





1. Introduction
Speakers’ proficiency in the source language plays an important role in how loanwords are pronounced and perceived, often yielding distinct realizations of the same loanwords (Best et al., 2007; Paradis & LaCharité, 2008, 2012; Wang, 2023). In particular, bilingual and monolingual speakers often differ in their production of loanwords (Kadenge & Mudzingwa, 2012; LaCharité & Paradis, 2005; Zellou, 2011). For instance, Kadenge & Mudzingwa (2012) argue that when adapting English loanwords into chiShona, chiShona–English bilinguals sometimes produce segments that are not part of the chiShona sound inventory. Since chiShona lacks the consonant /l/, chiShona monolinguals typically substitute /r/ for /l/ in English loanwords. In contrast, chiShona–English bilinguals may retain /l/. This pattern suggests that many chiShona–English bilinguals draw on English phonology when incorporating English loanwords into chiShona. Also, Zellou (2011) reports that Moroccan Arabic–French bilinguals produce /u/ differently in native Moroccan Arabic words and in French loanwords: /u/ in French loanwords shows significantly higher F1 values than /u/ in native words, indicating a lower (more /ɔ/-like) realization. This pattern can be interpreted as reflecting influence from the French source vowel quality (i.e., /ɔ/), even though the loanword vowel is phonologically adapted as /u/ in Moroccan Arabic.
These results may be explained in terms of LaCharité & Paradis’s (2005) account. They argue that bilingual speakers do not map borrowed forms by simply copying the input’s surface phonetics. Rather, they first interpret the source-language sounds through L2 phonological categories, and the adaptation process applies to this category-based mental representation instead of to the raw phonetic string itself. Since loanwords are generally expected to conform to the phonological constraints of the recipient language (L1), the output may preserve some information from the perceived L2 categories while being reshaped to fit the L1 system. Importantly, they separate adaptation from importation: in adaptation, detailed phonetic mimicry is not central, whereas importation refers to cases where speakers deliberately try to retain finer phonetic properties of the source language. They further suggest that such importation is more likely in communities with greater bilingual experience. Overall, following LaCharité & Paradis (2005), bilingual loanword realizations can be viewed as the product of (i) how the source signal is categorized in L2 and (ii) pressure to satisfy L1 phonological well-formedness. Zellou’s (2011) pattern can be interpreted in light of LaCharité & Paradis’s (2005) account. When the source vowel is perceived as French /ɔ/, Moroccan Arabic–French bilinguals may first categorize the signal as the L2 phonological category /ɔ/ and then adapt it to the nearest licit L1 category (/u/) in accordance with the established mapping (/ɔ/ → /u/). The systematic F1 raising of loanword /u/ relative to native /u/ suggests that the output is not a straightforward copy of the L1 /u/, but retains an /ɔ/-like height trace of the perceived L2 category. In this sense, the results are consistent with adaptation targeting a category-based representation, rather than deliberate phonetic importation.
Building on earlier work (Kadenge & Mudzingwa, 2012; LaCharité & Paradis, 2005; Zellou, 2011), it is possible that Korean–English bilinguals avoid using epenthetic /ɨ/ when adapting English loanwords into Korean in order to preserve the original English pronunciation. In English loanwords, epenthetic /ɨ/ is typically inserted to break up illicit consonant clusters and to avoid illicit codas. Since these illicit structures are allowed in English, Korean–English bilinguals may be less likely to use epenthetic /ɨ/ in English loanwords.
According to LaCharité & Paradis (2005), loanword adaptation does not involve simply copying the surface phonetics of the input; rather, it targets a category-based representation formed by interpreting the source signal through L2 phonological categories. Since Zellou (2011) likewise reports that loanword vowels can be phonologically adapted to a licit L1 category while still retaining trace phonetic properties of the source category, epenthetic /ɨ/ may similarly satisfy Korean phonotactic constraints while being partly shaped by English cues, yielding a more English-like quality. Thus, in cases where epenthetic /ɨ/ is produced, it may be realized with an English-like quality rather than as Korean /ɨ/.
In English, reduced vowels in non-final unstressed contexts (e.g., roses [ɹoʊzɨz]) may be transcribed as [ɨ]. Flemming & Johnson (2007) argue, based on acoustic evidence from American English, that reduced vowels are not well captured by a uniform schwa [ə] category. Instead, they propose a systematic difference between word-final schwa and reduced vowels in other unstressed positions: word-final schwa patterns as a relatively mid-central vowel, whereas reduced vowels elsewhere are generally higher and can be transcribed with [ɨ]. On this view, the apparent contrast need not be attributed to an across-the-board phonemic opposition between schwa and [ɨ]; rather, it can be understood as arising from a positional distinction together with the interaction of reduction and morphological structure. Flemming & Johnson (2007) reported an F1 of approximately 400 Hz for [ɨ], which is comparable to the F1 of Korean lexical /ɨ/. In contrast, F2 of English [ɨ] is much higher—approximately 1,900–2,000 Hz (Flemming & Johnson, 2007)—than the roughly 1500 Hz average reported for Korean lexical /ɨ/. This F2 difference indicates that the two languages’ [ɨ] vowels have different phonetic targets. In Korean, /ɨ/ is described phonetically as a central vowel with slight tongue retraction (Lee & Ramsey, 2011; Umeda, 2022) but is analyzed phonologically as a back vowel. By comparison, English [ɨ] is generally treated as a central vowel without an accompanying back-vowel classification. On this basis, Korean lexical /ɨ/ may exhibit a lower F2 than English [ɨ]. Accordingly, the F2 of epenthetic /ɨ/ may vary across groups, such that Korean–English bilinguals and Korean monolinguals may differ in their F2 realization of epenthetic /ɨ/.
Next, gender has been shown to influence vowel duration, with male speakers often producing shorter vowels than female speakers due to physiological (Simpson & Ericsdotter, 2003) and sociolinguistic factors (Bradlow et al., 1997; Picheny et al., 1985, 1986). Accordingly, the present study examines whether the duration of epenthetic /ɨ/ differs by gender in both native Korean speakers and Korean-English bilinguals.
In adapting English loanwords into Korean, vowel epenthesis is an important repair strategy. However, epenthetic vowels have not been examined extensively across diverse linguistic contexts, and epenthetic /ɨ/ in bilingual speech production has rarely been investigated. Moreover, even when bilingual effects are considered, prior work has often focused on categorical outcomes (epenthesis vs. non-epenthesis). The present study addresses this gap by distinguishing between (i) the categorical selection of /ɨ/ epenthesis and (ii) the acoustic realization of epenthetic /ɨ/ (F1, F2, and duration), thereby seeking to clarify how bilingual experience affects the selection of a repair strategy and its phonetic implementation. Specifically, it tests whether Korean–English bilinguals apply epenthesis less frequently than monolinguals and whether, when epenthesis occurs, epenthetic /ɨ/ produced by bilinguals shows a more English-like vowel quality.
2. Methods
A total of twenty participants took part in the study (M age=30.95 years). The sample consisted of 10 Korean monolingual speakers (5 females, 5 males) and 10 Korean–English bilinguals (5 females, 5 males).
All Korean monolingual speakers were born and raised in Seoul, Korea, and had never lived in an English-speaking country. Monolinguals are strictly defined as people who speak only a single language. In practice, however, the concept is often applied more broadly. Escudero et al. (2014) define monolinguals as individuals who (i) use their first language as the primary means of everyday communication, (ii) have not spent more than one month in an environment where another language is routinely spoken, and (iii) if they have had any second-language instruction, it was limited and largely restricted to classroom-based learning. Under this definition, L2 contact is typically confined to instruction from teachers who speak with an L1 accent and tends to focus on reading and grammar rather than communicative use. In such cases, researchers often refer to these speakers as “functional monolinguals.” On this basis, the 10 Korean monolingual speakers in this study are classified as functional monolinguals. Of the Korean-English bilinguals, seven were born and raised in the USA, while three were born in Korea, but moved to the USA before the age of four.
Both groups completed the Language Background Questionnaire adapted from Park & Ziegler (2014), which is based on the Common European Framework of Reference for Languages (CEFR). Based on the questionnaire responses, the Korean monolingual speakers reported using Korean about 98% of the time on average, whereas the Korean–English bilinguals reported using English about 75% of the time on average in academic, professional, and social settings in their daily lives.
Consonant place of articulation is known to systematically influence F2 of a following vowel (Cooper et al., 1952; Kim & Kochetov, 2011), with lower F2 typically observed after labials and higher F2 after coronals. To control for this effect, the present study examined epenthetic /ɨ/ following alveolar, bilabial, and velar consonants, with 12 items in each category.
Prior research shows that vowel duration varies systematically with position: vowels are often longer at the ends of words (van Santen, 1992; White et al., 2020; Windmann et al., 2015). White et al. (2020) suggest that listeners can use such word-final lengthening to anticipate upcoming word boundaries. Word-final lengthening has also been linked to pre-pausal effects, whereby vowels tend to lengthen before a pause (Duanmu, 1996; Klatt, 1976; O’Shaughnessy, 1981). Based on these observations, the present study compared epenthetic /ɨ/ in non-word-final syllables with epenthetic /ɨ/ in word-final syllables. In addition, vowel durations are typically longer in open than in closed syllables (Choi & Jun, 1998; Monsen, 1974; Oh, 2016). For instance, Oh (2016) analyzed vowel duration across Korean syllable shapes (V, CV, VC, and CVC) and showed a clear ranking: vowels were longest in V syllables, shorter in CV, shorter still in VC, and shortest in CVC. This ordering has been attributed to compensatory shortening, a process in which vowels become shorter as more within-syllable segments are present, while still maintaining their phonetic quality (Fowler, 1981; Klatt, 1976; Lindblom & Rapp, 1973). Therefore, the stimuli included epenthetic /ɨ/ in both syllable types. In closed syllables, epenthetic /ɨ/ most often appeared between a consonant and /l/. Although epenthesis can also occur within the /sm/ cluster, this sequence is rare in English loanwords in Korean; therefore, in this study, closed-syllable epenthesis was primarily examined in C+/l/ contexts. Based on vowel position and syllable structure, the stimuli were distributed as follows: (i) 12 CV items in non-word-final position, (ii) 12 CV items in word-final position, and (iii) 12 CVC items in word-final position. In total, the stimulus set comprised 36 items.
All English stimuli (see Appendix) were embedded in the Korean carrier sentence ‘우리는 각각 X 발음을 하고 있습니다 [ulinɨn kɑkkɑk X pɑlɨmɨl hɑko isɨmnitɑ] ‘We are individually pronouncing X.’ Each target stimulus (X) was bracketed by the stop consonants /k/ and /p/—/k/ before and /p/ after—to aid segmentation and acoustic extraction (Magen & Blumstein, 1993). To maintain a Korean sentence context, the stimuli were shown in English orthography but were inserted into a Korean carrier sentence.
Korean forced alignment (Yoon, 2025) was applied to the manually transcribed speech data, and the resulting alignments were imported into Praat (Boersma & Weenink, 2024) as TextGrid files. Word- and phoneme-level boundaries were then manually verified to reduce potential errors from automatic segmentation. For the target vowel, onset was defined as the point at which F2 emerged, and offset was defined as the point at which F2 ended or a clear spectrographic/waveform discontinuity appeared due to the following consonant. Formant values were extracted at the vowel’s temporal midpoint.
F1 and F2 values were not normalized; vowel duration was instead log-transformed to reduce right-skewness and stabilize variance. As the analyses focus on group differences in the epenthetic vowel /ɨ/ rather than absolute vowel-space comparisons, speaker-related variability was modeled statistically.
Recordings of the Korean monolingual group were conducted in quiet locations in Seoul, Korea (e.g., a library study room and a seminar room), whereas the Korean–English bilinguals were recorded in a sound-attenuated booth at the Linguistics Laboratory at the University of Georgia, USA.
All productions were recorded using a Marantz digital recorder and a Shure headworn dynamic microphone. After completing three practice trials, participants read each carrier sentence three times at a normal Korean speaking rate from PowerPoint slides displayed on a computer screen. They then proceeded to the main production task targeting epenthetic /ɨ/. The stimuli listed in Appendix were presented in a randomized order, and a total of 2,160 tokens were collected from 20 participants.
3. Results
The presence vs. absence of epenthesis was determined by manual inspection of the waveform and spectrogram at the target site (i.e., immediately after the final consonant). Tokens were coded as showing epenthesis when a vocalic interval could be identified that exhibited (i) periodic voicing and (ii) a clear formant structure with measurable F1 and F2. Tokens were coded as epenthesis absent when no such vocalic interval could be established—i.e., when the post-consonantal portion contained only consonantal release/aspiration noise or brief transitions without sustained periodicity and formant patterning.
10 Korean monolingual speakers produced all 1,080 tokens, but seven tokens were not recorded clearly and were therefore excluded from the dataset. Thus, a total of 1,073 tokens were analyzed, and all were produced with epenthetic /ɨ/. In contrast, Korean–English bilingual speakers produced 113 tokens without vowel epenthesis out of 1,078 tokens; two tokens were excluded due to an unclear recording. These non-epenthesized tokens were produced by six bilingual speakers, yielding a non-epenthesis rate of 10.48%.
To determine whether this difference reflects a reliable group-level effect, a Bayesian mixed-effects logistic regression model was used. Since the monolingual group showed no variability (100% epenthesis), frequentist logistic regression may suffer from (quasi-)complete separation, yielding unstable or inflated estimates. A Bayesian approach with weakly informative priors regularizes the model and provides more stable effect estimates and credible intervals under separation. Specifically, the model was fit with Group (bilingual vs. monolingual) as a fixed effect and random intercepts for Speaker and Word. The model showed a reliable reduction in the probability of /ɨ/ epenthesis among Korean–English bilingual speakers compared to Korean monolingual speakers. The posterior distribution of the group effect indicated that the posterior probability of a reduction in epenthesis in bilingual speech exceeded 95%, and the 95% credible interval for the Group effect did not include zero.
Including syllable environment (non-final CV, final CV, and final CVC) as a fixed effect could allow for a clearer examination of whether non-epenthesis occurs more frequently in specific structural environments. However, the present study was designed to focus on overall group differences, and syllable environment was balanced at the level of experimental design; therefore, it was not considered for inclusion in the final models.
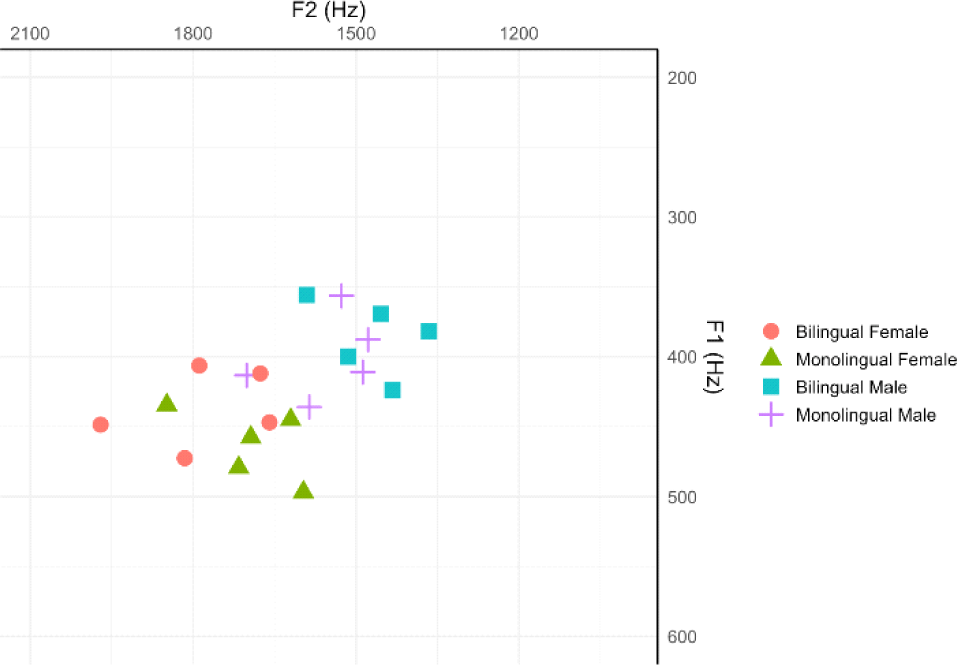
A total of 2,160 tokens were elicited, as 20 participants each read 36 stimuli three times. Of these, 113 tokens showed no epenthesis and were therefore excluded from the analysis. In addition, seven tokens produced by monolingual speakers and two produced by bilingual speakers were excluded from the statistical analysis due to unclear pronunciation. Thus, 2,038 tokens were included in the statistical analysis. The mean F1 and F2 values of epenthetic /ɨ/ produced by native and bilingual speakers are shown in Figure 1 and Table 1.
| Female | Male | |||
|---|---|---|---|---|
| F1 | F2 | F1 | F2 | |
| Bilingual | 437.28 (27.71) | 1,782.02 (135.38) | 386.16 (24.97) | 1,453.90 (113.65) |
| Monolingual | 462.65 (25.35) | 1,695.15 (99.01) | 400.92 (30.14) | 1,539.64 (100.27) |
For F1 and F2, separate linear mixed-effects regression models were fit in R (R Core Team, 2025) using the lmer() function from the lme4 package. The fixed-effects structure was determined via likelihood-ratio tests based on ANOVA comparisons of nested models, starting from a full model that included gender (female, male), place of articulation (coronal, dorsal, labial), and language group (bilingual, monolingual). The models included random intercepts for Speaker and Word, with no random slopes. Categorical predictors were treatment-coded (reference levels: dorsal, male, monolingual). Fixed-effect estimates from the best-fitting models are reported in Table 2.
In Table 2, there were no significant differences in either F1 or F2 between monolingual and bilingual speakers (F1: p=.172; F2: p=.084.). In contrast, gender exerted a significant influence on both formant measures, with female speakers exhibiting higher F1 and F2 values than male speakers (F1: p=.004; F2: p<.001). In addition, place of articulation significantly affected F2, such that F2 values were higher following coronal consonants (p<.001) and lower following labial consonants (p=.027).
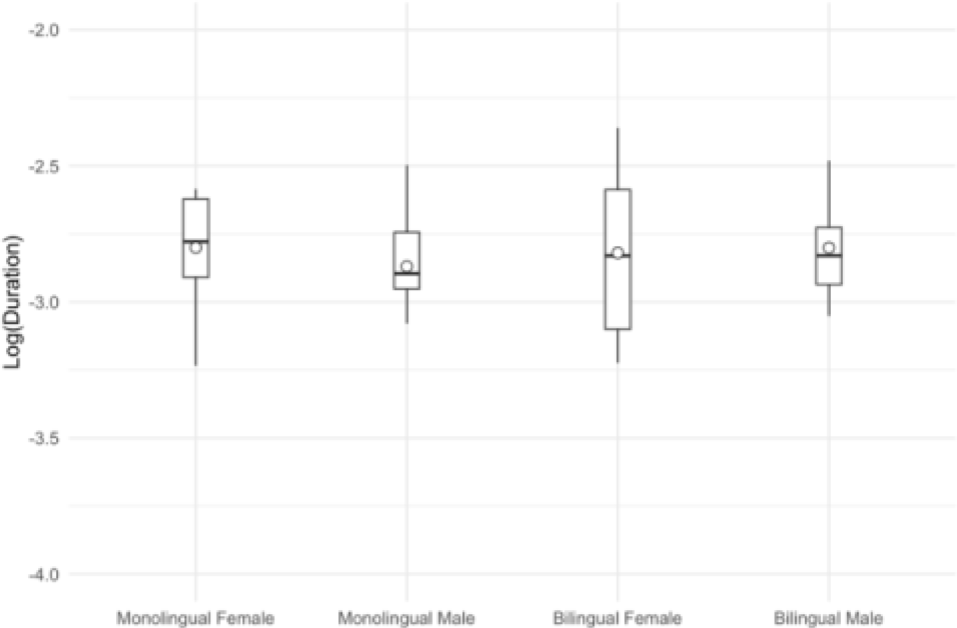
Next, vowel durations were measured to investigate whether durational differences existed between the language groups. Figure 2 and Table 3 present the mean vowel durations, and Table 4 reports the statistical results for log-transformed vowel duration across the predictors.
| Female | Male | |
|---|---|---|
| Bilingual | 0.0624 (0.0201) | 0.0619 (0.0129) |
| Monolingual | 0.0619 (0.0117) | 0.0571 (0.0133) |
In Table 4, a linear mixed-effects regression model was fit in R (R Core Team, 2025) using the lmer() function from the lme4 package. The fixed-effects structure included gender (female, male), vowel position (non-word-final, word-final), syllable structure (closed, open), and language group (bilingual, monolingual). The model included random intercepts for Speaker and Word, with no random slopes. Categorical predictors were treatment-coded with prespecified reference levels (closed syllables, male, monolingual, non-word-final position). The results showed that the duration is significantly different by the syllable position (p=.039) and by the structure syllable (p=.045) but other effects are not significant (gender: p=.069; language group: p=.096).
Figure 2 and Table 3 showed that bilingual female speakers appeared to exhibit the largest standard deviation in vowel duration among the four groups. To assess whether this difference reflected a reliable difference in variability, Levene’s test was conducted. The results indicated that the variance in vowel duration did not differ significantly across the four groups (p=.092). Pairwise Levene’s tests likewise showed no significant differences in variance between any two groups (all ps≥.176). Together, these results suggest that vowel duration displayed comparable variability across groups and that no group exhibited unusually high dispersion.
4. Discussion and Conclusion
Korean–English bilingual speakers were significantly more likely than Korean monolinguals to produce English loanwords without epenthetic /ɨ/. This group difference can be interpreted as reflecting L2 English influence on bilinguals’ Korean speech. Comparable patterns have been reported in other contact settings. For instance, English loanwords in chiShona are handled differently by chiShona monolinguals and chiShona–English bilinguals, particularly when the source word contains complex consonant clusters (Kadenge & Mudzingwa, 2012). Since chiShona does not permit onset consonant clusters, monolingual speakers typically employ vowel epenthesis to break up such clusters. In contrast, bilingual speakers often avoid this repair, producing clusters with minimal modification (e.g., English protein: monolingual [pùróténì] vs. bilingual [próténì]). This pattern accords with the view that speakers with greater familiarity with the source language (e.g., bilinguals) are more likely to preserve aspects of the source form in loanword production (LaCharité & Paradis, 2005; Paradis & LaCharité, 2008, 2012; Ryu et al., 2020). For example, Paradis & LaCharité (2012) argue that loanword outcomes are not fully captured by adaptation alone, where adaptation refers to the systematic replacement of foreign segments with recipient-language categories to satisfy native phonological constraints. They therefore distinguish adaptation from importation. Importation is defined as non-adaptation that arises from speakers’ intentional phonetic approximation of source-language sounds—an attempt to reproduce a foreign segment “as such,” rather than converting it into a native phoneme. Paradis & LaCharité (2012) further argue that social-external factors, especially the intensity of contact with the source language, promote importation. That is, the stronger the contact with the source language, as is often the case for bilingual speakers, the greater the number of importations observed in loanword production. This perspective provides a useful framework for interpreting the findings of the present study. In Korean, epenthetic /ɨ/ is a canonical repair strategy that enforces native phonotactics, and Korean monolingual speakers in the present dataset applied this strategy categorically, producing /ɨ/ in every token. By contrast, Korean–English bilingual speakers showed a reduced rate of /ɨ/ epenthesis. In light of Paradis and LaCharité’s account, this bilingual pattern can be interpreted as reflecting weaker pressure to fully nativize source forms in production; that is, bilingual speakers may show a greater tendency to preserve aspects of the source form or to avoid certain repairs because they have stronger access to the source language and are more oriented toward source-like pronunciation.
In this study, the bilinguals showed a 10.48% non-epenthesis rate, which appears fairly low in light of their high proficiency and early exposure to English. One plausible explanation is language mode (Grosjean, 2001; Weinreich, 1966). Language mode refers to the extent to which a bilingual’s two languages (and the associated processing mechanisms) are activated at a given moment. According to Grosjean (2001), language mode is shaped by multiple factors, including the interlocutor (e.g., the interlocutor’s proficiency and attitudes toward code-mixing), the situational context (e.g., setting, the presence of monolinguals, and formality), the message/topic (e.g., lexical demands and the need for mixed-language use), and the purpose and design of the activity, including experimental factors such as the stimuli and the task. Depending on these factors, bilinguals may enter situations in which one language becomes relatively less activated than the other. Since the present experiment was conducted in a Korean-dominant context (e.g., a Korean carrier sentence), Korean–English bilinguals were likely operating in a Korean-dominant mode, making them more likely to adhere more strongly to Korean phonological constraints (e.g., /ɨ/ epenthesis to resolve consonant clusters). Thus, despite their high English proficiency and early exposure, embedding English target words in Korean carrier sentences may have strengthened the dominance of Korean in the present study.
Next, the acoustic realization of epenthetic /ɨ/ was analyzed in Korean–English bilinguals and Korean monolinguals, and no group difference was found. These results can be interpreted in terms of how stably the vowel category is established in both the source and recipient languages. When bilinguals draw on source-language sounds in loanword production, those segments are often represented as clear phonemic categories in both languages, allowing bilingual speakers to retain source-category information even when speaking the recipient language. In fact, prior studies reporting such replacements have consistently involved segments that are phonemic in both the source and recipient languages. In the present study, however, it is difficult to assume that English provides a stable, independent phonemic counterpart to Korean /ɨ/ for all Korean–English bilinguals. For example, Flemming & Johnson (2007) argue that English schwa and [ɨ] need not be treated as phonemically contrastive. Rather, the apparent difference can be understood as arising from a positional distinction, together with the interaction of vowel reduction and morphological structure. On this view, it is not necessary to posit /ə/ and /ɨ/ as independent phonemes in English. The authors further report that [ɨ] vowels are observed in some American English speakers, but note that the distribution of such [ɨ] vowels does not align neatly with a consistent set of regional dialects. In light of these observations, it is possible that English [ɨ] does not serve as a stable phonetic target for the bilingual speakers in the present study. If Korean–English bilingual speakers do not possess a stable English [ɨ], then when they choose to epenthesize, they are more likely to use the epenthetic vowel from the Korean phonological system—namely, the Korean phoneme /ɨ/—rather than to import a source-language vowel category. As a result, the acoustic realization of the epenthetic vowel may not differ reliably from that produced by Korean monolingual speakers. Thus, future research should first establish a baseline by testing whether bilingual speakers actually produce [ɨ] vowels in English. It should then focus on bilinguals who show evidence of using this [ɨ] in their English productions and examine whether they also use this English [ɨ] in loanword production.
Next, in this study, the results showed that gender does not have any effect on vowel durations. However, gender generally affects vowel duration: male speakers produce shorter vowel durations than female speakers (Holt et al., 2015; Jacewicz & Fox, 2015; Simpson & Ericsdotter, 2003). One explanation attributes this pattern to physiological differences: because male speakers typically have larger and longer vocal tracts, they may increase articulatory speed to reach comparable targets, resulting in shorter vowel durations (Simpson & Ericsdotter, 2003). Another explanation is based on speaking style: female speakers may adopt clearer speech more often, which is associated with more distinct target realization and longer segmental durations (Albuquerque et al., 2021; Bradlow et al., 1997; Picheny et al., 1985, 1986). However, the results of the present study indicated that gender did not have a significant overall effect on vowel duration. To examine whether the gender pattern was consistent across the two groups, Tukey’s pairwise comparisons were conducted based on the best-fitting mixed-effects model, separately by group. The comparisons showed that for epenthetic /ɨ/ in monolingual speech, female speakers produced significantly longer durations than male speakers (p=.011). In bilingual speech, however, no significant gender difference was observed (p=.094). One plausible account is that the mixed-language format of the stimuli induced speech-rate slowing in the bilingual group. The materials consisted of Korean carrier sentences written in Hangul with target English items presented in Roman letters, which may have increased processing demands by requiring bilingual speakers to produce the targets in a Korean manner while simultaneously navigating mixed orthographic cues within a single sentence. As a result, bilingual speakers may have adopted a generally more careful and slower reading style. Since slower speaking rates are well known to lengthen vowel durations, such slowing may have contributed to attenuating gender-based differences in /ɨ/ duration in bilingual speech. Although the present task does not constitute code-switching in a strict sense, related evidence suggests that temporal expansion, including longer vowel durations, can emerge in bilingual production contexts where cues from two languages are concurrently present (Elias et al., 2017; Muldner et al., 2019; Olson, 2012). For example, Muldner et al. (2019) report that vowels in code-switched words are significantly longer than those in comparable non-switched contexts, interpreting this pattern as a signal of hyper-articulation or increased planning demands.
Given that these accounts implicate temporal expansion, often manifested as slower speech, speech rate was quantified to assess whether overall slowing could account for the attenuated gender effect in bilingual speech. In the present study, speech rate was operationalized as syllables per second, calculated by dividing the number of syllables in the carrier sentence by the sentence’s total onset-to-offset duration, with intervening pauses included (Laver, 1994; Son, 2017). Using this metric, bilingual speakers averaged about 5.22 syllables per second, whereas native Korean speakers averaged about 5.89 syllables per second. There was a statistically significant group difference in overall speaking rate (p<.05), which is consistent with the possibility that the mixed-orthography format, in which Korean carrier sentences were presented in Hangul and English target items were presented in Roman letters within the same sentence, increased processing demands and encouraged a more careful reading style. However, this overall slowing did not translate into a uniform increase in the duration of epenthetic /ɨ/ at the group level. This pattern suggests that the mixed-orthography format may not have yielded a consistent group-level shift in /ɨ/ duration across speakers, but instead may have increased inter-speaker variability by amplifying differences in production strategies, such as pausing, planning, and reading style. For example, some speakers may have produced longer /ɨ/ durations under a more careful production style, whereas others may have maintained relatively stable durations, resulting in no consistent group-level shift. Consequently, /ɨ/ duration could remain comparable between the monolingual and bilingual groups, while the increased variability within the bilingual group may have made gender-related differences in duration less consistently detectable. Future analyses will re-examine /ɨ/ duration while controlling for overall speaking rate. This approach may also help determine whether the non-significant gender effect in bilingual speech reflects a genuine absence of gender-related differences or whether such differences may have been masked by task-induced slowing and/or greater inter-speaker variability.
Next, the possibility cannot be ruled out that the realization of an epenthetic vowel is shaped by coarticulatory effects from surrounding lexical vowels. However, because the present stimulus set was not designed to include vowel-context factors, this factor could not be examined directly. Future research should therefore systematically test vowel-environment effects using a design that controls the surrounding vowel contexts.
In this study, six bilingual speakers did not show any /ɨ/ epenthesis, whereas four bilingual speakers did. The six speakers with vowel omission reported higher English use on average (84%) than the four speakers who produced epenthetic vowels (69%), suggesting that this pattern may reflect greater English use and/or reduced Korean use. However, Korean use and language dominance were not measured directly in this study. Thus, an exploratory follow-up analysis was conducted to examine the relationship between English use and omission frequency. The results suggested a tendency for higher English use to be associated with a lower probability of /ɨ/ epenthesis [posterior P(β_EnglishUse<0)=0.88]. However, considering the limited sample size and the lack of a direct measure of Korean use/dominance, the inference that greater Korean use would lead to more /ɨ/ epenthesis should be interpreted as suggestive rather than conclusive. Future research should collect independent measures of Korean and English use and dominance to test this relationship more directly.
The bilingual group included both US-born individuals and speakers who moved to the United States before age four. However, no differences were observed between these two subgroups in either formant values or vowel omission rates. The absence of clear subgroup differences may reflect the fact that both groups were exposed to an English-dominant environment in early childhood and therefore share broadly similar developmental trajectories as early bilinguals. In addition, individual variation in loanword production—such as /ɨ/ epenthesis—may be more closely tied to cumulative Korean language use and domain-specific patterns of use (home/peer/community), as well as literacy experience, than to birthplace or age of arrival per se. However, given the limited sample size, these interpretations should be evaluated in future work with larger samples and more fine-grained background measures.
In this study, the target stimuli were presented in English orthography within a Korean carrier sentence. If the stimuli had instead been presented in Hangul with /ɨ/ explicitly represented, this format could strongly cue the Korean repair strategy of /ɨ/ epenthesis, making it difficult to address the current research question, namely, whether bilingual speakers and native Korean speakers show different patterns. However, a production study using Hangul prompts and asking bilingual speakers to read them could provide complementary evidence about /ɨ/ realization. This remains an important question for future work.
Although the participants were recorded in different locations, the same acoustic measurement procedure was applied across all data, and tokens with unclear formant structure or excessive noise were excluded. Nevertheless, because the data were collected under different recording conditions, the influence of recording conditions cannot be fully disentangled statistically.
Overall, the present study shows that Korean–English bilingualism influences English loanword production primarily by increasing the likelihood of omitting epenthetic /ɨ/, compared to monolingual speech. However, when epenthesis occurred, no statistically significant acoustic differences in /ɨ/ were observed between bilingual and monolingual speakers.