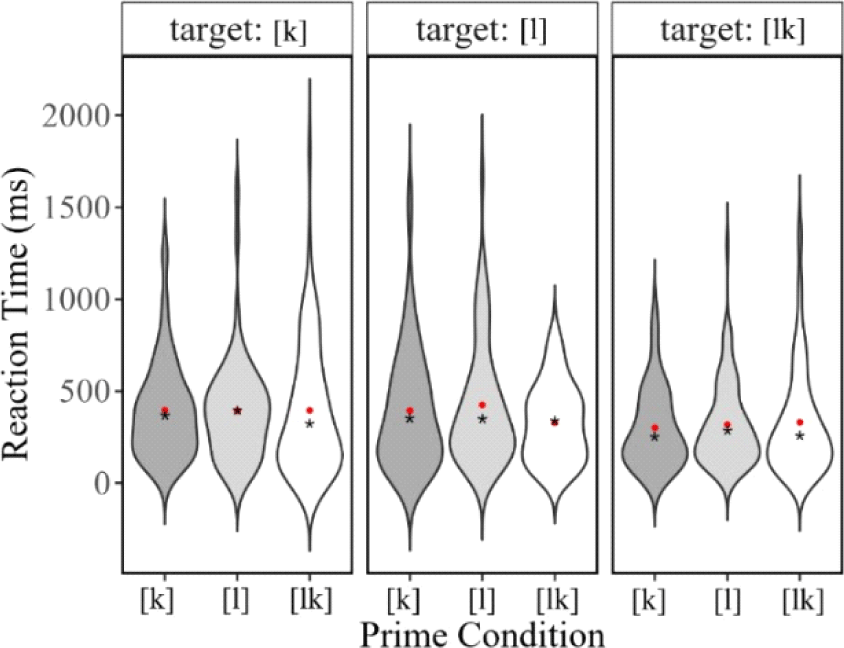
Figure 2. Mean reaction times (ms) for immediate processing of three variants of /lk/ (The asterisk and the small circle in each violin indicate the median and mean, respectively).
In Figure 2, the RT values for the three targets appear to be different regardless of the prime condition. Namely, the RTs for the prime of [k], [l], and [lk] were 394 ms, 425 ms, 328 ms, respectively when the target was [l], 396 ms, 393 ms, 395 ms, respectively for the target of [k], and 300 ms, 317 ms, 351 ms, respectively for the target of [lk], respectively. Overall, the RT was shortest in the target of [lk] (mean=316 ms, SD=250), longest in the target [k] (mean=395 ms, SD=301), and the target [l] showed the intermediate RT values (mean = 383 ms, SD=299). Based on the numerical RT results, young adult Korean speakers did not seem to have apparent benefit of realizing the standard variant in processing spoken words, since the standard variant of /lk/ (i.e., [k]) was least effective in priming targets in terms of RT. To ensure this result, RTs were submitted to linear mixedeffects regression model utilizing the lmer function from the package lmerTest (Kuznetsova et al., 2017) in R (R Core Team, 2024). The dependent variable was RTs and the fixed factors were prime condition ([k], [l], [lk]) and target condition ([k], [l], [lk]). The random factors considered were by-speaker and by-word intercepts. The fixed factors were sum-coded to determine whether there was any main effect. To build the model, several models were constructed in a stepwise manner from the maximal model containing all factors, such as prime and target condition, and nested models were compared using the likelihood ratio test of significance. To facilitate model convergence, the BOBYQA optimizer was used with a maximum of 100,000 iterations. There was a significant main effect of target condition but prime condition and interaction of these two factors were not significant. The statistical results for RTs of the immediate processing are presented in Table 2.
We observed a significant effect of Target condition, but not Prime condition. A follow-up pairwise comparison was conducted using the Tukey test from the emmeans package (Lenth et al., 2021) to further examine the effect of target condition. The mean RT for [lk] as a target was significantly shorter than that for [k] or [l], while [k] and[l] did not show significant differences. These results demonstrate that Korean listeners showed poor perception of the variants realized as a standard form (i.e., [k]) or a single innovative form (i.e., [l]), whereas there is apparent facilitation in processing of the innovative form realized with both consonants (i.e., [lk]).
In the following, we further assessed whether the critical RTs for the target pairs obtained from Korean participants ([lk] versus [l]/[k]) may be associated with their production patterns of realizing the /lk/ cluster as [lk] (CC production). Close inspection of the participants’ production of the cluster reveals substantial inter-speaker variability. Based on auditory and acoustic analyses as above, each token produced by participants was coded and labeled by two authors as containing [l], [k], or [lk]. The percentage of consistently producing one of the three variants of the cluster was only 24.44% (20% for [l]; 4.4% for [k]), while in the percentage of producing the cluster with multiple variants, realization of two variants reached approximately 35.56% (27.78% for [l, k], 4.44% for [l, lk], and 3.33% for [k, lk]), and that of three variants, 40% ([l, k, lk]). If we look at the mean production percentage of each variant across the participants, realizations of /lk/ as [l], [k], and [lk] were 61.5% (range=0–100, SD=34.0), 26.9% (range=0–100, SD=30.6), and 11.6% (range=0–75, SD=18.5), respectively. These results suggested that the three variants of /lk/ show freely used but [l] was most frequently chosen, while [lk] was least frequent.
The relationship between the CC production ratios and its processing speed was statistically analyzed using Pearson correlation analysis, to examine whether speakers who pronounced the /lk/ as [lk] performed better at processing the [lk] form. Results showed that the ratio realizing both consonants of the cluster was not correlated with their processing RT [coefficients=0.040, t=0.376, df=87, p=0.708], as shown in Figure 3.
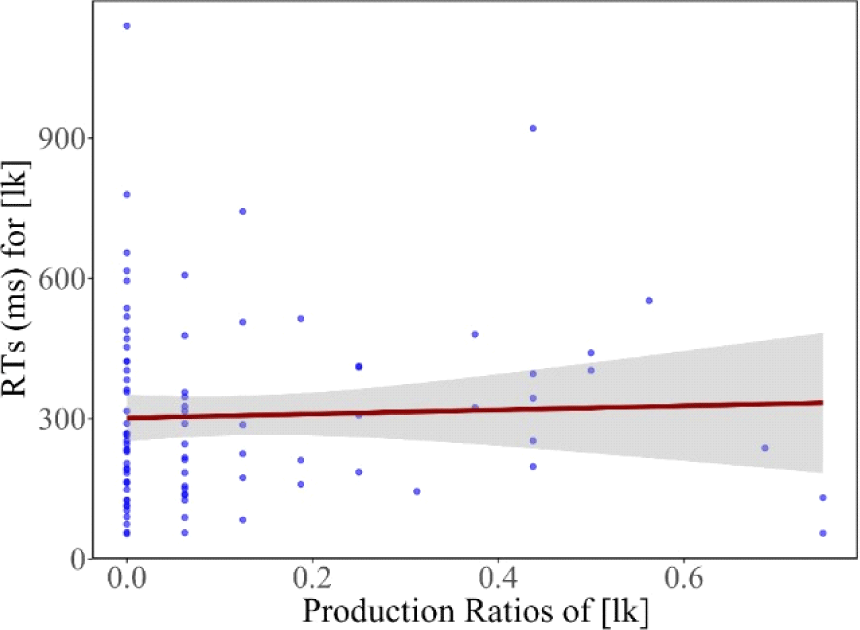
Figure 3 illustrates non-significant relationship between the participants’ own production of the /lk/ cluster as [lk] and their processing time for [lk]. Upon inspecting the four quarters of the scatterplot, the top and bottom of the left side appear crowded, suggesting that participants produced a few of the tokens as having variants of both consonants but showed a great deal of variation in their processing time.
4. Discussion
Overall, there were two main findings: 1) among the three variants of /lk/ (i.e., [l], [k], [lk]), the standard form ([k]) and the single innovative form ([l]) were more slowly processed than the other innovative form which is realized with both consonants ([lk]); and 2) there was no significant correlation between the ratio producing both consonants of the cluster and their processing speed.
Results of the immediate processing of the three variants of /lk/ partially confirm the findings of previous acoustic studies (Cho, 1999; Cho & Kim, 2009; Kim & Kang, 2021; Kwon et al., 2023) in which younger speakers did not prefer the standard form (i.e., [k]) when they pronounced the /lk/ cluster. In the processing speed, the standard form was significantly slower than the innovative form [lk] but another innovative form (i.e., [l]) also showed longer RT than [lk]. The apparent lack of benefit for the standard form was expected in the production pattern of the cluster: younger speakers preserved [l] or [lk], not [k] in the production of /lk/. However, the significant difference between the two innovative forms is contrary to what we might expect. One possible explanation for this result is that the forms with a single consonant, standard or innovative, engaged in a large amount of lexical competition during word recognition due to many lexical neighbor words or even homophones. Although the complete sentence was presented as a prime to provide context in which the target word was used, the target words with the /lk/ cluster were likely to become engaged in competition with similar sounding words or homophone words. For example, when the target /malk-ta/ was presented with a single consonant variant (i.e., [mak.t’a] or [mal.t’a]), easily activated competitor words might include /mak-ta/ ‘to block’ and many other lexical neighbors (e.g., /math-ta/ ‘to smell’). On the other hand, realization of /lk/ as [lk] may decrease lexical competition because realization of two consonants in the syllable coda is very limited to the lexical items with /l/ plus obstruent clusters (/lk, lp, lph, lth/).
To assess this hypothesis, we derived the phonological neighborhood density (ND) values of the target words relative to all Korean words, using a lexical database of surface phonetic forms and ND measures for Korean words, ‘K-SPAN (Korean Surface Phonetic and Neighborhoods)’ (Holliday et al., 2017). The phonological ND is commonly used as a measure of word similarity of phonological structure of the lexicon. The ND is typically measured as the number of other words in the lexicon that differ from a target word by a pho-nological distance of one segment by addition, deletion, or substitution of a single phoneme. In speech perception, it has been shown that higher ND is correlated with slower lexical processing (Luce & Pisoni, 1998). In K-SPAN, the ND of Korean words was calculated based on three types of representations of the Korean words in a large-scale corpus (Modern Korean Usage Frequency Survey 2 Corpus) (Kim, 2005), a quasi-phonological representation (“orthographic”), a representation maintaining all known phonological contrasts (“conservative”), and a representation for the pronunciation of contemporary Seoul Korean (“modern”). The mean ND of the eight target words, the total number of two-syllable Korean words, and the total number of Korean words are presented in Table 3.
Table 3 demonstrates that regardless of the way the ND was calculated, the mean ND of the test words is considerably higher than that of the whole two-syllable Korean words or that of all Korean words. It is worth noting that in the level of phonetic form (reflecting how the words are actually pronounced), not the orthographic form, the mean ND of the target words reached 739.47, which was clearly contrasted with that of the other two categories of words: 80.86 for the whole two-syllable Korean words and 50.69 for the whole Korean words. The results of the ND measures indicate that the target words containing /lk/ can create substantial lexical competition and thus might require great effort to perceive correctly. This does not mean that considerable lexical competition is the primary or even sole factor for the present results. As potential influences from other factors such as acoustic or prosodic variation across listeners remain unaddressed, a more systematic investigation is necessary for clarifying the mechanisms underlying the observed priming effects.
Regarding the production results, we found that the production ratios of the three variants of /lk/ in this study are in good line with those of previous studies: the participants realized /lk/ as [l] with a rate of 61.5%, [k] with 26.9% and [lk], with 11.6%. Contrary to the pronunciation regulation, younger speakers preferred the single innovative form ([l]) to the standard form ([k]). However, it is notable that the participants in this study used all three variants freely, not using only one form, although they favored one specific form over another. This finding suggests that realization of the /lk/ cluster as known as ‘consonant cluster simplification’ has not stabilized yet and is still a work in progress. Another interesting finding is that even participants who produced the /lk/ as [lk] were not shown to perform better in the lexical decision for the tokens with [lk]. Prior work that has addressed the relationship between speech perception and production at an individual level put forth mixed results (Beddor et al., 2018; Bradlow et al., 1997; Kim & Clayards, 2019; Shultz et al., 2012). A series of studies observed that more accurate perception of speech sounds leads to their more accurate production. For example, Bradlow et al. (1997) trained the Japanese learners of English to perceptually distinguish the English /r/ and /l/ and found that they improved their production of this contrast. On the other hand, another set of studies showed the mismatch of speech perception and production. Shultz et al. (2012) investigated native English speakers’ weighting of two acoustic cues, VOT and F0 at vowel onset, for the English stop contrast (i.e., voiceless versus voiced) in word-initial position. They found that individual speakers’ perceptual weights for these two cues were not significantly correlated with their use of these cues in speech production. The present findings further support the second stream of research, providing evidence for no significant correlation between the actual production of [lk] and its perceptual processing.
5. Conclusion
In conclusion, the present study examined adult Korean speakers’ immediate processing consequences of the variants of /lk/, namely, the standard form [k] and two innovative forms [l] and [lk]. The results of the short-term repetition priming task demonstrated that recognition of the words containing the /lk/ variants were equally effective for the standard and single innovative form; however, word recognition containing another innovative variant (i.e., [lk]) was significantly faster than the other two variants, presumably because this form is more likely to avoid lexical competition. Additionally, it was also shown that the speakers who produced the innovative variant of [lk] more often were not necessarily good at recognizing the words containing this variant, providing evidence for a mismatch between speech perception and production. The present study provided novel evidence that phonetic variation resulting from on-going sound change can influence short-term spoken word processing. We believe that this study will enable future endeavors to address the questions regarding the extensive influence of phonetic variation in spoken word recognition.