





1. Introduction
Second Dialect Acquisition (SDA) investigates how speakers who are fluent in one dialect (D1) adapt to features of another dialect (D2) within the same language, particularly when integrating into a new speech community (Chambers, 1992; Nycz, 2013, 2015; Siegel, 2010). SDA research typically focuses on phonetic and phonological adjustments by geographically mobile speakers aiming to align their speech patterns with those of the local dialect to facilitate social integration. For instance, Canadian English speakers relocating to Alabama may adapt their speech toward Southern American phonetic norms (Munro et al., 1999). Importantly, sociolinguistic contexts and interlocutor identity significantly influence dialectal adjustment, as speakers often vary their speech depending on the communicative situation and their conversational partners (Rickford & McNair-Knox, 1994).
Communication Accommodation Theory (CAT) offers a theoretical explanation for such context-dependent speech adjustments. CAT posits that individuals adapt their communicative behaviors to manage social distances and identities during interaction, either converging toward or diverging away from their interlocutors' speech patterns (Giles, 1980; Giles & Coupland, 1991). Convergence, in which speakers adjust their speech patterns to align more closely with their interlocutors and reduce perceived social differences, is particularly relevant to SDA, as dialect learners often unconsciously or consciously modify their pronunciation to achieve positive social outcomes (Giles & Ogay, 2007).
Pyongyang North Korean, officially recognized in North Korea as the "cultured language" and a prestige dialect, undergoes a dramatic shift in sociolinguistic status upon the speakers’ migration to South Korea, where Seoul Standard Korean is perceived as the normative and prestigious dialect (Lee et al., 2022; Sohn, 2001). Consequently, North Korean refugees often experience linguistic discrimination based on their distinctive accents, reinforcing stereotypes of lower social status or limited education (Kim & Jang, 2007; Park & May, 2025).
To mitigate social stigma and facilitate integration, North Korean refugee speakers actively engage in dialectal modification toward Seoul Standard Korean. This adaptation is particularly pronounced in contexts where accent accuracy becomes socially salient, such as interactions with native Seoul speakers. Conversely, interactions among North Korean (NK) standard peers often elicit a return to original dialectal features, signaling comfort, solidarity, and shared identity (Park & May, 2025).
North Korean refugees residing in South Korea provide an insightful case for examining SDA dynamics. While the dialects of North and South Korea remain mutually intelligible, extended geopolitical separation has led to pronounced linguistic divergence, particularly in vowel production (Lee, 1991; Lee & Idemaru, 2024; Lee et al., 2018; Sohn, 2001). The South Korean (SK) standard currently employs seven cardinal vowels ([i], [ɛ], [ɯ], [ʌ], [u], [o], and [a]), reflecting historical vowel mergers and diphthongization processes (Shin et al., 2012). In contrast, the NK retains a more conservative system of ten vowels ([i], [e], [æ], [ɯ], [ʌ], [o], [u] , [a], [y], and [ø]) (Lee, 1991). NK speakers maintain distinctions such as [e] vs. [æ], now merged in SK speech (Kang, 1996; Lee & Idemaru, 2024; Lee & Ramsey, 2000).
Although [y] and [ø] may continue to be produced as monophthongs by NK speakers, reflecting a more conservative phonological system, little research has explored whether NK speakers who have resettled in South Korea maintain these monophthongal realizations or whether their vowel production patterns begin to shift under the influence of SK. In particular, it remains unclear whether [y] and [ø] become diphthongized or exhibit greater acoustic variability among NK speakers. While the present study focused on the eight vowels ([i], [e], [æ], [ɯ], [ʌ], [o], [u], and [a]) and did not include [y] and [ø], investigating potential changes in these vowels would be a valuable direction for future research, especially given that prior studies on the SK vowel system consistently report them as monophthongs.
Recent research has identified notable phonetic differences in vowel production between NK and SK standard varieties. Studies by Morgan (2015) and Lee et al. (2018) found that NK speakers frequently merge the vowel pairs [ʌ] and [o], as well as [ɯ] and [u]—a pattern that contrasts with the clearer distinctions maintained by younger SK speakers (Han & Kang, 2013; Kang, 1996, 2003; Seong, 2004). Lee & Idemaru (2024) further demonstrated clear differences in vowel production between NK and SK speakers, particularly in careful speech. NK speakers preserved vowel distinctions such as [e]-[æ] and [o]-[u], unlike SK speakers who showed vowel merging in the tongue height dimension. However, in conversational speech, NK speakers shifted vowel production towards SK patterns, notably producing a more fronted [u], suggesting unconscious convergence toward SK norms.
Despite existing studies exploring NK refugees' vowel production adjustments (e.g., Lee & Idemaru, 2024), research specifically addressing interlocutor-based variation—comparing NK refugees' speech with NK peers versus South Korean interlocutors—is limited. Previous research (Lee & Idemaru, 2024) has shown that NK speakers adjust vowel contrasts (e.g., [e]-[æ] and [o]-[u]) differently between careful and conversational speech contexts; however, the role of interlocutor origin (NK vs. SK interlocutor) remains underexplored.
Thus, this study aims to fill this gap by examining NK refugees' vowel production adjustments across three distinct speech contexts: careful speech, conversational speech with SK interlocutors, and conversational speech with NK interlocutors. Specifically, we address two research questions:
-
How do NK refugees adjust vowel production speech contexts with different interlocutors (careful speech versus conversational speech with SK and NK interlocutors)?
-
To what extent does vowel production reflect adaptation to SK speech norms versus retention of NK linguistic features when conversing with SK and NK interlocutors?
By investigating these issues, this research contributes to a deeper understanding of the nuanced interplay between linguistic accommodation, identity negotiation, and social pressures experienced by North Korean refugees navigating dialectal integration within South Korea.
2. Methodology
Six Pyongyang standard NK speakers (four females and two males) participated in this study. They were recruited through the author’s personal networks and received compensation for their involvement. The study consisted of a reading task and two sets of sociolinguistic interviews (NK-SK vs. NK-NK).
For the first sociolinguistic interview (NK-SK), considering the social vulnerabilities and challenges NK speakers often face in South Korea (Park & May, 2025), the author, who is a SK speaker, prioritized establishing a supportive and reassuring environment. Participants were clearly informed about their right to withdraw at any stage without any penalty. Trust was fostered through the author’s prior involvement with the NK community, volunteering at a government-run center aiding North Korean refugees in their integration process. Participants were assured they could freely skip any questions or express differing opinions without consequences.
Detailed demographic information, gathered during sociolinguistic interviews, is summarized in Table 1. All NK speakers originated from towns near Pyongyang, recognized for speaking the standard North Korean dialect (Sohn, 2001), and reported speaking the North Korean standard before relocating. Participants were aged between 18 and 21 years at the initial interview, with their age of arrival (AoA) in Seoul ranging from 10 to 19 years (M=16.2, SD=3.3), and their length of residence (LoR) in South Korea varying between 1 and 9 years (M=3.3, SD=3.3). In terms of education background (ED), all were high school students in Seoul at the initial data collection point. The demographic specifics for each participant are provided in Table 1. Additionally, the same six NK speakers participated in a second session, providing conversational speech samples with NK interviewers. These follow-up sessions occurred one to two years after the initial SK-led interviews. The follow-up sessions were conducted one to two years after the initial SK-led interviews. This delay was primarily due to scheduling conflicts with participants and the author’s extended stay abroad.
Three NK participants from the original group (Speakers #3, #5, and a new NK interviewer, Speaker #7, a friend of Speaker #6) acted as NK interviewers (see Table 2). Although ideally one interviewer would conduct all sessions, multiple interviewers were necessary due to personal dynamics and unfamiliarity between certain participants. Ensuring comfort and familiarity between interviewers and participants was emphasized to elicit natural, authentic conversational data.
| NK interviewer | Age | AoA | LoR |
|---|---|---|---|
| #3 (F) | 22 | 18 | 4 |
| #5 (M) | 20 | 10 | 10 |
| #7 (M) | 26 | 21 | 5 |
Speaker #3 interviewed Speakers #5 and #6, leveraging existing rapport. Subsequently, Speaker #5 returned to interview Speakers #3 and #4, chosen explicitly to avoid discomfort with other potential interviewers.1Finally, Speaker #7 conducted interviews with Speakers #1 and #2, who were unfamiliar with the other NK interviewers. These deliberate pairings prioritized participants' comfort, creating a relaxed atmosphere conducive to natural speech. Both speakers and NK interviewers received compensation for their time, including specialized interviewer training.
The SK interviews employed a formal polite speech register (contaysmal), whereas the NK-NK interactions reflected close interpersonal relationships, conducted in a casual, non-honorific speech register (panmal). This distinction is discussed further in subsequent sections.
All participants completed a reading task followed by an interview. The reading task consisted of eight vowels presented in isolation without a preceding consonant ([i], [e], [æ], [ɯ], [u], [ʌ], [o], [a]). Participants sat in front of a laptop computer, wearing a lavalier microphone (Audio-Technica AT 899, Audio-Technica, Leeds, UK) connected to a Marantz PMD 670 flash recorder (Marantz, Carlsbad, CA, USA). The screen displayed each vowel in Korean, presented in three randomized sequences (e.g., “이” [i]) with a carrier sentence “I said ___” (e.g., I said “[i]”, /i-lako malha-y-ss-ta/). Participants were instructed to carefully read each vowel aloud, producing a total of 24 vowels (8 vowels × 3 repetitions). This task was completed in approximately five minutes.2
Following the reading task, sociolinguistic interviews were conducted using a standardized question set. For the SK-NK conversation, the first author, a native SK speaker, interviewed each NK participant individually. Subsequently, NK-NK conversations were conducted by NK interviewers who underwent two hours of preparatory training. The training included two components: an hour-long session on operating the recording equipment using a detailed manual, and another hour on interview techniques adapted from Tagliamonte (2006). Interviewers were instructed on creating a comfortable environment, smoothly initiating conversations, asking clear and friendly questions, transitioning naturally between topics, and encouraging participants to elaborate.
To ensure a relaxed atmosphere, interviews took place in quiet rooms where the interviewer and participant were alone. NK interviewers, being close friends of the participants, fostered a casual and natural conversational dynamic. The study aimed to examine NK speakers’ stop production in informal contexts. Although formal settings, such as interviews, often prompt the use of polite speech (contaysmal) in both NK and SK speakers, participants were explicitly encouraged to use non-honorific intimate speech (panmal). This was explained prior to the interviews, and all participants naturally and comfortably used panmal throughout the conversations.
All interviews were recorded using a consistent setup: a lavalier microphone (Audio-Technica AT 899, Audio-Technica) connected to a Marantz PMD 670 flash recorder (Marantz). Interviewers and participants sat face-to-face in quiet rooms to ensure high-quality recordings. The interview questions, adapted from sociolinguistic studies of immigrant populations (Anastassiadis et al., 2017), covered three main topics. The demographic section gathered basic personal information, including participants’ name, age, hometown, AoA, and length of residence (LoR) in SK. The second section explored life in South Korea, focusing on experiences with SK neighbors, cultural adjustments, relationships with SK people, views on SK culture, career and education, domestic travel, and attitudes toward the SK language. The final section addressed life in North Korea, including childhood experiences, education, community relationships, immigration journeys, relationships within NK groups in SK, and attitudes toward the NK language. After the interviews, participants also completed a language attitude survey based on previous research (Preston, 1999; Park, 2002). The survey consisted of two parts. First, participants rated their attitudes toward NK and SK using a 6-point Likert scale across dimensions such as "correctness," "pleasantness," "intelligibility," and "prestige." Second, open-ended questions explored their perceptions of their own speech, awareness of dialect differences, and beliefs about language accommodation. The survey contextualized the acoustic analysis by examining whether participants’ sociolinguistic attitudes aligned with their actual speech patterns.
The number of vowel tokens produced by NK speakers in both sociolinguistic interviews is shown in the Appendix 1. The first author identified the vowels in the first syllable of content words in conversational speech and manually segmented the vowels. The first and second formants (F1 and F2) in the target vowels ([i], [e], [æ], [ɯ], [ʌ], [o], [u], and [a]) were measured at the mid-point of each vowel.
To investigate the effects of Speech Condition (Read speech, Conversation with NK, and Conversation with SK) and Vowel type on vowel production, Bayesian mixed-effects regression models were fitted separately for F1 (vowel height) and F2 (vowel backness) as dependent variables. The models (1) and (2) included Speech Condition (Read speech, Conversation with NK, and Conversation with SK, categorical factor, read speech as the reference level)3 and Vowel ([i], [e], [æ], [ɯ], [u], [ʌ], [o], [a], categorical factor, [ɯ] as the reference level) as fixed effects, along with their interaction (Speech Condition * Vowel) to assess changes in vowel quality across speaking contexts. A random intercept for Speaker accounted for speaker-specific variability. Statistical analyses were conducted using R version 4.0.2 (R Core Team, 2019) with the tidyverse package 1.3.0 (Wickham et al., 2019). Effect sizes (Cohen’s d) were computed using the effsize package 0.8.0 (Torchiano, 2020). Bayesian mixed-effects regression models were implemented with brms 2.13.3 (Bürkner, 2017), assuming a Gaussian distribution for the continuous F1 and F2 values. Weakly informative priors were specified, with a normal (0, 10) prior for the intercept and normal (0, 5) for the coefficients, reflecting prior uncertainty while maintaining flexibility in the estimates. The models were executed using the cmdstanr backend with 4,000 iterations per chain, including 1,000 warm-up iterations, across four Markov chain Monte Carlo (MCMC) chains, yielding a total of 12,000 post-warmup draws. Convergence diagnostics were assessed using R-hat values, with all parameters reaching R-hat ≈ 1.00, indicating proper mixing. Effective sample sizes (Bulk_ESS and Tail_ESS) were also examined to confirm model reliability. To optimize sampling, the control parameter was set to adapt_delta = 0.95. These models provide detailed insights into how NK speakers adapt vowel height (F1) and backness (F2) in different speaking conditions, highlighting the influence of the origin of the interviewer (SK vs. NK) on vowel production patterns.
(1) F1 ~ Speech Condition * Vowels + (1 | Speaker)
(2) F2 ~ Speech Condition * Vowels + (1 | Speaker)
3. Results
Figure 1 presents convex hull plots of vowel space for each Speech Condition, showing the distribution of F1/F2 values across different vowels. The plots display the vowel spaces separately for different interlocutor conditions, with distinct convex hulls representing the overall vowel distribution.
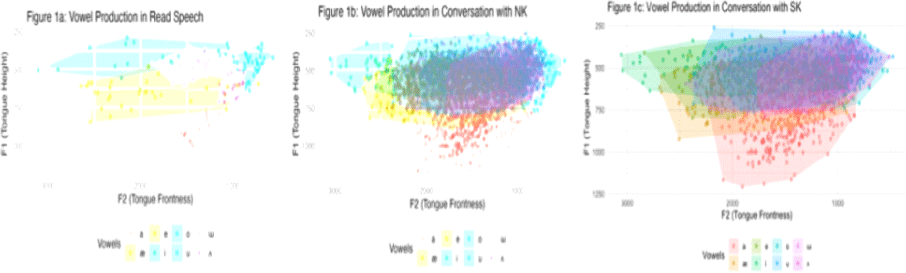
Vowel production patterns across the three Speech Conditions are visualized in Figure 1(a)–1(c), with separate vowel space plots for Read Speech, Conversation with an NK speaker, and Conversation with an SK speaker, respectively. Given that the vowel space seems to be different across the Speech Condition in the Figure, NK speakers might modify their vowel production depending on the interlocutors. The vowel space in Read Speech looks smaller than that of conversation with an NK interviewer and conversation with an SK interviewer. In addition, vowel space itself in the conversation with an SK interviewer condition appear to be bigger in terms of vowel space; however, this might be due to the larger variations of vowel production.
In the Appendix 2 presents the results of the F1 model, revealing significant effects of both Speech Condition and vowel type, as well as interaction effects that indicate condition-specific shifts in vowel height. In particular, conversation with an SK speaker (ConvSK) resulted in a significantly lower F1 (β=–7.6, SE=2.84, 95% CI: [–13.13, –2.05], p<0.01) compared to read speech. Because lower F1 values correspond to a higher tongue position, this finding indicates that NK speakers produce vowels with a raised tongue position in ConvSK relative to read speech. In contrast, conversation with an NK speaker (ConvNK) did not yield a significant overall change in F1 (β=0.2, SE=3.83, 95% CI: [–7.34, 7.74], p>0.05), suggesting that vowel height remains similar in both careful speech and NK–NK conversations.
Vowel-specific effects showed that several vowels, particularly [i] and [u], exhibited significantly lower F1 values (i.e., higher tongue positions) compared to [ɯ] ([i]: β=–32.62, SE=3.91, 95% CI: [–40.25, –24.93], p<0.01; [u]: β=–37.94, SE=3.37, 95% CI: [–44.57, –31.36], p<0.01). Furthermore, [ʌ] was produced with a significantly higher F1 than [ɯ] (β=10.1, SE=3.24, 95% CI: [3.79, 16.47], p<0.01), indicating that [ʌ] is articulated with a lower tongue position and reinforcing its classification as a mid or low vowel. Although [i], [ɯ], and [u] are traditionally categorized as high vowels in NK (e.g., Lee, 1991), the data suggest that [ɯ] was produced with a higher F1 than [i] and [u], positioning it closer to a mid-vowel. This unexpected pattern may be attributable to the perceptual instability of [ɯ], a high back unrounded vowel that is acoustically less salient than [i] or [u]. Given its lower perceptual distinctiveness, it is possible that NK speakers unconsciously centralize [ɯ], producing it with a relatively lower tongue position. While this remains speculative, it provides a plausible explanation for the observed F1 pattern and highlights the need for further investigation into the phonetic realization of [ɯ] in contact-induced speech contexts. One possible interpretation—though speculative—is that NK speakers who have resided in South Korea for an extended period may have restructured the acoustic target of [ɯ], resulting in a shift toward a more mid-like realization. Compared to [i] and [u], which are cross-linguistically robust high vowels, [ɯ] is more language-specific and may therefore be more vulnerable to phonetic drift or reanalysis in contact settings.
Interaction effects further revealed that certain vowels underwent condition-dependent changes in vowel height. Compared to read speech, ConvNK interviewer resulted in significantly lower F1 for [i] and [ɯ], indicating a higher tongue position in NK–NK conversational speech ([i]: β=–11.53, SE=4.81, 95% CI: [–21.08, –2.02], p<0.01, d=–0.70; [ɯ]: β=–28.78, SE=4.12, 95% CI: [–36.57, –20.56], p<0.01, d=–0.42).
Similarly, ConvSK interviewer resulted in significantly lower F1 for four vowels—[i], [ɯ], [o], and [u]—suggesting that NK speakers raised their tongue positions for these vowels when interacting with an SK speaker ([i]: β=–10.11, SE=4.38, 95% CI: [–18.61, –1.43], p<0.01, d=–0.88; [ɯ]: β=–37.53, SE=3.78, 95% CI: [–44.85, –30.21], p<0.01, d=–0.45; [o]: β=–32.67, SE=3.73, 95% CI: [–40.09, –25.22], p<0.01, d=–0.23; [u]: β=–11.24, SE=3.77, 95% CI: [–18.53, –3.75], p<0.01, d=–0.58).
Cohen’s d values further illustrate the magnitude of these effects. Overall, stronger vowel height effects were observed in the ConvSK condition, indicating greater articulatory adjustments in response to the SK interlocutor (see Appendix 3). Specifically, the vowels [i] (d=–0.88) and [u] (d=–0.58) showed the strongest raising effects, while [o] (d=–0.23) and [ɯ] (d=–0.45) exhibited moderate effects. In contrast, ConvNK displayed smaller but still notable raising effects for [i] (d=–0.70) and [ɯ] (d=–0.42), suggesting a more moderate adaptation pattern when interacting with another NK speaker.
These results indicate that vowel height adjustments in NK speakers are influenced by interlocutor-specific factors. Although read speech is often associated with hyperarticulation and more monitored pronunciation (e.g., Labov, 2006), our results show that NK speakers produce vowels with a higher tongue position in both NK–NK and NK–SK conversations, with the raising effect being more pronounced in the ConvSK condition. Moreover, the raising of [o] and [u] in the ConvSK condition aligns with previous findings that NK speakers tend to approximate SK phonetic norms when speaking to an SK speaker (Lee et al., in press). The observed raising of [o] and [u] suggests that NK speakers may be enhancing the contrast between back vowels as an adaptive strategy, a pattern consistent with earlier research indicating that NK speakers adjust their articulation when interacting with SK speakers (Lee & Idemaru, 2024).
In the Appendix 4 presents the output of the F2 model. In terms of overall Speech Condition effects, neither the NK–NK conversation (ConvNK) nor the SK–NK conversation (ConvSK) resulted in significant overall shifts in vowel backness (ConvNK: β=–3.70, SE=4.82, 95% CI: [–13.34, 5.71], p>0.05; ConvSK: β=2.34, SE=4.56, 95% CI: [–6.61, 11.33], p>0.05). These results indicate that vowel backness remained relatively stable across speaking conditions, with no global changes in F2.
Consistent with previous findings (Shin et al., 2012), vowels [i], [e], and [æ] were produced with significantly more fronted tongue positions compared to [ɯ] ([i]: β=28.35, SE=4.84, 95% CI: [18.82, 37.88], p<0.01; [e]: β=55.59, SE=4.72, 95% CI: [46.33, 64.78], p<0.01; [æ]: β=60.67, SE=4.73, 95% CI: [51.37, 69.90], p<0.01). In addition, the vowels [ʌ], [o], and [u] were produced with significantly more backed tongue positions ([ʌ]: β=–58.53, SE=4.55, 95% CI: [–67.61, –49.53], p<0.01; [o]: β=–75.39, SE=4.56, 95% CI: [–84.23, –66.40], p<0.01; [u]: β=–24.04, SE=4.68, 95% CI: [–33.20, –15.02], p<0.01). Although previous research suggested that [ɯ] and [u] tend to approximate in terms of backness, the present findings indicate that these two vowels remained distinct in NK speakers’ production.
Crucially, there were no significant interactions between ConvNK and specific vowels, indicating that vowel backness remained stable in NK–NK conversational speech. However, vowel backness was significantly affected in ConvSK, where NK speakers systematically modified their articulation when interacting with an SK interviewer. Specifically, front vowels [i], [e], and [æ] were produced with significantly more fronting ([i]: β=15.32, SE=4.95, 95% CI: [5.88, 24.97], p<0.01; [e]: β=42.21, SE=4.75, 95% CI: [32.99, 51.51], p<0.01; [æ]: β=40.43, SE=4.77, 95% CI: [31.27, 49.73], p<0.01), whereas back vowels [ʌ], [o], and [u] were produced in significantly more backed positions ([ʌ]: β=–38.33, SE=4.57, 95% CI: [–47.27, –29.35], p<0.01; [o]: β=–50.07, SE=4.58, 95% CI: [–59.11, –41.01], p<0.01; [u]: β=–15.94, SE=4.74, 95% CI: [–25.28, –6.61], p<0.01).
To quantify these articulatory shifts, Cohen’s d effect sizes were computed (see Appendix 5). Overall, ConvSK exhibited stronger vowel backness effects than ConvNK, particularly for back vowels. Front vowel shifts were relatively small, with minor fronting observed for [i] (d=0.10, ConvNK; d=0.09, ConvSK), [e] (d=0.15, ConvNK; d=0.14, ConvSK), and [æ] (d=0.02, ConvNK; d=0.08, ConvSK). In contrast, back vowel shifts showed large effects, particularly for [o] (d=–0.99, ConvNK; d=–0.87, ConvSK) and [u] (d=–1.37, ConvNK; d=–1.33, ConvSK), suggesting substantial backing in conversational speech, especially in the ConvSK condition.
These results indicate that while vowel backness remained stable in NK–NK conversations, NK speakers made systematic articulatory adjustments in ConvSK, exhibiting more extreme fronting and backing patterns depending on vowel type. This pattern may reflect an effort to enhance clarity or to accommodate SK phonetic norms when interacting with an SK interlocutor. The greater backing of [o] and [u] in Conv SK aligns with previous research (Lee et al., 2018; Shin et al., 2012), which suggests that NK speakers adjust vowel articulation to reinforce phonemic contrasts or approximate SK norms in socially sensitive contexts.
4. Discussion
This study examined how NK refugee speakers adjust their vowel production across different speech contexts, including read speech, conversation with a fellow NK interlocutor (ConvNK), and conversation with a SK interlocutor (ConvSK). The findings reveal systematic vowel adjustments based on interlocutor identity, providing crucial insights into SDA and demonstrating that phonetic adaptation is influenced by conversational context.
Speech Condition significantly affected vowel production, notably in vowel height (F1) and backness (F2). In conversational speech (both ConvNK and ConvSK), high vowels ([i] and [ɯ]) were articulated with a higher tongue position compared to read speech, suggesting increased articulatory effort or clarity during conversational interactions. Notably, this raising effect was particularly pronounced during NK-SK interactions (ConvSK), where speakers additionally raised [o] and [u], indicating heightened articulatory precision when conversing with SK interlocutors. Similar condition-dependent adjustments were observed in vowel backness. While backness remained stable in NK-NK conversations, NK speakers systematically fronted front vowels ([i], [e], [æ]) and backed back vowels ([ʌ], [o], [u]) during interactions with SK interlocutors.
These vowel adjustments in ConvSK challenge the common assumption that read speech necessarily involves the most careful articulation. Sociolinguistic research frequently associates read speech with careful, monitored speech patterns (e.g., Labov, 2006); however, NK speakers in this study exhibited greater vowel raising and articulatory modifications in conversational contexts, especially with SK interlocutors. This finding suggests that interactions with SK speakers trigger increased speech monitoring, possibly to enhance intelligibility or reduce the perceptual prominence of the NK accent. Such patterns align with prior research on hyperarticulation and clear speech production (e.g., Chambers & Trudgill, 1998; Edwards, 1999; Foulkes & Docherty, 1999; Labov, 2006; Lippi-Green, 2011; Milroy & Milroy, 1999; Tannen, 1984; Trudgill, 2000, 2001). Nonstandard speakers often experience social pressures to enhance clarity, resulting in hypercorrective articulatory behavior to minimize social stigmatization associated with their accents (Edwards, 1999). Thus, NK speakers may consciously or unconsciously adjust their tongue height and vowel backness to approximate SK phonetic norms when interacting with SK interlocutors.
Nevertheless, despite these articulatory adjustments, NK speakers did not fully converge toward SK vowel norms. Prior research identifies the [e]-[æ] vowel merger as a characteristic feature of SK speech, whereas NK speech typically maintains this distinction (Lee & Idemaru, 2024). In this study, NK speakers did not lower their tongue positions to merge [e] and [æ] during conversations with SK interlocutors. While one possibility is that they did not recognize this merger as a salient feature of SK speech or were unaware that maintaining the [e]-[æ] distinction could index their NK accent, this explanation alone seems insufficient, particularly when contrasted with their convergence patterns for other vowels.
An alternative interpretation, supported by previous findings on phonetic accommodation (e.g., Nielsen, 2011), is that NK speakers may have intentionally resisted convergence in this case to preserve phonological contrast. Merging [e] and [æ] would eliminate lexical distinctions in Korean, potentially leading to ambiguity in communication. Thus, NK speakers may have strategically maintained this contrast to uphold intelligibility, even while showing convergence in other, less contrast-sensitive vowel categories. This pattern suggests that phonetic accommodation might not be uniformly applied across the vowel space but is selectively modulated by the need to preserve phonological contrasts essential for lexical distinction. A key observation is the phonetic consistency of NK speakers across read speech and NK-NK conversations, with significant vowel shifts occurring exclusively during NK-SK interactions. The relative stability of vowel production in NK-NK interactions suggests that phonetic adjustments are specifically motivated by audience design (Rickford & McNair-Knox, 1994), reflecting social pressures and evaluative contexts. Given that NK accents are stigmatized in SK society, adopting SK-like pronunciation may be perceived as evidence of successful assimilation or professional competence (Park, 2023). Therefore, significant vowel shifts in ConvSK contexts likely reflect NK speakers' conscious or subconscious efforts to adapt their pronunciation when feeling socially evaluated or monitored.
While this study provides valuable insights into SDA among NK refugee speakers, certain limitations should be acknowledged. The relatively small sample size limits generalizability; future research should include larger and more diverse participant pools. Additionally, several extralinguistic factors may have influenced vowel production. Familiarity with interviewers rather than their regional identity alone might have impacted vowel articulation, as NK speakers may have felt more comfortable and thus articulated differently with a familiar NK interlocutor. Although speech register was controlled to reduce formality effects, residual effects on vowel articulation might persist. Moreover, the NK-NK conversations occurred approximately one year after NK-SK interactions, meaning NK speakers had additional exposure to SK norms by the second recording, complicating the isolation of interlocutor-specific effects. Future studies should address these limitations, controlling for these variables more rigorously to enhance understanding of SDA phenomena.