





1. 서론
유음(liquids)은 전 세계 언어의 대다수에서 흔히 나타나는 말소리 유형이다(Maddieson, 2013). 영어나 독일어, 터키어와 같은 몇몇 언어에서는 유음이 산출될 때 음성적 및 음운적 변화가 크다고 알려져 있다(Barbour & Stevenson, 1990; Ladefoged & Maddieson, 1996; Mielke et al., 2016; Schmid et al., 2015; Twist et al., 2007; Thomas, 2011). 예를 들어, 영어의 /l/은 일반적으로 치경 유성 설측음으로 실현되지만, 무성 자음 뒤에서는 무성음화가 일어나고, 음절말 위치에서는 연구개음화가 일어나며(Ladefoged & Johnson, 2011), 일부 방언에서는 음운적으로 모음화(vocalization)되거나 ‘침입음-/l/(intrusive-/l/)’이라는 연결 자음으로 기능하기도 한다(Turton, 2023).
한편 한국어는 음소적으로 단일한 유음 /ㄹ/를 가지며, 이것은 일반적으로 두 개의 실현형을 가지는 것으로 기술된다. 음절 초에서는 탄설음 [ɾ]로 실현되고, 음절 말에서나 ㄹ이 연속되는 경우에는 설측 접근음 [l]로 실현된다고 기술하는 것이 일반적이다(Shin, 2014; Shin et al., 2012; Sohn, 1999).
그러나 최근 연구에서는 조음적 관찰에 기반해 /ㄹ/가 다양한 음성형으로 나타난다는 사실이 보고되고 있다. Hwang et al.(2019)에서는 초음파로 20대 서울 여성들의 음성을 분석해 어말 유음이 여러 조음 위치에서 실현될 수 있음을 보여주었는데, 설첨 치음(apico-dental), 설단 후치경음(lamino-postalveolar), 설단치경음(lamino-alveolar), 권설음(retroflex)으로 실현된다고 하였다.
이와 유사하게 Shibata et al.(2024)에서는 20대 한국인 표준어 화자 4명을 대상으로 전자기 조음도(Electromagnetic Articulography)를 사용하여, 음절초와 음절말 위치에서 모두 유음의 설측음화(lateralization)와 권설음화(retroflexion)가 나타남을 확인하였다. 또한 /ㅜ/ 인접 환경보다 /ㅏ/ 인접 환경에서 더 많은 권설음화가 일어나며, /ㅜ/ 인접 환경은 /ㅣ/ 인접 환경보다 더 많은 권설음화가 나타난다고 밝혔다.
40세 이하의 젊은 한국인 표준어 화자를 대상으로 연구를 진행한 Crosby & Dalola(2021)에서는 유음의 권설성의 정도를 나타내는 지표인 제3포먼트 주파수(F3)가 특정 환경에서 낮아진다는 것을 발견하였다. 유음 뒤에 휴지가 존재할 때 유음의 F3는 그렇지 않을 때보다 상대적으로 낮게 나타났다. 그리고 유음의 F3는 /ㅎ/ 앞에서 가장 낮게 나타났다. 그다음으로는 비/ㅎ/자음, 다른 /ㄹ/과 인접할 때, 그리고 초성 위치에 있을 때의 순으로 높아졌다. 이는 젊은 표준어 화자들이 휴지와 /ㅎ/ 앞에서 권설 설측음 [ ɭ ]를 더 자주 사용하는 경향이 있다는 것을 보여준다. 이러한 결과를 검증하기 위해 데이터를 청지각적으로 권설음과 비권설음의 범주로 분류하였을 때, 휴지 앞에서는 권설음이 유음의 지배적인 실현형이라는 것을 발견하였다. 또한, 어두 유음일 때보다는 어중 유음이면서 자음이 후행할 때 권설음화된 유음이 더 빈번하게 나타난다는 것을 확인하였다.
다음으로 Crosby(2024)에서는 23명의 한국어 화자(중부 방언 13명, 경상 방언 8명, 전라 방언 2명)를 대상으로 한국어 유음의 음성적, 지역적 차이 및 언어 스타일 변화를 조사하였다. 먼저, 후설 모음에 후행하는 유음은 전설 모음에 후행하는 유음보다 권설음이 되기 쉽다는 사실을 발견했으며, 고모음에 후행하는 유음보다 저모음 및 중모음에 후행하는 유음도 그러하였다. 또한, 권설음화가 단어 내 위치에 따라 달라지는 양상을 보인다고 보고하였다. /ㅎ/ 앞에서 가장 빈번하게 나타났으며, 그다음으로 어말 환경에서 두 번째로 자주 나타났다. 반면, 자음이 뒤따르는 어중 환경과 겹자음 환경에서는 가장 드물게 나타났으나, 이 두 환경 간에는 통계적으로 유의미한 차이가 없었다. 다만, 이 연구에서 유음 뒤에 오는 자음은 모두 설정음(coronal)이었으므로, 이러한 결과가 다른 조음 위치의 자음에도 동일하게 적용되는지는 확실하지 않다. 둘째, 방언과 성별에 따라 비교했을 때, 경상 방언 화자와 남성 화자는 중부 방언 화자와 여성 화자보다 권설음화된 유음 변이형을 더 자주 사용하는 경향이 있는 것으로 나타났다. 변수 간 상호 작용도 관찰되었는데, 경상 방언 여성 화자가 권설음화된 변이형을 가장 많이 사용하고 중부 방언 여성 화자가 그 변이형을 가장 적게 사용하였다. 마지막으로, 경상 방언 여성 화자들은 틀 문장(carrier phrase) 과제에 비해서 낭독 과제에서 더 빈번하게 권설음화된 변이형을 사용하는 스타일적 변이를 보인 반면, 다른 지역 및 성별 그룹은 그렇지 않았다. 이러한 결과는 매우 흥미로우며 한국어 유음의 새로운 음운적으로 조건화된 변이형이 경남 지역에서 더욱 활발하게 나타난다는 점을 주목할 만하다. 다만, 이 연구에서는 화자 수의 부족으로 인해 계량적으로 검증하지 못한 한계가 존재한다.
이렇듯 기존 연구에서는 유음의 음성적 실현이 다양하다는 사실을 밝히고 이를 해석하려 하였으나, 분석 대상의 음운 환경이 제한되어 있거나 낭독 과제 방식에 국한되어 있는 한계가 있었다. 한국어에서 나타나고 있는 유음의 권설음화 현상은 조음적 요인뿐만 아니라 통시적 변화나 사회언어학적 요인과도 밀접하게 관련될 수 있으므로, 다양한 화자 집단을 포함한 체계적인 분석이 필요하다. 따라서 본 연구에서는 표준어를 사용하는 수도권 화자 20명과 대구 방언을 사용하는 경북 화자 10명을 대상으로, 사진 설명 과제를 통해 준자유발화 자료를 수집하였다. 그리고 유음의 권설성의 정도를 논하기 위해 음향 분석을 통해 정량적인 관점에서의 접근을 시도하였다.
본 연구에서 선택한 음향 분석 방식은, 스펙트럼의 평균 주파수인 CoG(Center of Gravity)를 측정하는 것이다. CoG는 소리의 스펙트럼에서 각 주파수의 진폭에 가중치를 두어 계산한 주파수의 평균값이다. 즉, CoG는 진폭을 고려하여 소리의 주파수에서 중심 경향을 나타내는 지표이다.
선행 연구와 달리 본 연구에서 CoG를 지표로 삼은 이유는 F3보다 연구자의 주관적인 판단이 개입할 여지가 적고 재현 가능성이 높기 때문이다. F3를 측정하려면 연구자가 제1–3포먼트를 식별하거나 LPC 설정을 조정하는 등의 판단을 해야 하며, 이러한 과정은 화자나 모음, 분석 소프트웨어에 따라 달라질 수 있다. 반면 CoG는 전체 스펙트럼을 기반으로 계산되므로, 연구자가 결정해야 할 부분은 주파수 대역 필터링을 적용할지 여부와 적용 범위뿐이다. 이러한 선택 기준은 명확하게 보고할 수 있으며, 분석의 투명성과 재현 가능성을 높이는 데 유리하다. 분석 오류가 발생할 가능성도 훨씬 낮기 때문에 본고에서는 CoG를 측정하기로 결정하였다.
설측 접근음(lateral approximants)을 가진 언어에 대한 연구인 Tabain et al.,(2016)과 Tabain & Kochetov(2018)에 따르면, 권설 설측 접근음(retroflex lateral approximant)의 핵심 특징 중 하나는 CoG가 다른 설측 접근음보다 더 낮다는 것이었다. 따라서 설측 접근음의 권설음화 정도를 계량적으로 파악하기 위해서 CoG 값을 분석하는 것이 유의미한 접근법이 될 것이라 판단하였다.
따라서 본 연구는 20대 화자의 준자유발화 자료를 바탕으로 다양한 환경에서 나타난 유음의 CoG 분석을 수행하고, 이를 통해 유음의 실현 양상을 살펴보고자 한다. 특히 종성 위치의 유음이 권설성을 띠는 변이 현상에 주목하여, 이러한 변이가 나타나는 원인을 언어 내 • 외적 차원에서 고찰하고자 한다. 본 연구에서 중점을 두는 연구 질문은 다음과 같다.
Crosby(2024)의 연구에서 남성 화자가 여성 화자보다 권설음화를 더 자주 사용한다는 결과에 근거하여, 본 연구에서도 남성 화자에게서 권설음화가 더 강하게 관찰될 것이라 예측한다. 또한 지금까지 경북 지역 화자를 다수 포함한 연구는 없으나 Crosby(2024)에서 나타난 경남 지역 화자의 양상을 참고할 때, 같은 경상 방언권에 속하는 경북 화자 또한 수도권 화자보다 권설음화된 유음을 더 많이 산출할 것으로 예측한다. 더불어, 언어 간 상호 영향이 있을 가능성도 고려하고자 한다. 제1언어(L1)가 제2언어(L2) 사용에 영향을 미칠 수 있을 뿐 아니라, L2도 L1 사용에 영향을 미칠 수도 있다고 알려져 있다(Chang, 2012; Seo & Dmitrieva, 2024). 한국인들이 많이 학습하는 L2인 영어와 중국어는 모두 권설 유음을 음소로 포함하고 있으므로(Lin, 2007; Sebregts et al., 2023), 이러한 언어를 학습한 화자라면 조음적 영향을 받을 가능성이 있을 것이다. 따라서 영어나 중국어에 능숙한 화자일수록 한국어 유음 산출 시 권설음화된 유음의 비율도 증가할 것이라 예측한다.
Hwang et al.(2019) 및 Shibata et al.(2024)는 /ㅣ/에 후행하는 /ㄹ/에서는 권설음화가 거의 또는 전혀 나타나지 않는다고 보고하였다. 또한 Crosby(2024)에서는 후설모음, 원순모음, 비고모음 뒤에서 유음의 권설음화 비율이 증가한다고 나타났다. 이에 따라 본 연구에서는 어떠한 선행 모음 뒤에서 권설음화된 유음이 더 많이 출현하는지를 살피고자 한다.
Crosby & Dalola(2021)과 Crosby(2024)에서는 비 /ㅎ/ 자음 앞보다는 /ㅎ/ 앞에서 유음의 권설음화가 더 자주 나타난다고 보고하였다. 따라서 본 연구에서는 유음이 설정 자음 앞에 올 때보다 /ㅎ/ 앞에 올 때 CoG가 더 낮을 것으로 예측한다. 또한 Crosby(2024)에서는 /ㅎ/ 앞에서 나타나는 권설음화가 유음과 후행 설정 자음 간의 동시조음(coarticulation)으로 인해 /ㄹ/의 권설음화가 방해받기 때문일 수 있다고 제시하였다. 이에 따라 본 연구에서는 설정 자음 외의 조음 위치를 가진 자음 앞에서 CoG가 더 낮을 것으로 예측하며, 선행 연구보다 더 다양한 후행 자음 환경을 살펴 후행 자음의 영향력을 규명할 것이다.
Crosby & Dalola(2021)는 유음이 설측음으로 실현된 경우에 F3가 단어 말 위치에서 가장 높고, /ㄹ/와 /ㄹ/가 연쇄될 때는 상대적으로 낮으며, 자음 앞 위치에서는 가장 낮다고 보고하였다. 본 연구에서도 /ㄹ/-/ㄹ/를 겹자음(geminate)으로 간주하며, CoG 또한 이와 같은 패턴(자음 앞<겹자음<어말)을 따를 것으로 예측한다. 또한, 인상적인 관찰에 따르면 /ㄹ/은 단음절 단어에서 더 자주 권설음으로 실현되는 경향이 있다. 따라서 본 연구에서는 단음절 단어에 나타나는 /ㄹ/이 다음절 단어에 나타나는 /ㄹ/보다 CoG가 더 낮을 것으로 예측한다.
2. 연구 방법
본 실험에는 총 30명의 20대 대학생 화자가 참가하였다. 여성 화자 17명, 남성 화자 13명이 참여하였으며, 참가자의 평균 연령은 22.9세(SD 2.9)였다. 참가자는 출신 지역에 따라 크게 두 집단으로 나누어지는데, 수도권 집단 20명(여성 10명, 남성 10명), 경북 집단 10명(여성 7명, 남성 3명)으로 나뉜다. 모든 참가자는 20세 이전까지는 자신의 출신 지역에서 거주하였으며, 해외를 포함하여 타지역 거주 기간은 2년 이하였다. 경북 집단 참가자의 경우, 1명을 제외하고는 모두 대구 지역에서 출생하여 20세 이전까지는 대구에서만 거주한 화자였으며, 1명의 참가자 역시 대구에서 태어나 2세에 3개월간 영천에서 거주한 이력을 제외하고는 20세 이전까지는 대구에서만 거주하였다.
제2외국어 능력이 참가자의 권설음 조음에 영향을 미칠 가능성을 고려하여, 참가자의 정보를 수집하면서 영어와 중국어 능력도 조사하였다. 참가자들은 ‘전혀 없음’, ‘초급’, ‘중급’, ‘고급’, ‘원어민 수준’ 중 하나로 자신의 능숙도(proficiency)를 응답하였다. 영어의 경우 모든 참가자가 학습 경험이 있었으며 ‘초급’ 4명, ‘중급’ 18명, ‘고급’ 7명, ‘원어민 수준’ 1명으로 나타났다. 중국어의 경우 10명의 참가자가 학습 경험이 있다고 응답하였으며, 9명이 ‘초급’, 1명이 ‘중급’ 수준이라고 응답하였다.
참가자는 노트북 화면에 제시되는 사진 슬라이드를 보면서 해당 사진을 자유롭게 묘사하는 과제를 부여받았다. 사진을 보고 발화를 충분히 계획한 뒤에 시작하도록 지시하였으며, 최소 발화 수를 별도로 강제하거나 특정한 단어를 산출하도록 유도하지는 않았다. 즉, 참가자가 자발적으로 자연스럽게 산출한 발화를 수집하는 데에 초점을 두었다.
사진 슬라이드는 연습용 1개를 포함해 총 21개가 제시되었으며, 가능하면 ‘라면’, ‘갈매기’, ‘신발끈’, ‘헬리콥터’와 같이 유음이 포함된 단어를 유도할 수 있도록 사진이 준비되었다. 연습용 슬라이드를 통해 참가자가 과제 수행 방식을 이해한 후에 본 실험을 진행하였으며, 참가자에 따라 수행 시간에 차이는 있었으나 평균 12분 정도 소요되었다.
실험은 녹음을 위해 마련된 고려대학교의 스튜디오 공간 혹은 스터디 카페 내의 조용한 개별 공간에서 진행되었다. Zoom사의 H4n 녹음기와 ABKO사의 MP11 헤드밴드 마이크를 이용하여 진행되었다. 녹음 시 표본 추출률은 44.1 kHz로 설정하였으며, 16 bit로 양자화되었다. 마이크와 참가자의 입은 5 cm의 거리를 유지하도록 조정되었다.
음성 분석에는 Praat 6.4.26(Boersma & Weenink, 2025)을 사용하였다(그림 1). 먼저, 수집된 음성을 전사한 후에 강제 정렬 방식으로 음소 단위의 레이블링을 실시하였다. 그런 다음, 연구자가 분석의 대상이 되는 유음의 경계(boundary)를 모두 수동으로 조정하였다. 본 연구에서 분석 대상으로 삼은 유음은 크게 두 가지로, 발화 초 초성 위치에서 실현된 유음과 종성 위치에서 실현된 유음이다. 초성 유음의 경우, 발화 초로 환경을 한정한 이유는 발화 중에 나타나는 초성 유음은 탄설음으로 실현되는 경우가 거의 대부분이었기 때문이다. 본 연구에서는 권설음화될 가능성이 있는 치경 설측 접근음에 주목하고 있으므로, 발화 초의 초성 유음이 탄설음과 설측 접근음 가운데 무엇으로 실현되었는지 판단하고 레이블링을 수행하였다.
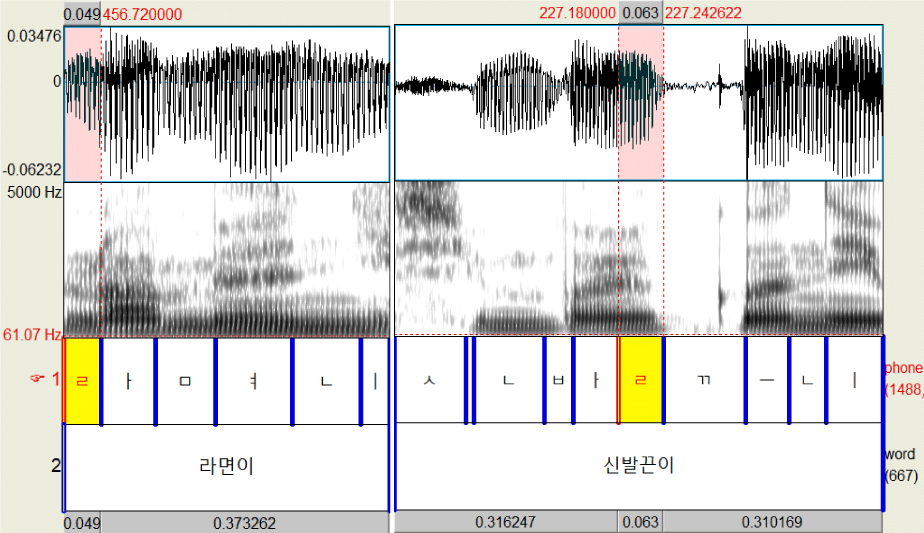
두 명의 연구자가 레이블링 조정 작업을 수행하였기 때문에 작업 전에 충분한 기준안을 마련하고 연습 레이블링을 진행하여 일치율을 확인하였다. 분석이 완료된 후에는 서로의 작업물을 교차 검토하며 세 차례의 재조정을 수행하였다.
이러한 과정을 거쳐 분석 대상이 된 유음 토큰은 총 2,002개이며, 이를 대상으로 CoG 분석을 수행하였다. Erker(2010)가 제시한 CoG의 계산식은 수식 (1)과 같다.
I: 진폭 (dB), f = 주파수 (Hz) Erker (2010: 13)
각 토큰의 CoG는 Praat 스크립트를 이용하여 분석 대상 구간의 정가운데 지점에서 추출되었다. 먼저 Tabain et al.(2016)를 따라 1,000 Hz 이상, 5,000 Hz 이하의 주파수만 통과시키는 밴드패스 필터링을 수행하여, 성대 진동과 고주파 잡음(high-frequency noise)의 영향을 줄였다. 그런 다음 분석 구간을 10등분하여 각각의 지점의 CoG를 추출하였으며, 분석에는 가장 안정된 구간이라 할 수 있는 0.5 지점의 값만 이용하였다.
또한, CoG 값은 성도(vocal track) 길이에 따라 달라지기 때문에 언어 내적인 요인을 검토할 때는 CoG 값을 정규화하여 논의하였다. 이때 Dalola & Bridwell(2019, 2020)에서 제시한 정규화 방법을 이용하였는데, 이 방법에서는 COGnorm=si × COG로 정의된다. 여기서 si는 화자별 정규화 계수(speaker-dependent normalization coefficient)를 의미하며, si=COGavg / COGi의 방식으로 계산된다. COGi는 개별 참가자 i의 평균 CoG 값이고, COGavg는 모든 참가자의 평균 CoG 값을 의미한다.
한편, Dalola & Bridwell(2023)에서는 혼합효과 모델에서 화자를 무작위 효과로 포함하면 화자 간 성도 길이 차이에 의한 변이를 충분히 제어할 수 있으므로 정규화가 불필요하다고 주장하였다. 그러나 해당 연구에서는 정규화 여부에 따른 모델 간 비교나 검증이 이루어지지 않았으므로 실증적 타당성은 제한적이다. 이에 따라 본 연구에서는 보다 신중한 접근을 위해 원자료와 정규화된 CoG 모델을 모두 분석하고 논의하였다.
통계 모델의 과도한 복잡화를 방지하고 변수 간 효과를 명확히 해석하기 위해, 선행 분절음이 단모음이고 후행 분절음이 자음인 경우로 분석 토큰을 한정하여 통계 모델을 설계하였다. 이에 따라 총 1,652개의 유음 토큰이 분석 대상으로 선정되었으며, CoG의 정규화 과정을 거친 후에 이상치(outlier)를 제거하는 작업을 하였다. 본 연구에서 이상치는 제3사분위수(third quartile, Q3)보다 1.5배 이상 사분위 범위(interquartile range)를 초과하는 값으로 정의하였다. 분석 자료에서 정규화된 CoG의 최솟값은 849.1 Hz, 중앙값은 1,764.0 Hz, 최댓값은 3,488.4 Hz로 나타났으며 Q3 값은 1,996.0 Hz이다. 유음의 특성상 CoG 값이 3,000 Hz 이상이 되는 것은 부자연스럽기 때문에 2,668.58 Hz를 초과하는 값을 제거하였다. 최종적으로 1,624개의 토큰이 남았고, 이 토큰들로 선형 회귀 분석을 진행하였다.
권설음화에 영향을 미치는 요인을 검증하기 위해, 선행절에서 설명하였듯이 rawCoG와 정규화된 CoG를 각각 종속 변수로 하는 두 개의 선형 혼합효과 모델(linear mixed‑effects model)을 구축하였다. 구축 과정에서 Schweinberger(2025)을 참고하여 변수를 점진적으로 추가하는 step-up stepwise model selection procedure를 적용하여 다양한 모델을 비교 분석해 보았다. 그리고 과적합(overfitting)을 방지하고 해석의 용이성을 우선하기 위해, AIC(Akaike information criterion)나 우도비 검정에 의존하기보다는, 수렴에 성공하면서 특이성(singularity) 문제가 없는 모형들 중 BIC(Bayesian information criterion)이 가장 낮은 모형을 최종 모델로 채택하였다. BIC는 파라미터 추가에 더 강력한 패널티를 부과하므로, 보다 단순하고 일반화 가능성이 높은 모형을 선택하는 데 유리하다는 강점이 있다. 그리고 모형 비교 시 BIC 값을 일관되게 계산하기 위해 모든 후보 모형을 최대우도추정법(Maximum Likelihood)으로 구축하였다. 최종적으로는 제시된 모형의 계수 추정치는 제한최대우도추정법(REML)으로 적합된 결과를 보고하였다.
고정 효과(fixed effects) 후보로는 다음을 모델 구축 과정에 포함하였다. 우선 언어 외적 요인으로는 화자의 성별(여성, 남성)과 출신 지역(수도권, 대구), 영어 능숙도(없음, 초급, 중급, 고급, 원어민 수준), 중국어 능숙도(없음, 초급, 중급)를 포함하였다. 그리고 성별과 출신 지역, 성별과 영어 능숙도, 성별과 중국어
능숙도의 상호작용을 포함하였다. 다음으로 언어 내적 요인으로는, 선행 단모음의 후설성(전설 모음, 후설 모음), 후행 자음의 조음 위치(양순음, 치경음, 치경경구개음, 연구개음, 성문음)1, 운율 환경(단음절 어말, 다음절 어말, 다음절 어중, 겹자음)2, 언어 내적 요인 변수 간의 2-way 및 3-way 상호작용을 포함하였다.
한편, 정규화된 CoG 모델을 설계하는 과정에서는 성별과 출신 지역 등의 화자 관련 요인은 후보 변수로 포함되지 않았다. 이는 정규화 과정에서 화자 간 변이가 제거되기 때문에, 성별과 같은 변수를 포함할 경우 모델 특이성이 발생하여 모델을 실행할 수 없기 때문이다.
또한 영어와 중국어에 대한 자기 보고식 능숙도 정보도 함께 수집하였으나, 해당 변수도 다음과 같은 이유로 최종 통계 모델에는 포함되지 않았다. 첫째, 언어 능숙도의 분포가 참가자 간에 불균형하였다. 둘째, CoG 값 또한 언어 능력 수준에 따라 뚜렷한 차이를 보이지 않았다. 셋째, 영어 및 중국어 능력(혹은 성별과의 상호작용)을 포함한 모델은 BIC 기준에서 모형 적합도를 개선하지 않았다. 영어 및 중국어 능숙도, 그리고 이들의 성별과의 상호작용 효과를 단계적 모형 구축 과정 전반에 걸쳐 포함하여 검토하였으나, 해당 변수들이 포함된 모든 모형은 경쟁 모형보다 BIC가 높게 나타났다. 예를 들어, 최적 모형과 영어 능숙도를 추가한 모형을 anova() 함수로 비교했을 때 각각의 BIC는 22,840과 22,844였다. 중국어 능숙도나 영어 능숙도 × 성별 상호작용을 추가한 경우에는 22,851로 증가하였으며, 중국어 능숙도 × 성별 상호작용을 추가하면 22,857로 더욱 증가하였다. 이러한 결과는 외국어 능숙도 관련 변수를 포함하는 것이 모형 적합도를 개선하지 않고 오히려 저하시킴을 보여준다. 따라서 이후 통계 분석에서는 외국어 능숙도 변수는 고려하지 않을 것이다.
무작위 효과(random effects) 후보로는 화자 및 단어에 대한 무작위 절편과 화자별 및 단어별 다섯 개 주요 고정 효과에 대한 무작위 기울기를 포함하였다. rawCoG 모델의 경우, BIC 기준에서 ‘단어 무작위 절편과 화자별 선행 모음 무작위 기울기’ 구조가 선택되었다. 그리고 정규화된 CoG 모델에서는 ‘단어 무작위 절편’ 구조가 선택되었다.3
통계 모델은 R 소프트웨어(R Core Team, 2024)의 lmerTest(Kuznetsova et al., 2017)의 lmer() 패키지를 사용하여 구축되었다. 최적의 rawCoG 모델은 다음과 같은 R 코드로 구축되었다: lmer(CoG~1+preceding Vowel+following PlaceOfArticulation + prosodic Environment+gender+(preceding Vowel | participant)+(1 | word). 최적의 normCoG 모델은 여기에서 gender를 제외하여 구축되었다.4 normCoG는 화자별 정규화를 거친 값이므로 성별과 같은 화자 간 변인의 효과는 본질적으로 제거되었기 때문이다. 실제로 성별을 포함한 모델은 특이성 문제가 발생하여 최종 모델에서 제외하였다. 그리고 기준 수준(reference level)이 아닌 다른 수준들 간의 상대적 차이를 해석하기 위해, emmeans패키지(Lenth, 2023)를 사용하여 추정 한계 평균(marginal means)을 산출하고, Tukey 방식으로 보정된 사후 비교를 수행하였다. 그리고 시각화에는 ggplot2(Wickham, 2016)와 sjPlot(Lüdecke, 2024) 패키지를 사용하였다.
3. 연구 결과 및 논의
본 연구에서 분석의 대상으로 삼은 유음 토큰은 총 2,002개이며, 이 가운데 발화 초 초성 유음은 55개이고, 종성 유음은 1,947개로 나타났다. 각 유형별로 CoG의 평균 및 표준편차 값을 제시하면 아래의 표 1과 같다.
| 구분 | 토큰 수 (개) | CoG (Hz) | ||
|---|---|---|---|---|
| 평균 | 표준편차 | |||
| 초성 | 탄설음 | 35 | 1,658.92 | 522.46 |
| 설측음 | 20 | 1,653.76 | 192.26 | |
| 종성 | 1,947 | 1,796.43 | 341.69 | |
한국어에서 초성 /ㄹ/은 탄설음으로 실현된다고 알려져 있으나, 실제 자료를 분석한 결과 설측 접근음으로 실현된 경우도 상당수 관찰되었다. 탄설음으로 실현된 토큰들의 지속 시간은 평균 27.177 ms이고 설측음으로 실현된 토큰들의 지속 시간은 53.66 ms로 나타났다. One-sided Welch’s two-sample t-test 결과, 설측음으로 실현된 토큰이 탄설음으로 실현된 토큰보다 유의하게 더 길어[t(30.55)=5.94, p<.001], 길이의 측면에서도 서로 다른 음성형으로 실현되었음을 확인할 수 있었다. 그리고 설측음으로 실현된 경우에는 권설성이 수반되는 경우도 존재하였다.
그러나 본 연구에서는 선행 분절음의 영향을 받지 않도록 발화 초에 나타난 초성만을 분석하였기 때문에, 분석 대상으로 삼을 수 있는 토큰이 절대적으로 부족하여 논의를 적극적으로 진행하기는 어렵다고 판단하였다. 따라서 이후 논의에서는 종성 위치의 유음 토큰으로 분석 대상을 한정하고자 한다.
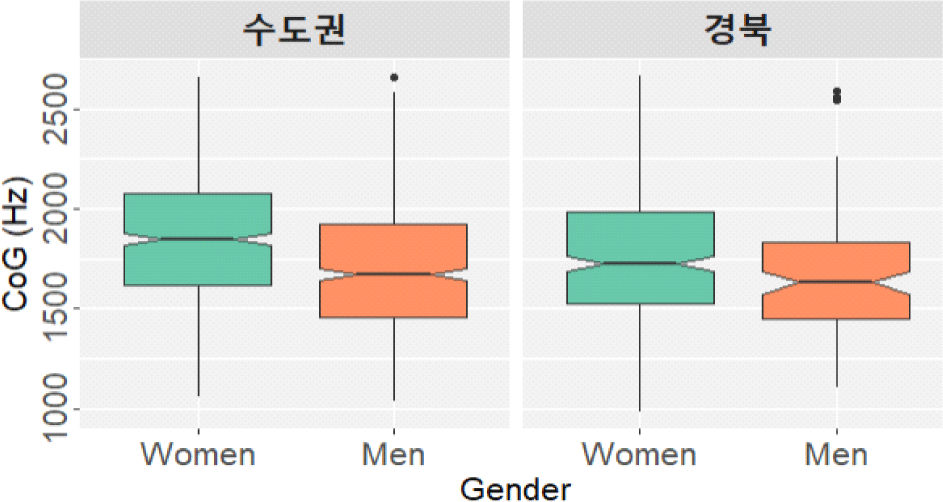
본 연구에서 주목한 언어 외적 변수는 참가자의 출신 지역과 성별, 영어 및 중국어 능숙도였다. Crosby(2024)에서는 수도권 지역보다는 경상 지역의 화자들에게서, 그리고 여성보다는 남성에게서 권설음화된 유음을 더 빈번하게 관찰하였다. 본 연구 결과에서도 그러한 발견과 궤를 같이 하는 양상이 나타났다.
위의 표 2는 참가자의 출신 지역과 성별에 따라 종성 유음의 토큰 수와 CoG 평균 및 표준편차를 제시한 것이다. 평균 CoG를 비교해 보면, 수도권 집단에서는 1,823.75 Hz, 경북 집단에서는 1,749.67 Hz로 나타나, 경북 집단에서 CoG 값이 상대적으로 낮게 나타났다. 성별에 따라서 세분해 보면 그 차이가 조금 더 드러나는데, 수도권 여성 집단의 평균 CoG가 1,934.69 Hz로 가장 높고, 다음으로 경북 여성 집단이 1,771.45 Hz, 수도권 남성 집단이 1,746.29 Hz로 서로 비슷하게 나타났다. 가장 낮은 평균값을 보인 집단은 경북 남성으로 1,665.76 Hz로 나타났다.
| 구분 | 토큰 수 (개) | CoG (Hz) | ||
|---|---|---|---|---|
| 평균 | 표준편차 | |||
| 수도권 | 여성 | 652 | 1,934.69 | 353.07 |
| 남성 | 642 | 1,746.29 | 291.65 | |
| 경북 | 여성 | 514 | 1,771.45 | 362.01 |
| 남성 | 139 | 1,665.76 | 304.21 | |
이러한 결과는 각 집단별로 CoG 값의 분포를 상자그림으로 나타낸 그림 2에서도 잘 드러난다. 수도권 집단에 비해 경북 집단의 CoG가 낮게 분포하였으며, 여성 집단에 비해 남성 집단의 CoG가 낮게 분포하는 걸 볼 수 있었다. 다시 말해, 경북 집단과 남성 집단에서 권설음화된 유음이 더 많이 나타난 것이다.
위의 그림 3은 외국어 능숙도 및 성별에 따른 CoG 값의 분포를 상자그림으로 나타낸 것이다. 영어의 경우 모든 참가자가 학습 경험이 있다고 답하였으며 능숙도는 ‘초급’ 4명, ‘중급’ 18명, ‘고급’ 7명, ‘원어민 수준’ 1명으로 분포하였다. 중국어의 경우 전체의 1/3에 해당하는 10명의 참가자가 학습 경험이 있다고 답하였으며, ‘없음’ 20명, ‘초급’ 9명, ‘중급’ 1명으로 나타났다.
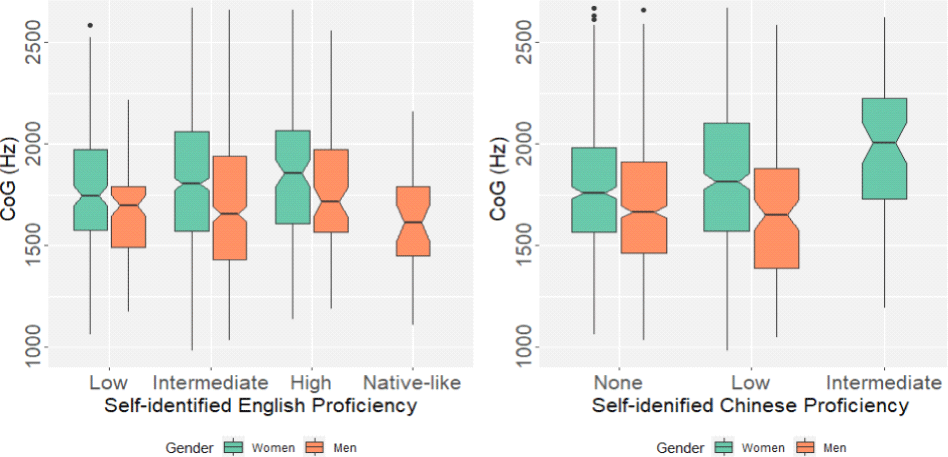
여성 집단에서는 외국어의 능숙도가 높을수록 CoG 중앙값이 높아지는 경향이 보인 반면, 남성 집단에서는 외국어의 능숙도와 CoG의 상관이 크게 두드러지지 않았다. 본 연구에서는 영어와 중국어에는 권설 자음이 있기 때문에 이러한 외국어에 능숙한 화자는 한국어 유음을 발음할 때도 권설음화된 유음을 산출할 가능성이 높으리라 예상하였다. 그러나 외국어 능숙도와 CoG 간에 통계적으로 유의한 상관이 관찰되지는 않았으며, 여성 집단은 오히려 본고의 가설과 반대의 양상을 보였다.
언어 외적 요인에 따라 살펴본 결과, 성별과 지역이 유음의 CoG에 영향을 주는 요인임을 확인할 수 있었다. 상술하였듯이, CoG 값은 성도의 길이에 영향을 받는 값이기 때문에 성별에 따른 차이가 나타나는 것은 당연한 결과라 할 수 있다. 따라서 종성 유음의 권설음화에 영향을 미치는 언어 내적 요인을 중점적으로 살피기 위해서는 정규화가 필요하다고 판단하였다. 이하의 절에서는 정규화한 CoG 값을 제시하며, 이를 ‘normCoG’로 구분하여 기술할 것이다.
아래의 표 3에는 선행 모음을 기준으로 유음의 토큰 수와 CoG 평균 및 표준편차를 제시하였다.
본 연구 자료에서 종성 유음 앞에 단모음이 선행된 경우는 총 1,855개로, 이중모음이 선행된 경우(92개)보다 현저히 많았다. 또한, 선행 이중모음은 /ㅕ, ㅘ, ㅝ, ㅠ/에 한정되어 나타났다. 실험 과정에서 이중모음에 후행할 경우 유음의 권설음화가 발생할 가능성이 높은 경향이 관찰되었으나, 실험 과제의 특성상 선행 모음이 이중모음인 토큰을 충분히 확보할 수가 없어 통계적으로 검증하기 어려웠다. 게다가 이중모음을 분석에 포함할 경우 전체 모델의 결과를 왜곡할 우려가 있어, 이하에서는 단모음이 선행된 환경에 한정하여 분석을 진행하고자 한다.
선행하는 단모음별로 종성 유음의 토큰 수와 정규화된 CoG의 평균값 및 표준편차를 제시하면 위의 표 4와 같다. 유음의 normCoG가 가장 높은 경우는 전설 중모음 /ㅔ/가 선행할 때로, 2,070.33 Hz로 평균값이 나타났다. 전설 고모음 /ㅣ/가 선행할 때도 2,046.39 Hz로 유사하게 높은 값이 나타났다. 반면, normCoG가 가장 낮은 경우는 원순 후설 중모음 /ㅗ/가 선행할 때로 1,458.75 Hz의 값을 보였으며, 평순 후설 중모음 /ㅓ/가 선행할 때도 1,575.28 Hz라는 낮은 값이 나타났다.
이러한 양상은 선행 단모음별로 정규화된 CoG 값의 분포를 보여주는 위의 그림 4를 통해 더욱 간명하게 알 수 있다. 그래프에서 전설 모음인 /ㅔ, ㅣ/는 초록색 상자로 표현되었고, 후설 모음들은 주황색 상자로 표현되었다. 상자의 분포에서 두 모음 그룹은 확연한 차이를 보인다. 유음이 전설 모음에 후행할 때보다 후설 모음에 후행할 때 CoG가 낮은 경향이 있으며, 이는 후설 모음 뒤에서 권설음화 되는 경우가 많음을 의미한다.
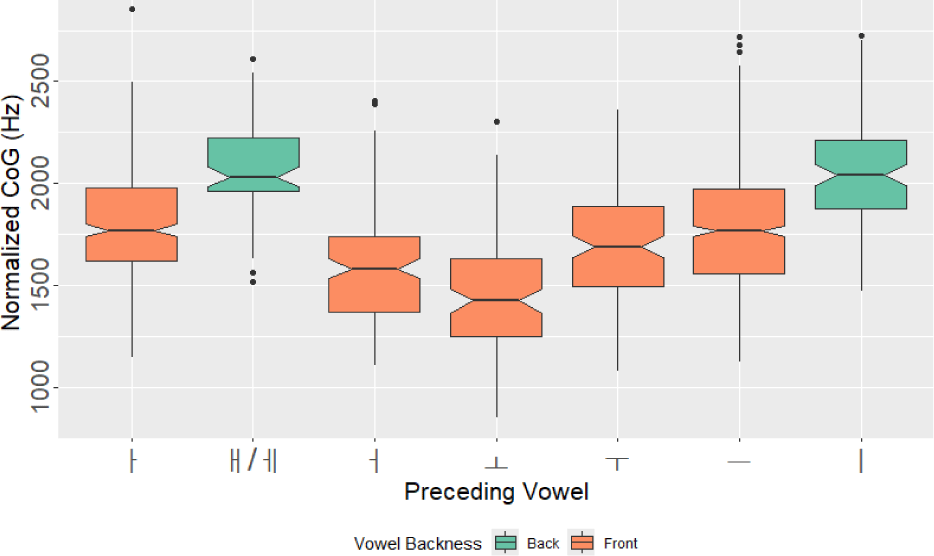
한편 본고의 자료에서 모음의 고저 차이나 원순성 유무는 CoG와 뚜렷한 관련이 없는 것으로 나타났다. 비원순 모음보다는 원순 모음에 후행할 때 유음의 CoG가 낮은 편이고, 선행 모음 산출 시 혀의 높이가 낮을수록 유음의 CoG가 낮은 경향성이 관찰되기는 하였으나 이를 적극적으로 해석하기는 어렵다.
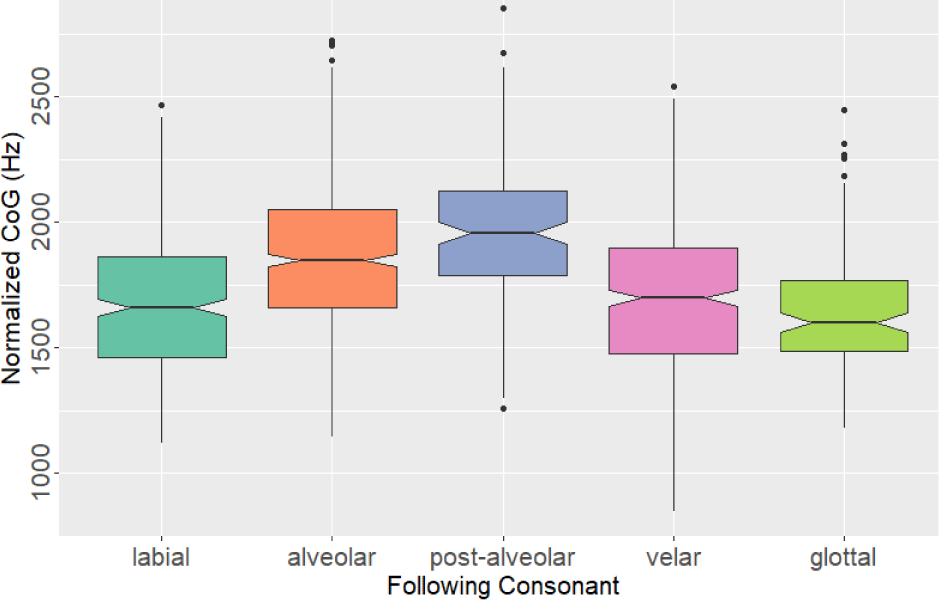
아래의 표 5에는 후행 자음을 기준으로 유음의 토큰 수와 정규화된 CoG 평균 및 표준편차를 제시하였다.
유음의 normCoG가 가장 높은 경우는 치경경구개 마찰음 /ㅅ/가 후행할 때로, 2,144.80 Hz의 평균값을 기록하였다. 치경경구개 마찰음 /ㅆ/가 후행할 때도 평균값이 2,071.40 Hz로 유사하게 높게 나타났다. 그 외에도 후행 자음이 치경경구개음인 경우에 normCoG가 전반적으로 높게 나타나, 5개의 조음 위치 가운데 가장 높은 평균값을 보였다. 이와 대조적으로 양순 폐쇄음 /ㅃ/와 /ㅂ/가 후행할 때 normCoG의 평균값은 각각 1,532.22 Hz, 1,582.91 Hz로 가장 낮게 나타났다.
그림 5는 후행 자음의 조음 위치에 따라 유음의 CoG 값의 분포를 상자그림으로 나타낸 것이다. 유음의 CoG 값은 후행 자음이 치경경구개음일 때 가장 높게 나타났으며, 치경음, 연구개음, 양순음, 성문음의 순으로 중앙값과 분포 범위가 점차 낮아지는 경향을 보였다. 즉, 유음 뒤에 양순음이나 성문 마찰음 /ㅎ/가 올 때, 유음이 권설성을 띠는 경우가 많다고 할 수 있다. 일반적으로 한국어에서 /ㄹ/와 /ㅎ/이 연쇄하면 /ㅎ/가 탈락하는 편인데, 탈락하지 않은 경우에는 선행 유음의 권설성이 높은 경우가 많다는 사실이 흥미로운 지점이라 할 수 있다.
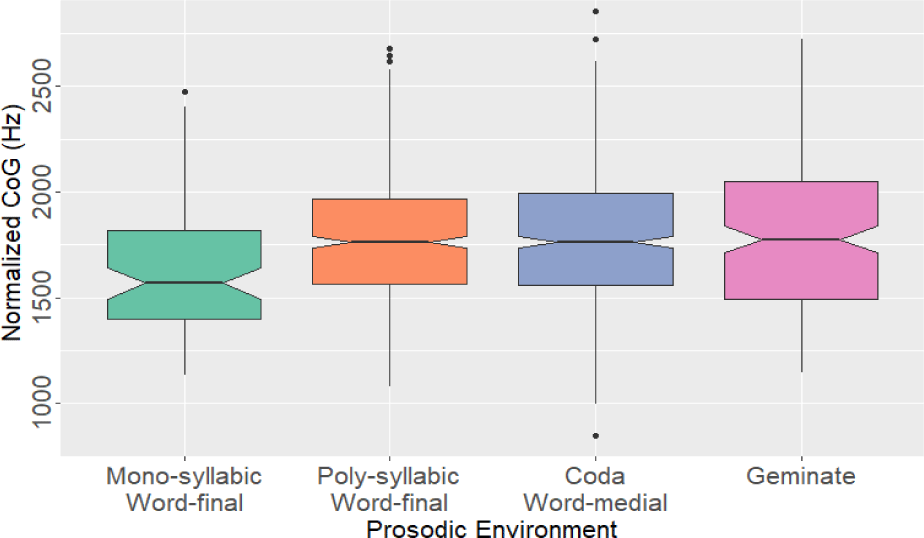
아래의 표 6에는 운율 환경별 유음의 토큰 수와 정규화된 CoG 평균 및 표준편차를 제시하였다.
| 구분 | 토큰 수 (개) | 정규화된 CoG (Hz) | ||
|---|---|---|---|---|
| 평균 | 표준편차 | |||
| 단음절 어말 | 88 | 1,635.89 | 299.85 | |
| 다음절 | 어말 | 668 | 1,770.59 | 285.52 |
| 어중 | 677 | 1,780.56 | 317.81 | |
| 겹자음 | 199 | 1,794.94 | 358.98 | |
| 전체 | 1,624 | 1,771.10 | 310.93 | |
유음의 CoG 값은 평균적으로 단음절 어말 위치에서 가장 낮게 나타났으며, 유음의 연속되는 겹자음 환경에서 가장 높게 나타났다. 다음절 어말과 어중 환경의 CoG 값도 겹자음 환경과 유사하게 나타나, 다음절 환경과 단음절 환경이 대조적인 양상을 보였다. 다만 그 값의 차이는 크지 않았다.
아래의 그림 6의 상자 그림으로 살펴보아도 이러한 차이를 확인할 수 있다. 가장 왼쪽에 위치한 단음절 어말 환경의 상자를 보면, 중앙값이 다른 환경에 비해 상대적으로 낮은 것으로 나타났다. 사분면의 범위는 환경 간에 큰 차이를 보이지는 않았으나, 겹자음 환경에서 다소 범위가 넓게 나타났다.
rawCoG의 최적 혼합효과 모델에서는 선행 모음의 후설성, 후행 자음의 조음 위치, 운율 환경, 성별에 대한 주효과(main effects)가 나타났다. 아래의 표 7은 이 모형의 결과를 요약한 것이다. 이때 기준 수준이 되는 것은 선행 모음은 ‘전설 모음’이고, 후행 자음은 ‘치경음’이며, 운율 환경은 ‘단음절 어말’이며, 화자의 성별은 ‘여성’인 경우이다.
위의 표 7에서 Estimates가 음수인 경우에는 CoG가 감소할 것으로 예측되며, 양수인 경우에는 CoG가 증가할 것으로 예측된다. 즉 음수값인 환경에서는 권설성이 강하게 나타나고, 양수값인 환경에서는 권설성이 약하게 나타날 것임을 의미한다. 예를 들어, 최상단에 표시된 ‘–248.09’라는 값은, 후설 모음에 후행하는 유음이 전설 모음에 후행하는 유음보다 CoG가 248.09 Hz 낮을 것으로 예측됨을 의미한다. 다시 말해, 다른 모든 변인이 기준 수준에 고정되어 있다고 가정할 때, 후설 모음 다음에 오는 유음의 CoG는 모델의 기본 추정값인 2,051.17 Hz에서 248.09를 뺀 1,803.08 Hz로 예측된다.
정규화된 CoG의 최적 혼합효과 모델에서도 동일하게 선행 모음의 후설성, 후행 자음의 조음 위치, 운율 환경에 대한 주효과가 나타났다. 아래의 표 8에는 정규화된 CoG 선형 회귀 모델의 결과가 요약되어 있다.
통계 분석 결과, rawCoG 모델에서 성별에 따른 유의미한 주효과가 나타났으며 남성이 여성에 비해서 CoG가 139.36 Hz 낮은 것으로 나타났다(p<.01). 즉, 남성이 여성보다 유음을 권설음화하여 발음하는 경향이 있는 것을 알 수 있다. 이러한 결과는 한국어 유음을 산출할 때 남성이 여성보다 더 많이 권설음화를 실현했다는 Crosby(2024)의 분석 결과와도 일치한다.
게다가 rawCoG 모델과 정규화된 CoG 모델의 유사성은, 화자를 무작위 효과로 포함하는 것만으로도 성도 길이 등 생리적 차이를 통제할 수 있다는 Dalola & Bridwell(2023)의 주장에 힘을 실어준다. 이에 따라, CoG 모델에서 성별 효과가 유의미하게 나타났다는 점은 단순한 생리적 요인이라기보다는 언어적 패턴일 가능성이 높다. 즉, 남성 화자가 여성 화자보다 유음을 더 자주 또는 더 강하게 권설음화하는 경향을 보이며, 이는 사회음운론적 차원에서의 성별에 따른 차이가 있는 것임을 시사한다.
남성 집단이 권설음화된 유음을 더 활발하게 산출하는 이유는 본 연구 자료로만 설명하기는 어렵지만, 몇 가지 가능성을 제시할 수 있다. 우선, 권설음화된 유음은 남성 화자들 사이에서 ‘은밀한 위신(covert prestige)’을 지닌 것일 수 있다. 은밀한 위신이란 사회적으로 공인된 표준 언어와는 다르지만 특정 집단 내에서 남성성, 소속감, 친근함 등을 나타내는 비표준적 발화 방식에 긍정적 가치를 부여하는 현상을 말한다(Trudgill, 1972). 혹은, 유음의 권설음화는 화자 스스로도 인식하지 못한 채 진행되는 ‘아래로부터의 변화(change from below)’의 일환일 수 있다. 아래로부터의 변화란 사회 전반에서 인지되기 전에 비공식적인 대화나 특정 하위 집단 내에서 먼저 나타나는 음성적 변화 양상을 뜻한다(Labov, 1994). 이러한 관점에서 생각해 볼 때, 권설음화는 현재 사회적으로 인식되지 않고 있지만, 특정 집단 내에서 점차 확산되고 있는 음성적 변화일 수 있다. 다시 말해, 사회적 인식 없이 조용히 확산되고 있는 발화 습관일 가능성이 있다는 뜻이다. 따라서 향후 연구에서는 권설음화의 사회언어학적 함의를 보다 심층적으로 탐구할 필요가 있다.
한편, 화자의 출신 지역 변수는 raw CoG 모델을 step-up stepwise 방식으로 최적화하는 과정에서 제외되었는데, 이는 수도권과 경북 화자 간 권설음화 양상이 통계적으로는 유의미한 차이를 보이지 않음을 시사한다. 즉, 선행 연구를 기반으로 경북 방언 화자가 더 많은 권설음화를 보일 것이라 예상한 것과는 다른 결과이다. 그러나 이 결과는 신중하게 해석할 필요가 있다. 지역 변수를 고정 효과로 추가하면 BIC는 약간 증가(22,840→22,844)하지만, AIC는 감소(22,759→22,758)하고, 모델의 우도는 소폭 개선되며(χ2(1)=3.0724, p=0.07963), 지역 효과는 거의(marginally) 유의한 것으로 나타난다(추정치=–83.47, p=0.09707). 이는 통계적으로 유의하지는 않지만, 중부 방언권 화자보다 경남 화자가 더 많이 권설음화를 실현했다는 Crosby(2024)의 결과와 유사한 양상이다. 특히, 혼합효과 모델은 표본 수가 적을 경우 제2종 오류(Type II error)가 증가하는 경향이 있음이 잘 알려져 있으므로, 지역 변수가 유음의 권설음화에 영향을 주는 요인일 수 있다는 가능성을 무시해서는 안 된다. 따라서 향후 연구에서는 보다 많은 화자 수와 지역 간 균형을 고려한 자료를 통해 권설음화에 대한 지역 효과를 보다 면밀히 검토할 필요가 있다.
화자의 영어 및 중국어 능숙도 역시 CoG 값과 뚜렷한 관련성이 나타나지 않았으며, 통계 모델을 최적화하는 과정에서 포함되지 않았다. 영어 및 중국어에는 권설 자음이 존재하기 때문에 이러한 외국어에 능숙한 화자일수록 한국어 유음을 산출할 때도 권설음화하여 발음할 가능성이 높다는 것이 본고의 가설이었다. 하지만 남성 집단의 경우에는 특정한 경향성을 보이지 않았으며, 여성 집단의 경우에는 외국어 능숙도가 높을수록 CoG 값이 높아지는 경향성을 보였다.
이는 학습자가 외국어 실력이 향상될수록 제2언어(영어/중국어)의 음소 범주(/ɹ/)와 모국어의 /l/ 범주를 명확히 구분하려는 경향에서 비롯된 것일 수도 있다. 실제로 L2 학습자가 L1과 L2의 유사한 음소 간의 음향적 중첩을 회피하기 위해, L1 음소의 실현 양상을 조절하는 경향이 있음이 선행 연구에서 보고된 바 있다. 예를 들어, Harada(2003)는 일본어를 모어로 하는 영어 학습자들이 영어 유성 폐쇄음과의 중첩을 피하기 위해, 일본어 무성 폐쇄음의 VOT(성대 진동 시작 시간)를 일본어 단일언어 화자보다 더 길게 산출한다고 보고하였다.
다시 말해, 오히려 외국어에 능숙할수록 모국어와의 조음적 차이를 분명하게 인지하고 있어, 외국어 능숙도가 높을수록 권설음화된 유음을 적게 산출한 것으로 볼 수 있으나 본고의 자료로 이러한 적극적인 해석을 하기에는 무리가 따른다. 그리고 외국어 능숙도와 성별이 복합적으로 작용할 가능성도 확인하였으므로, 향후 연구에서는 이들 변인을 면밀히 통제하여 유음 산출에 미치는 영향을 면밀히 비교해 볼 필요가 있다.
다음으로 언어 내적 요인을 살펴보면 선행 모음에서 주 효과가 관찰되었으며, 유음의 CoG는 전설 모음이 선행할 때보다 후설 모음이 선행할 때 유의하게 낮게 나타났다(p<.001). 이러한 결과는 /ㅣ/ 근처에서 한국어 유음이 거의 혹은 전혀 권설음화되지 않는다는 이전 연구(Hwang et al., 2019; Shibata et al., 2024) 및 일반적으로 전설 모음 환경에서 권설음화가 덜 일어난다는 연구 결과(Crosby, 2024)와 일치한다.
조음적인 관점에서도 이를 설명할 수 있는데, 권설음을 산출하기 위해서는 설첨(tongue tip)이 구개 뒤로 말려야 하지만, /ㅣ/와 같은 전설 모음을 조음할 때는 설첨이 이미 구개 바로 뒤쪽에 위치하므로 이러한 권설 동작을 하기 어렵다. 따라서 선행 모음이 후설 모음일 경우에 유음이 권설음화되기 더 쉽다고 할 수 있다. 이러한 경향은 한국어에 국한되지 않으며, 권설음은 전 세계적으로 고 • 중 전설 모음에 후행하는 환경을 회피하는 경향을 보인다는 보고와도 부합한다(Hamann, 2004). 예컨대 노르웨이어, 중국어, 톨리톨리어 등에서는 이러한 회피 전략이 음운론적 제약이나 대립을 통해 실현되는 것으로 보고되어 있다.
다음으로, 후행 자음의 조음 위치 역시 유의미한 주 효과를 보였다. 기준 수준인 치경음과 비교하였을 때, 양순음이 후행하는 경우에는 유음의 CoG와 정규화된 CoG가 더 낮았다(p<.001). 연구개음과 성문음이 후행하는 경우에도 유의하게 CoG가 낮은 것으로 나타났다(p<.001). 반면, 치경경구개음이 후행하는 경우에는 유의미한 차이가 없었다(p=.090).5 Tukey 방식으로 보정된 사후 비교 결과6, 치경경구개음은 모든 비-설정(non-coronal)과의 비교에서 유의미한 차이가 나타났으며(p<.001), 양순음-연구개음의 비교를 제외하고는(p=.0230, 추정치=–77.360)7 모든 비-설정자음 간에는 유의한 차이가 나타나지 않았다. 이는 CoG 값에서 설정음과 비-설정음 사이의 범주적 구분이 존재함을 시사하며, 유음 뒤에 비-설정 자음이 올 때 권설음화가 더 자주 나타나는 경향이 있음을 시사한다.
이는 유음 뒤에 성문음이 오는 경우, 그렇지 않은 경우보다 유음이 권설음으로 실현될 가능성이 높다고 보고한 Crosby(2024)의 결과와도 부분적으로 일치한다. 다만 Crosby(2024)에서 분석한 비-/ㅎ/ 자음은 치경음에 국한되어 있었기 때문에, 모든 조음 위치를 검토한 본고의 결과가 해당 현상을 보다 정밀하게 설명한다고 할 수 있다. 즉, 후행 자음의 조음에 설첨이나 설단(tongue blade)이 관여하지 않을 경우, 선행하는 유음을 산출할 때 더 자유롭게 권설 동작을 할 수 있다고 해석할 수 있다.
이러한 결과는 일부 언어에서 관찰되는 ‘권설음 조화(retroflex harmony)’ 현상과도 관련될 수 있다. 권설음 조화란 동일한 형태론적 또는 음운론적 단위 내에서 모든 설정음이 설단음 또는 비-설단음으로 일관되게 실현되어야 하는 제약을 의미한다. 이 과정에서 비-설정 자음은 조화를 방해하지 않고 ‘투명한 요소’로 작용한다. Ts’amakko어, Ineseño Chumash어, 범어 등 여러 언어에서 이러한 조화 현상이 보고된 바 있다(Rose & Walker, 2011). 그리고 이러한 조화는 권설 조음 동작이 비-설정 자음이나 모음 구간에서도 유지될 수 있음을 시사한다. 실제로 Walker et al.(2008)의 조음 추적(articulography) 연구에서는 키냐르완다어 화자의 /m/과 같은 비-설정 자음 산출 시에도 설첨의 권설 조음 동작이 유지되는 현상이 확인되었다. 본고의 결과 역시 이와 유사한 양상을 보인다. 비-설정 자음이 유음 /l/의 권설음화를 방해하지 않았는데, 이는 비-설정 자음의 산출 중에도 권설 조음 동작이 지속될 수 있음을 시사한다. 다만, 이러한 조음 동작의 지속 여부는 향후 조음학적 연구를 통해 보다 직접적으로 검증할 필요가 있다.8
마지막으로 음절 수와 유음의 단어 내 위치에 따른 분석 결과를 살펴보도록 하겠다. 기준 수준인 단음절 어말 환경과 비교하였을 때, 다음절 어말 환경과 다음절 어중 환경에서는 CoG가 유의미하게 높게 나타났다(p<.01). 레이블링 과정에서 ‘잘, 발, 살’ 등의 단음절어에서 권설음화된 유음이 자주 출현하는 경향이 관찰되었는데, 통계 결과 역시 이러한 초기 관찰을 뒷받침하는 것으로 해석할 수 있다.
이러한 결과는 Crosby(2024)의 /l/의 권설음화에 영향을 미치는 핵심 조건은 어말 위치에 놓이는 것이라는 분석을 다르게 해석할 수 있는 여지를 제공한다. 즉, /l/의 권설음화에 영향을 미치는 핵심 조건은 어말 위치에 놓이는 것이 아니라, 단음절어의 어말 위치에 놓이는 것일 수 있다. 실제로 Crosby(2024)에서 분석한 대부분의 어말 /l/ 토큰은 ‘걸, 잘, 할, 헐’과 같은 단음절어의 어말에 위치해 있었으므로, 해당 연구에서 보고된 높은 권설음화율은 어말 위치 자체보다는 단음절어 어말이라는 음운론적 • 운율론적 구조에 기인한 것일 수 있다. 또한, 본 연구 자료에서 다음절어 내 어말 유음과 어중 유음 간에는 유의미한 차이가 관찰되지 않았다는 Tukey 사후 분석 결과(p=.839, 추정치=29.886)로도 이 해석은 뒷받침된다.
반면에 단음절 어말 환경과 유음 겹자음 환경 간에는 유의미한 차이가 관찰되지 않았다. 이러한 결과는 겹자음 환경의 유음이 어말 유음보다 F3 값이 낮다고 보고한 Crosby & Dalola(2021)의 연구와 일치하지만, 겹자음 유음이 어말 유음이나 /ㅎ/ 앞 유음보다 권설음으로 실현될 가능성이 낮다고 본 Crosby(2024)의 결과와는 상충된다. 이와 같은 차이는 본 연구에서는 휴지가 뒤따르는 어말 유음을 제외한 반면, Crosby(2024)에서는 이를 포함했다는 점, 그리고 두 연구 간 참가자 집단 구성과 과제 유형, 분석 방식이 다르다는 점에 기인한 것으로 보인다.
겹자음을 조음적으로는 하나의 연속된 동작으로 간주하면 유음 뒤에 모음이 오는 것으로 볼 수 있고, 이는 유음 뒤에 자음이 오는 어말이나 어중 환경과 구분된다. 후행 분절음이 모음인 경우에는 자음인 경우보다 혀끝의 위치나 움직임 등 조음적 조절이 더 자유롭다. 따라서 겹자음 환경에서 권설음화가 일어날 가능성이 높은 이유를 이러한 관점에서 설명할 수 있다. 또한 겹자음은 단자음보다 길이가 상당히 더 긴 경향이 있기 때문에, 앞선 모음(과 뒤따르는 자음)으로부터의 동시조음 영향이 단자음보다 훨씬 적어진다. 이 때문에 겹자음은 단일 자음보다 발음 길이가 길어 혀끝이 권설 목표 위치에 도달할 시간이 충분하므로, 조음상의 미달(undershoot)이 줄어들고 권설 조음이 더 완전하게 실현된다. 그 결과, 이러한 조음적 특성이 CoG 하강과 같은 음향적 단서로 겹자음에서 더 뚜렷하게 나타날 수 있다.
아울러 rawCoG 모델과 정규화된 CoG 모델을 비교해 보았을 때 정규화 여부는 통계적 결론에 큰 영향을 미치지 않는 것으로 나타났다. 이는 혼합효과 모델이 화자 간 변이를 무작위 절편을 통해 충분히 반영했기 때문으로 보인다. 따라서 본 연구는 2.3.1절에서 언급한 Dalola & Bridwell(2023)의 주장을 실증적으로 뒷받침하면서도, 정규화의 필요성이 분석 맥락에 따라 달라질 수 있음을 보여준다.
4. 결론
본 연구에서는 20대 한국어 화자 30명의 준자유발화를 분석하여, 발화 초 위치와 음절말 위치에서 나타나는 한국어 유음의 실현 양상을 밝혔다. 특히, 종성 유음이 권설성을 띠는 현상에 주목하여, 이 현상을 촉발하는 언어 외적, 내적 요인이 무엇인지 밝히고자 하였다.
먼저, 여성보다는 남성 화자가 종성 유음을 권설음화하여 발음하는 경향이 높은 것으로 나타났다. 또한, 통계적으로 유의하지는 않았으나 표준어를 사용하는 수도권 화자보다는 대구 방언을 사용하는 경북 화자에게서 종성 유음의 권설음화가 더 많이 관찰되었다. 그리고 성별과 제2외국어 능숙도 간에 상호 작용이 있을 가능성도 관찰되어, 권설음화된 유음의 변이형을 사회언어학적 관점에서 면밀히 검토할 필요성이 제기되었다.
다음으로, 종성 유음이 후설 모음 뒤에 놓이거나 비-설정 자음 앞에 놓일 때 권설음화되기 더 쉽다는 것을 밝혔다. 또한 종성 유음이 다음절일 때보다는 단음절 단어 내에 속할 때 권설음화되기 더 쉽다는 것도 보고하였다. 이러한 결과는 여러 언어 내적 요인이 유음의 권설음화에 영향을 미치고 있음을 보여주며, 운율 단위나 형태론적 구조 등 상위 수준의 영향도 존재할 수 있음을 시사한다.
비록 연구 결과에서 화자의 영어와 중국어 능숙도의 영향이 유의미하게 드러나지는 않았으나, 두 언어에 존재하는 권설 자음과 유사한 변이형이 한국어에서도 나타나고 있다는 사실은 언어 접촉의 결과일 가능성이 있다는 점에서 흥미롭다. 게다가 기존 한국어 자음 체계에 권설 자음이 존재하지 않는다는 점에서, 이러한 이질적인 조음을 일부 화자들이 자연스럽게 수행하고 있다는 점도 주목할 만하다. 연구를 진행하는 과정에서 권설음화된 유음을 빈번하게 사용하는 화자들에게 그러한 사실을 알려주었을 때 자신의 발음을 특별하게 인식하지 못하고 있는 것도 흥미로운 지점이었다. 한국어 유음에서 관찰되는 이와 같은 변이가 앞으로 어떤 방향으로 확산되거나 안정화될지에 대해서는 지속적인 관찰과 분석이 필요할 것이다.
덧붙여 외국어 능숙도의 효과가 통계적으로 확인되지 않은 이유는 연구 설계상의 한계 때문일 수 있다. 본 연구에서는 참가자의 외국어 능숙도를 모집 과정에서 엄격히 통제하지 않았으며, 자기 보고(self-report) 방식으로 수집하였다는 한계가 있다. 이로 인해서 한국어 유음의 권설음화와의 관련성을 따지는 데에 한계가 있었다. 따라서 후속 연구에서는 제2언어습득(SLA)이나 다언어학(Multilingualism)과 같은 분야에서 사용되는 시험 점수나 Bilingual Language Profile(Birdsong et al., 2012)과 같은 객관적인 언어 능력 평가를 병행하는 것이 바람직할 것이다. 또한 언어 배경에 따라 집단을 세분화하여 참가자를 모집할 필요가 있다. 이를 통해 한국어 유음에서 나타나는 변이가 실제로 언어 접촉의 결과인지를 보다 명확하게 규명할 수 있을 것이다.
마지막으로, 본 연구에서는 화자가 대본의 철자를 의식해 부자연스럽거나 과장된 조음을 하지 않도록 사진 설명 과제를 통해 자발적 발화를 수집하는 방식을 채택하였다. 그러나 자발적 발화 자료의 특성상 일부 환경에서는 충분한 토큰을 확보하기 어려웠다. 예컨대 ‘귤, 결말’과 같이 이중모음이 선행하는 환경이나 ‘삶, ‘읽기’와 같은 /ㄹ/계 겹받침 환경, 혹은 발화 계획 부족으로 인한 망설임 구간 등에서는 /ㄹ/의 권설성이 증가할 것으로 예상하였고 레이블링 과정에서 이를 확인하기도 하였으나, 이러한 조건을 체계적으로 분석하기에는 자료의 제약이 있었다. 향후 연구에서는 이러한 환경에서의 토큰도 균형 있게 수집할 수 있는 방법을 모색하여, 종성 유음의 권설음화 현상에 대한 이해를 다각적으로 확장해 나가고자 한다.