





1. Introduction
Over the past few decades, the South Gyeongsang dialect of Korean, spoken primarily in the southeastern part of the Korean peninsula, has undergone noticeable phonetic and phonological changes across generations in both segmental and suprasegmental properties (e.g., Lee, 2013). Traditionally characterized by a distinct pitch-accent system and unique segmental realizations relative to standard Seoul Korean, the dialect has been re-shaped similar to those of Seoul Korean, reflecting broader sociolinguistic pressures toward linguistic homogenization (e.g., Lee, 2008; Silva, 2011).
Acoustic studies have documented evidence of ongoing sound change in various phonetic domains of Gyeongsang Korean. For instance, younger speakers exhibit phonetically reduced pitch-accent contrasts (e.g., Lee & Jongman, 2015; Lee et al., 2016) and vowel realizations that approximate the Seoul system (e.g., Lee, 2024; Lee & Jongman, 2016). At the sub-phonemic level, similarly, generational differences in stop consonants show a gradual shift in cue weighting-from voice onset time (VOT) to fundamental frequency (F0)–as the primary cue distinguishing laryngeal categories (e.g., Lee, 2020; Lee & Jongman, 2019), mirroring the cue-weighting patterns of standard Seoul Korean. These findings collectively suggest that the Gyeongsang dialect is undergoing a systematic reorganization of phonetic cues rather than random variation.
More recent studies have extended this line of inquiry to examine whether such sound changes occur incrementally or abruptly, exploring pre-adult speakers (i.e., children and teenagers) to better capture generational trajectories. Despite this growing body of research, however, the fricative system of the regional dialect remains less explored, with little known about how fricative production patterns vary across generations, particularly among pre-adult younger speakers. Therefore, the present study investigates cross-generational variation in the fricatives of South Gyeongsang Korean, aiming to determine whether the ongoing sound change in this segmental category proceeds incrementally or abruptly. This question may be crucial because the nature of change–whether gradual and internally motivated or abrupt and externally induced–can reveal whether the observed variation stems from intrinsic phonetic evolution or from the influence of the prestige standard, Seoul Korean (e.g., Beckman et al., 2014; Labov, 2001).
Research on sound change in the South Gyeongsang dialect of Korean has provided substantial evidence of ongoing phonetic and phonological shifts across generations. Previous studies have shown that the dialect’s distinctive segmental and suprasegmental features have been increasingly similar toward those of standard Seoul Korean, presumably suggesting the external influence of the standard language to the regional variety (e.g., Lee, 2008; Lee, 2013; Lee, 2020; Lee & Jongman, 2016, 2019; Kang, 2022).
In the segmental features, the South Gyeongsang dialect of Korean differs in the vowel and consonant systems, and the sub-phonemic features of the three-way laryngeal contrast of stops are also different from those of Seoul Korean. Specifically, for vowels, while standard Seoul Korean has seven vowels (i.e., /i, e, a, Λ, o, u, ɨ/), South Gyeongsang Korean has known to have six vowels (i.e., /i, e, a, o, u, ɨ/). For consonants, traditional descriptions claim that Gyeongsang Korean lacks a fortis (/s*/) vs. non-fortis (/s/) contrast in alveolar fricatives, neutralizing /s/ and /s*/ into a single category (Sohn, 1999). Lee & Jongman (2016) examined the acoustic properties of the vowels and fricatives through dialectal and age comparisons. The researchers demonstrated that ongoing vowel change in the South Gyeongsang dialect is most evident in /Λ/–/ɨ/; younger speakers showed split of /Λ/ and /ɨ/, of which used to be merged for older Gyeongsang generations. As a result of this split, the vowel system of the regional dialect became to have seven vowels consistent with Seoul Korean. The findings of Lee & Jongman (2016) also challenged the neutralization of /s/ and /s*/ in Gyeongsang Korean, reporting spectral and temporal distinctions among younger speakers but near-neutralization among older speakers. Lee & Jongman (2016) observed that while /s/ and /s*/ was acoustically less distinct for older generations in their 60–70s, the contrast was more clearly separated from each other for younger generations in their 20s. Specifically, older Gyeongsang speakers showed less distinction in the center of gravity (CoG) and frication duration between the two fricatives, indicating neutralization. In contrast, younger speakers patterned more like Seoul speakers (i.e., higher CoG and shorter aspiration duration for the fortis /s’/), maintaining clear acoustic distinction for the contrast. These findings suggested that Gyeongsang fricatives are undergoing a generational sound change toward the Seoul pattern, mainly signaled by increased CoG differentiation and restructured durational cues. This finding provided strong evidence of an apparent-time sound change, where younger speakers’ productions align more closely with the phonetic norms of the standard dialect.
Focusing on the vowel change, Lee (2024) extended this line of research. Lee (2024) examined the same vowel contrasts across a broader range of age groups including children, teenagers, young adults, and elderly to determine whether such sound changes proceed incrementally or abruptly. The assumption was that externally motivated sound change-such as influence from the standard Seoul dialect-would result in abrupt, discontinuous shifts across generations, whereas internally motivated phonetic change driven by articulatory or perceptual pressures would manifest as gradual, incremental adjustments in acoustic realizations (Beckman et al., 2014). If vowel change is observed among the youngest child group around the age 7–8, it would indicate a gradual, internally driven phonetic shift emerging within the community. Conversely, if the change first appears among adolescents or young adults, it would suggest an abrupt, externally induced shift reflecting influence from the standard Seoul variety. In the results, Lee (2024) showed a discontinuous, rather than gradual, progression of change, with young adults–not adolescents–demonstrating the most innovative phonetic patterns in the /Λ/-/ɨ/ split. This discontinuity (or abrupt change) implies that vowel changes in the South Gyeongsang dialect are externally motivated, reflecting the influence of Seoul Korean, rather than internally driven phonetic evolution.
Generational differences were also observed at the sub–phonemic level of segments, specifically in the cue-weighting patterns of the three-way laryngeal contrast in voiceless stops (e.g., /t’, t, th/) (Lee & Jongman, 2019), indicating acoustic cue shift from VOT to F0 in the South Gyeongsang Korean as well as Seoul Korean. Building on this, a following study, Lee (2020) also examined whether these shifts in acoustic cue reliance progress incrementally across generations (children, teenagers, young adults, elderly) or occur as abrupt transitions, reflecting internal phonetic evolution versus external influence from the standard Seoul dialect. In Lee (2020), consistent with earlier findings, VOT distinction weakened steadily across generations, with younger speakers showing smaller VOT differences between aspirated and lenis stops, paralleling Seoul Korean’s ongoing neutralization pattern. However, the F0 contrast did not show consistent age-related divergence: while young adults exhibited somewhat larger F0 differences than the elderly, children often patterned like the elderly, suggesting incomplete adoption of the innovative F0 cue for the youngest child group. The analysis also revealed notable individual variation. In addition, the lack of correlation between VOT and F0 measures suggests that Gyeongsang Korean’s change may not be purely phonetically driven, but possibly influenced by external contact with Seoul Korean, where the sound change originated. In summary, Lee (2020) concludes that the Gyeongsang stop change is incremental rather than purely abrupt but follows a distinct trajectory. This reflects both regional variation in phonetic motivation and potential influence from the prestige dialect rather than uniform internal phonetic change.
Taken together, prior research highlights that Gyeongsang Korean is in the midst of an ongoing sound change that manifests differently across phonetic subsystems. Yet, the precise nature of this change-whether it occurs gradually or abruptly, and how it extends to fricatives-remains unclear. Addressing this gap, the present study investigates the spectral and temporal characteristics of fricatives across four age groups of Gyeongsang speakers to elucidate the mechanisms and directionality of sound change in this regional dialect.
Earlier work on stop consonants (Lee, 2020) and vowels (Lee, 2024) demonstrated that younger Gyeongsang speakers exhibit a reorganization of phonetic cues and phonological contrast, as younger speakers showed resemblance with those of standard Seoul Korean. Together, these studies indicate that Gyeongsang Korean is undergoing broad sound change toward the national standard, reflecting dialect leveling and cross-generational phonetic convergence. Based on the previous findings of sound change in the Gyeongsang dialect, the present study extends the investigation to the acoustic realization of the two-way distinction of the fricatives across generations from children to elderly.
Specifically, we test (i) whether the spectral CoG and frication/aspiration duration of the fricatives differ across four age groups (children, teenagers, young adults, elderly), (ii) whether such changes parallel the developmental trajectories observed in stops and vowels, and (iii) whether the observed sound change unfolds as an incremental, phonetically gradual progression or as an abrupt shift influenced by external contact with standard Seoul Korean. By including wide range of the age groups, the present study aims to capture the full generational continuum of Gyeongsang Korean and to clarify whether ongoing changes in fricative production reflect a unified, systemic sound change across segment types or a category-specific innovation confined to fricatives.
2. Methods
Participants were native speakers of the South Gyeongsang dialect of Korean (near Changwon-city and Pusan-city), representing four different age groups: children, teenagers, young adults, and elderly adults. The recording was newly conducted for the three non-elderly speaker groups, and the elderly data were drawn from the study by Lee & Jongman (2016; Journal of the International Phonetic Association), which examined the same dialect and comparable fricative stimuli. At the time of recording, the children consisted of 15 speakers aged 7 to 9 years {12 females [mean age=7.8 (SD=0.64)]}, all of whom were able to read Korean orthography. The teenage group included 15 speakers aged 14 to 15 years {15 females [mean age=14.53 (SD=0.52)]}, and the young adult group comprised seven participants {7 females [mean age=21.43 (SD=1.27)]}. The elderly group included eight speakers aged ranging from 59 and 75 years old {8 females [mean age=66.3 (SD=5.3)]}. All participants were born and raised in the South Gyeongsang region and had lived there for most of their lives. None of them reported any hearing, speech, or neurological disorders at the time of recording.
Recordings for the all collected data were conducted individually in a quiet room using a high-quality digital recorder (Marantz PMD 670) at a 44.1 kHz sampling rate and a Shure head-mounted microphone. All participants provided informed consent prior to participation, and parental consent was obtained for children. The study was carried out in accordance with institutional ethical standards of Kyungnam University for human subjects research.
The stimuli consisted of target words containing two disyllabic word-initial fricatives, specifically fortis (/s*/) and non-fortis (/s/), embedded in identical vowel contexts to control for coarticulation [fortis /s*al-i/ ‘rice-nom.’; non-fortis /sal-i/ ‘flesh-nom.’). Each target was produced twice in a carrier sentence (i.e., [idƷe ______ malhanda]) to maintain natural prosody and consistent speaking rate. Participants were instructed to read the sentences at a comfortable pace. All recordings were manually segmented, and then automatically labeled using Praat (Boersma & Weenink, 2023). The onset and offset of each fricative were identified by the presence and disappearance of high-frequency aperiodic energy in the spectrogram. Overall, a total of 180 tokens were obtained (2 words×2 repetitions×45 speakers) for the current study.
The present study measured the CoG, frication duration, and aspiration duration. The primary acoustic measure was the CoG of the fricative noise, representing the spectral mean frequency. To minimize transitional effects from adjacent sounds, CoG values were calculated over the mid-portion of the fricative. Specifically, CoG values were calculated over the central portion of the fricative, defined as the 25%–85% interval of the total duration. This slightly wider mid-interval (covering approximately 60% of the segment) follows established procedures in previous work on fricative spectra (e.g., Forrest et al., 1988), which recommend excluding only the initial and final transitional regions while retaining a sufficiently large stable portion of the frication noise for spectral averaging. CoG measured in Hertz was extracted using a Praat script developed by Christian DiCanio (2013, Haskins Laboratories & SUNY Buffalo) for calculating the first four spectral moments of fricative spectra. The script computes time-averaged discrete Fourier transforms (DFTs) across the fricative duration, following the procedure of Forrest et al. (1988). Several DFTs were obtained over the central portion of each fricative (corresponding to 25%–85% of the duration), and the resulting spectra were averaged to produce a representative spectral distribution. From this averaged spectrum, the CoG was calculated as the weighted mean of frequency by normalized amplitude. Prior to spectral analysis, signals were high-pass filtered at 300 Hz to remove low-frequency noise.
Additional temporal measures-frication duration and aspiration duration-were also obtained to ensure consistency across tokens. To determine frication and aspiration boundaries, frication duration was measured from the onset of aperiodic noise to the onset of aspiration, as seen in both waveform and spectrogram displays. Aspiration duration was measured from the onset of aspiration to the onset of voicing in the following vowel, which was identified by the appearance of the first formant (F1). The onset of aspiration was first identified in the spectrogram based on differences in the spectral energy distribution between frication and aspiration. To ensure reliable segmentation–particularly for the fortis fricative /s*/ where the frication–aspiration boundary can be less distinct–we applied a two-step boundary criterion following Lee & Jongman (2016). The boundary was first located based on changes in high-frequency energy in the spectrogram and then confirmed by comparing FFT spectra from 20-ms windows before and after the candidate point. Only tokens for which both criteria aligned were included in the analysis. The final onset value was defined as the point that satisfied both spectrographic and spectral criteria. All acoustic measurements were extracted in Praat (Boersma & Weenink, 2023) and exported for statistical analysis in R.
All statistical analyses were conducted in R (R Core Team, 2023) using the lme4 package (Bates et al., 2015). To examine generational differences in the acoustic realization of Korean fricatives, a series of linear mixed-effects regression models were fitted for three dependent variables: CoG, frication duration, and aspiration duration. Each model included AGE (children, teenagers, young adults, elderlyreference) and (fricative) TYPE (/s*/, /s/reference) as fixed factors, along with their interaction term, AGE×TYPE. Random intercepts for Speaker and Item were added to account for repeated measurements within individuals and lexical items. All models were estimated using maximum likelihood estimation with the bobyqa optimizer and an increased iteration limit to ensure convergence. Factor variables were coded as categorical predictors with treatment contrasts. Model residuals were examined visually to verify the assumptions of normality and homoscedasticity. Post-hoc pairwise comparisons were conducted using the emmeans package (Lenth, 2022) with Tukey adjustments for multiple comparisons. Statistical significance was set at p<.05. Degrees of freedom for t-tests were estimated using the Satterthwaite approximation implemented in the lmerTest package (Kuznetsova et al., 2017).
3. Results
In Figure 1, younger Gyeongsang speakers exhibit a clear acoustic separation between fortis and non-fortis fricatives, with higher CoG values for fortis /s*/, while elderly speakers show reduced differentiation, suggesting partial neutralization of the fricative contrast. A linear mixed-effects regression analysis revealed significant main effects of AGE and a marginal main effect of TYPE, as well as a significant AGE×TYPE interaction. The intercept, representing the elderly group’s non-fortis fricatives, had a mean CoG of 7,373 Hz. Compared to elderly speakers, children (β=−4,517 Hz), teenagers (β=−4,927 Hz), and young adults (β=−4,593 Hz) showed significantly lower CoG values for the non-fortis /s/, indicating a generational decrease in spectral mean frequency for the fricative category. The main effect of TYPE was marginally significant, with fortis fricatives showing higher CoG values than non-fortis fricatives (β=841 Hz). Notably, the AGE×TYPE interaction was highly significant; fortis vs. non-fortis contrasts were much larger for younger speakers. Specifically, compared to elderly speakers, fortis fricative was associated with significantly greater CoG differences among children (β=2,675 Hz), teenagers (β=3,465 Hz), and young adults (β=3,260 Hz). These results indicate that the spectral distinction between fortis and non-fortis fricatives is enhanced among younger speakers but reduced among the elderly, suggesting a cross-generational reorganization of acoustic cue weighting in the South Gyeongsang dialect.
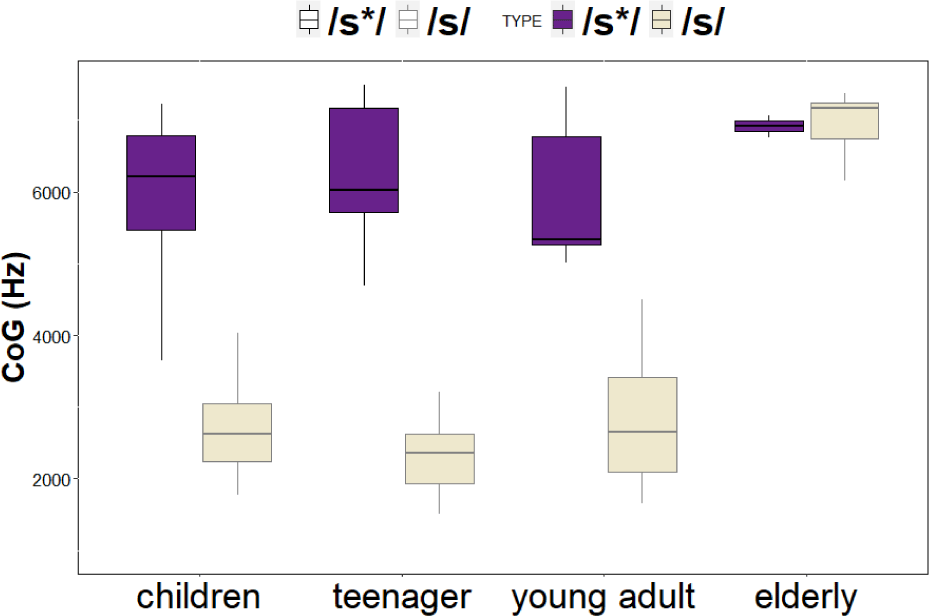
Importantly, the magnitude of the CoG difference between fortis and non-fortis fricatives varied systematically across age groups, being largest among teenagers (β=3,465 Hz), followed by young adults (β=3,260 Hz) and children (β=2,675 Hz), and smallest among elderly speakers. This pattern indicates that while younger Gyeongsang speakers exhibit an enhanced spectral distinction between the two fricative categories compared to elderly speakers, the magnitude of the difference does not incrementally increase from the youngest generation (i.e., children).
The enhanced CoG separation observed in younger Gyeongsang speakers therefore aligns with the Seoul pattern, suggesting a contact-induced shift toward the standard dialect. Adolescence is widely recognized as a period of increased linguistic plasticity and social realignment, and young adult females often lead sound change in Korean and other languages. This sociolinguistic profile explains why teenagers and young adults show the most innovative patterns in the present dataset. Although the children’s group shows relatively large CoG differences, their pattern remains the most conservative among the younger generations. Their contrast is smaller than that of teenagers and young adults, indicating that the Seoul-like enhancement has not yet fully emerged in child speech. Children’s intermediate pattern likely reflects a combination of developmental acoustic factors (e.g., generally higher spectral values in child speech) and early but incomplete exposure to Seoul-based input through schooling, media, and peer interactions (Table 1).
For the frication duration, younger speakers, particularly teenagers and young adults, exhibit greater durational contrast between the two fricative categories, whereas elderly speakers show reduced differentiation, indicating an age-related strengthening of the fortis vs. non-fortis distinction (see Figure 2). A linear mixed-effects regression model was conducted to examine the effects of AGE, TYPE and the interaction of the two factors on frication and aspiration duration. For the frication duration, the statistical analysis revealed a significant interaction between AGE×TYPE, indicating that the acoustic distinction between the fortis and non-fortis fricatives varied across generations. Specifically, teenagers (β=0.058) and young adults (β=0.056) produced significantly longer frication durations for fortis /s*/ than for non-fortis /s/, whereas this distinction was less pronounced in children (β=0.036) and elderly speakers (reference group). No significant main effects were found for either AGE or TYPE independently.
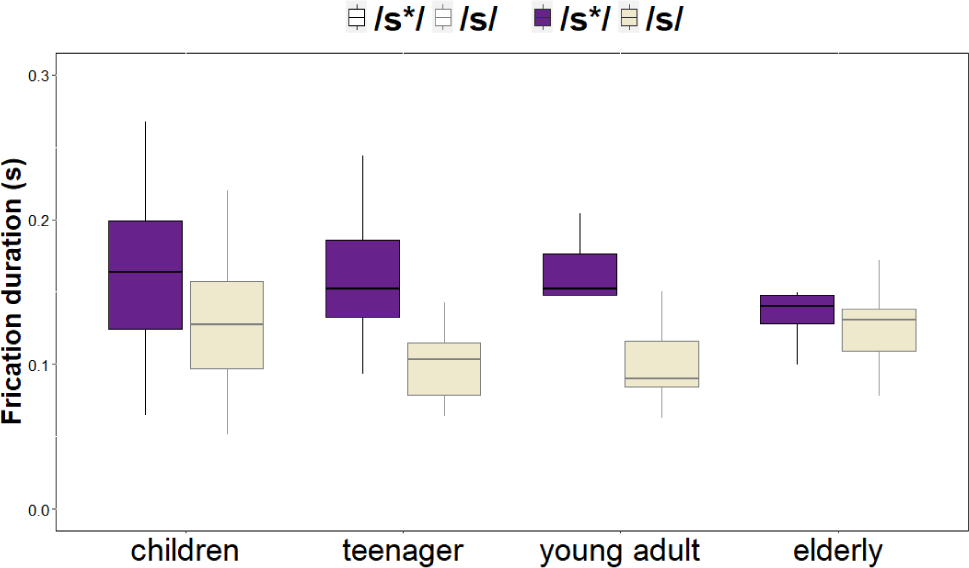
All younger groups (children, teenagers, young adults) have larger durational differences than the elderly group. However, the teenager (β=0.058) and young adult (β=0.056) groups have comparable magnitudes, while children (β=0.036) show a somewhat smaller (and only marginally significant) effect. The durational difference between fortis and non-fortis fricatives was smallest for elderly speakers and increased among younger generations. The largest contrasts were observed in teenagers and young adults, with children showing an intermediate pattern. These results suggest that the durational contrast between fortis and non-fortis fricatives strengthens among younger generations, particularly from adolescence onward, supporting the interpretation of an ongoing sound change toward the Seoul pattern (Table 2).
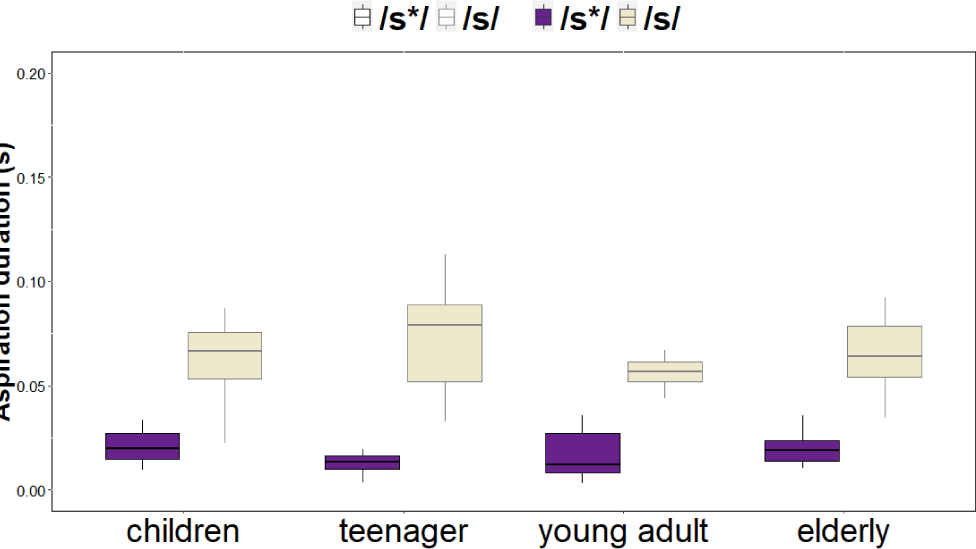
For the aspiration duration, overall, the fortis /s*/ show shorter aspiration durations than non-fortis /s/ across all age groups as seen in Figure 3. A linear mixed-effects regression model showed a significant main effect of TYPE (β=–0.044), indicating that fortis /s*/ had significantly shorter aspiration duration than non-fortis /s/ across all age groups. No significant main effects were found for AGE groups, nor were there significant AGE×TYPE interactions (all p>.08), suggesting that the durational contrast between the two fricatives was consistently maintained across generations. These results indicate that unlike the CoG and frication duration, aspiration duration remains a stable cue distinguishing fortis and non-fortis fricatives in South Gyeongsang Korean across generations (Table 3).
4. Discussion and conclusion
The present study examined the acoustic realization of Gyeongsang Korean fricatives across generations to determine whether ongoing sound change proceeds incrementally or abruptly for the obstruent category. The results revealed robust generational differences in both spectral (CoG) and temporal (frication duration) dimensions, while aspiration duration remained stable across age groups. Younger speakers, particularly teenagers and young adults, exhibited enhanced fortis vs. non-fortis contrasts, whereas elderly speakers showed partial neutralization. This pattern suggests that both spectral and temporal cues are being restructured among younger generations, signaling an ongoing reorganization of the Gyeongsang fricative system.
Importantly, the developmental trajectory observed in CoG and frication duration indicates that the change in the Gyeongsang fricative system is not strictly incremental. While the elderly group shows reduced contrast (i.e., most conservative) and the teenage and young adult groups exhibit strengthened distinctions (i.e., most innovative), the youngest group (children) does not show a proportionally greater enhancement. This discontinuity across the age trajectory suggests that the change may occur abruptly during adolescence, coinciding with increased exposure to the Seoul dialect through schooling, media, and peer interaction. Thus, the fricative change appears to reflect externally induced, socially mediated sound change rather than an internally motivated phonetic drift.
The observed pattern parallels findings from previous studies on stops (Lee, 2020) and vowels (Lee, 2024), where changes in cue weighting and vowel quality emerged abruptly rather than gradually. The consistent emergence of abrupt changes across segmental categories suggests that Gyeongsang Korean is undergoing a systemic reorganization of phonetic cues rather than independent, category-specific adjustments. Such systemic restructuring supports the idea that the Gyeongsang dialect’s sound system is converging toward that of Seoul Korean through dialect leveling and cross-generational realignment. The enhanced fortis vs. non-fortis fricative distinction among younger speakers, particularly teenagers and young adults, likely reflects broader sociophonetic influences. Adolescence is a critical period for social identity formation, and alignment with the prestige standard dialect often intensifies during this stage. Consequently, the results underscore the role of social identity and language contact in shaping sound change. The Gyeongsang case illustrates how externally driven sound change can propagate across segmental domains, reinforcing linguistic homogenization while weakening regional distinctiveness.
The alignment of CoG and frication duration patterns suggests a coordinated reweighting of spectral and temporal cues in fricative production. This reflects a shift in perceptual salience, where speakers increasingly rely on cues consistent with the standard dialect. Such cue reorganization has been reported in other cases of dialect convergence (Beckman et al., 2014), supporting the view that sound change involves not only phonological restructuring but also dynamic re–weighting of multiple acoustic dimensions. The present findings on fricatives in South Gyeongsang Korean parallel recent evidence from stop production and perception in second dialect acquisition (Lee et al., 2024), collectively pointing to a systemic reorganization of phonetic cues under dialect contact. Lee et al. (2024) demonstrated that Gyeongsang speakers who had relocated to Seoul showed perceptual cue weighting that closely resembled Seoul norms–greater reliance on F0 over VOT–while their production patterns remained partially conservative. This perceptual–production asymmetry reflects an intermediate stage of dialect adaptation, where perceptual realignment precedes full articulatory restructuring. In the current study, a similar pattern emerges in the fricative system: younger Gyeongsang speakers exhibit Seoul–like acoustic patterns, showing enhanced spectral and durational contrasts between fortis and non-fortis fricatives, while elderly speakers display near-neutralization. This suggests that younger speakers have internalized Seoul–like phonetic targets, consistent with contact–induced reorganization across segment types.
Taken together, these results provide converging evidence that the ongoing sound change in Gyeongsang Korean is not limited to a single phonetic category but represents a broad, systemic restructuring of acoustic cue hierarchies, reflecting externally motivated. The inclusion of children provides crucial insight into the timing of this sound change: their intermediate pattern suggests that Seoul–like fricative distinctions may be emerging early in the developmental trajectory but have not yet fully stabilized, indicating an ongoing, community–level restructuring process rather than adult second–dialect learning. Thus, the present findings complement Lee et al. (2024) by showing that the phonetic convergence toward the Seoul standard observed in adult dialect learners is mirrored in the speech of younger Gyeongsang natives, revealing a continuum from second dialect acquisition to first–dialect sound change.
Taken together, the results provide strong evidence that Gyeongsang Korean fricatives are undergoing socially motivated, abrupt sound change, paralleling similar patterns in stops and vowels. This supports the broader hypothesis that the Gyeongsang dialect is participating in a systemic, externally induced reorganization of phonetic cues, driven by contact with the prestige Seoul dialect and reinforced through generational transmission and social identity alignment. Future research should incorporate a broader set of fricative stimuli–across different following vowels, prosodic contexts, and lexical environments–to strengthen the generalizability of the current findings.